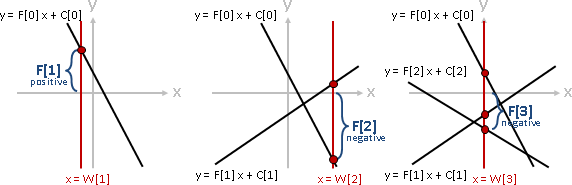概論
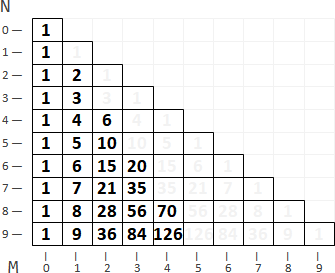
最佳解位置,恰好已排序。
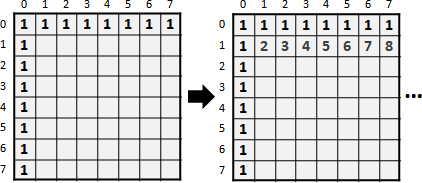
每個問題,依照大小排序。最佳解位置,恰好也依照大小排序。
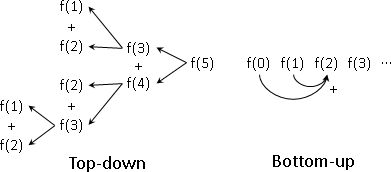
一個問題不必枚舉所有候選解。參考先前問題的最佳解位置,一個問題只需要枚舉一部分的候選解。
中文網路稱作「决策单调性」。
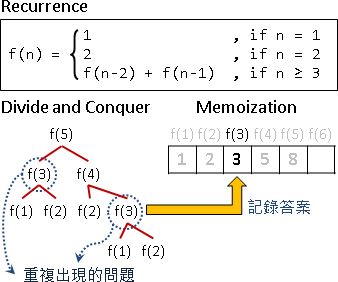
Knuth–Yao speedup
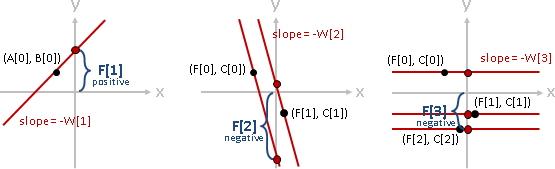
F[i,j] = min { F[i,k] + F[k+1,j] + C[i,j] }
k=i⋯j-1
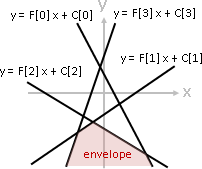
(1) C[i,j] is Monge*: C[a,b] + C[a+1,b+1] ≤ C[a,b+1] + C[a+1,b]
(2) C[i,j] is sorted: C[a,b] ≤ C[a,b+1] and C[a,b] ≤ C[a-1,b]
(C[a,b] ≤ C[c,d] when [a,b] ⊆ [c,d])
(=>) F[i,j] is Monge*
(=>) P[i,j] is sorted: P[a,b] ≤ P[a,b+1] and P[a,b] ≤ P[a+1,b]
(P[a,b-1] ≤ P[a,b] ≤ P[a+1,b])
*non-negative upper-trianglar concave Monge
(1) C[i,j] is Monge: ↖ + ↘ ≤ ↗ + ↙ (concave)
(2) C[i,j] is sorted: ← ≤ → and ↓ ≤ ↑ (toward ↗)
(←↙↓ ≤ →↗↑)
(=>) F[i,j] is Monge
(=>) P[i,j] is sorted: ← ≤ → and ↑ ≤ ↓ (toward ↘)
(↖ ≤ ↗ ≤ ↘)
這種形式的recurrence,直接計算是O(N³)。此處介紹更快的演算法,降為O(N²)。
附帶成本C[i,j]既是Monge matrix又是sorted matrix,導致最佳解數值F[i,j]是Monge matrix,也導致最佳解位置P[i,j]是sorted matrix。【待補證明】
一個問題的最佳解位置,範圍限縮。原本是a ≤ P[a,b] ≤ b,現在是P[a,b-1] ≤ P[a,b] ≤ P[a+1,b]。Monge matrix夾住左邊界,sorted matrix夾住右邊界。候選解變少,時間複雜度變低。
過程當中使用了Monge matrix,導致中文網路也將此手法稱作「四边形不等式优化」。
英文網路稱作「Knuth's optimization」。
範例:optimal binary search tree
N筆資料,欲建立成一棵「binary search tree」。並且預測了每筆資料的搜尋次數。
請問binary search tree是什麼形狀,才能讓拜訪到的節點數量最少呢?也就是說,每個節點的「深度」乘上「搜尋次數」,總和要最小。
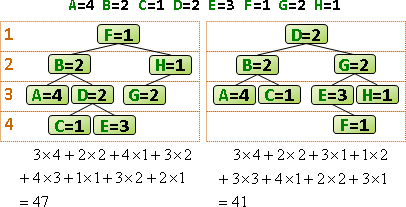
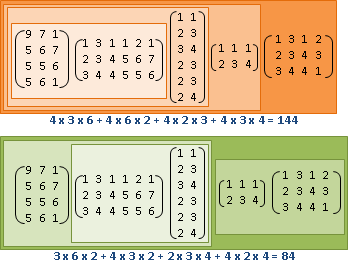
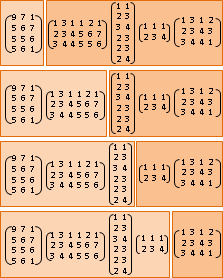
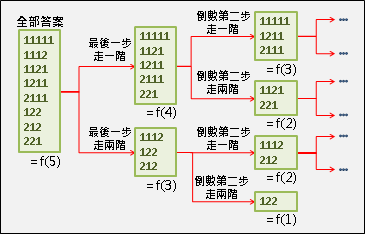
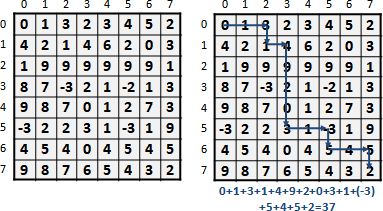
遞迴公式類似於matrix chain multiplication,都是記錄區間。窮舉樹根,分割成左右兩棵子樹遞迴下去。問題總共O(N²)個,一個問題要窮舉O(N)種分割點,時間複雜度O(N³)。
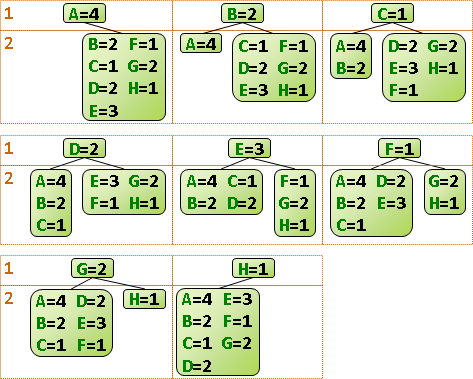
由於第二層迴圈的c(i,k)維持定值,不會影響最大值的判斷結果,所以可以挪到迴圈外面,減少加法次數,減少執行時間。
總共O(N²)個問題,每個問題必須窮舉O(N)個分割點,時間複雜度O(N³)。
到這裡都和普通的dynamic programming沒兩樣。接下來要更進一步。
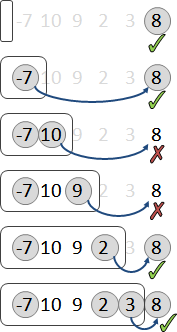
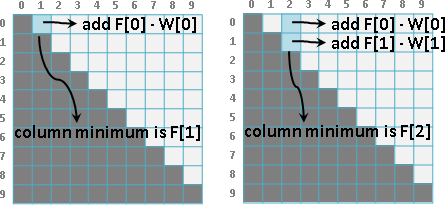
每次計算一個問題,總是得窮舉所有的分割點。然而有些分割點顯然是錯誤的,尤其是靠近區間邊界的那些分割點,實在不太可能將兩棵子樹分割的夠均勻、令總和最小。
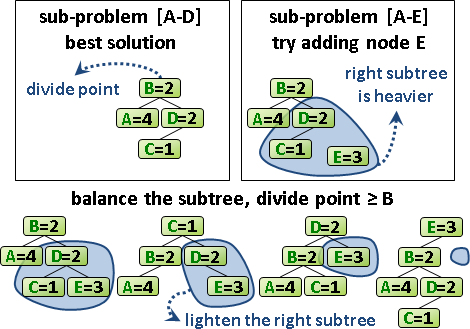
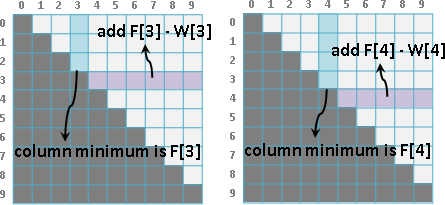
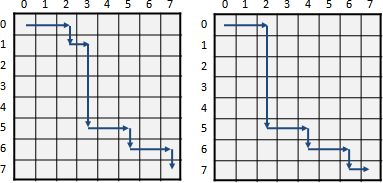
相近的問題,其分割點也很相近。問題[a,b],嘗試從從右端拿掉一筆資料,成為問題[a,b-1]。問題[a,b]、問題[a,b-1]的分割點很相近。
為了讓左右子樹均勻,[a,b]的分割點一定要大於等於[a,b-1]的分割點,才能降低總和。小於[a,b-1]的分割點,沒有窮舉的必要,樹只會越不平衡、總和只會更大不會更小!
問題[a+1,b]的情況也十分類似,不再贅述。
也就是說,問題[a,b]的分割點,必定位於更小的問題[a,b-1]和[a+1,b]的分割點之間。計算一個問題,大可不必窮舉所有的分割點。
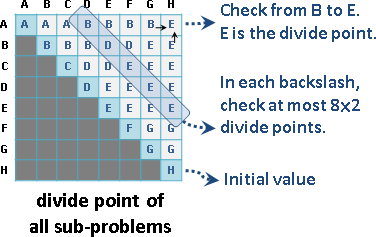
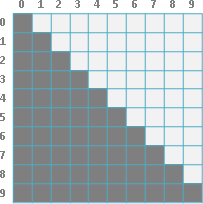
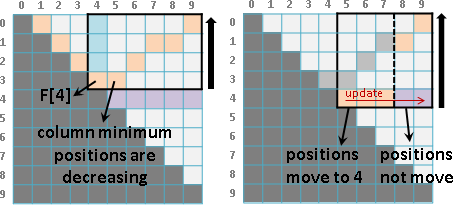
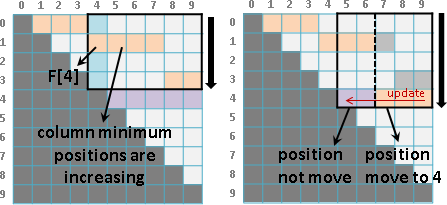
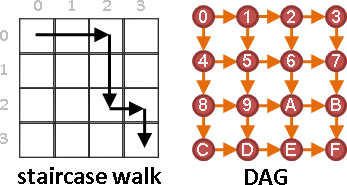
觀察分割點表格,[a,b-1]是左方格子,[a+1,b]是下方格子。要計算一個分割點,窮舉範圍就是左方格子的值到下方格子的值。也就是說每一個格子都會大於等於左方格子、小於等於下方格子。
每一條左上右下斜線,左上最小值是0,右下最大值是N-1,每一條斜線最多窮舉2N = O(N)個分割點。
除了初始值之外,總共N-1條斜線,需要窮舉的分割點總共O(N²)個,所以時間複雜度降為O(N²)。
UVa 10304 10003 12057 12809
Hu–Shing speedup
F[i,j] = min { F[i,k] + F[k+1,j] + C[i,j,k] }
k=i⋯j-1
這種形式的recurrence,直接計算是O(N³)。此處介紹更快的演算法,降為O(NlogN)。
範例:matrix chain multiplication
我沒有研究。論文上百頁,我不想讀。
【尚無正式名稱】
F[i][j] = min { F[i-1][k-1] + C[k,j] }
k=1⋯j
(1) C[i,j] is Monge: C[a,b] + C[a+1,b+1] ≤ C[a,b+1] + C[a+1,b]
(=>) P[i][j] is row-sorted: P[i,j] ≤ P[i,j+1]
(2) C(|i-j|) is convex
(=>) F[i][j] is row-sorted
(=>) F[i-1][k-1] + C[k,j] is unimodal
這種形式的recurrence,直接計算是O(NM²)。此處介紹更快的演算法,降為O(NM)。
一、附帶成本C[i,j]恰是Monge matrix,導致最佳解位置P[i][j]是row-sorted matrix。【尚待確認】
一個問題的最佳解位置,範圍限縮。Monge matrix夾住左邊界。因為沒有夾住右邊界,所以用二分法處理右邊界。O(NMlogM)。
英文網路稱作「divide-and-conquer optimization」。
二、附帶成本C(|i - j|)恰是convex function,再導致最佳解數值F[i][j]是row-sorted matrix,也導致候選解數值F[i][k] + C[k,j]是unimodal function。【尚待確認】
一個問題的最佳解位置,範圍限縮。Monge matrix夾住左邊界。convex function夾住右邊界。O(NM)。
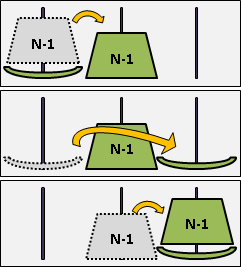
三、不管C[i,j]是什麼了。先前章節「convex hull加速」實施N次。W[n] = 1,彷彿「deque加速」。O(NM)。
範例:1D p-center problem
詳見「p-center problem」。
參考文獻
[envelope/convex hull] [unimodal function]
using geometric techniques to improve dynamic programming algorithms for the economic lot-sizing problem and extensions
[Monge matrix]
dynamic programming with convexity, concavity and sparsity
an almost linear time algorithm for generalized matrix searching
[Knuth–Yao speedup]
optimum binary search trees
efficient dynamic programming using quadrangle inequalities
[Hu–Shing speedup]
computation of matrix chain products, part I, part II
revisiting “computation of matrix chain products”






 🡲
🡲