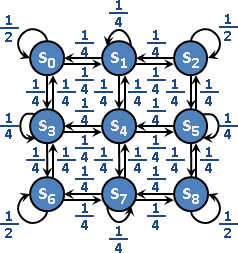
state space graph
「狀態空間圖」。所有狀態互相轉移,形成了圖論的有向圖。狀態就是點,轉移就是邊,轉移成本就是邊的權重。
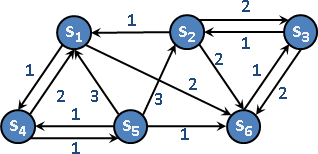
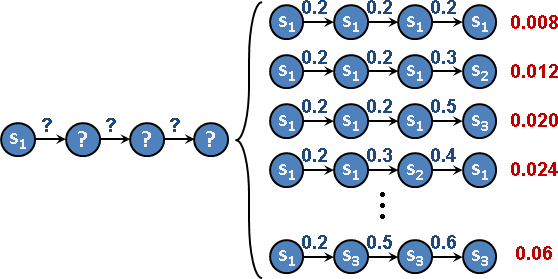
state space tree
「狀態空間樹」。選定一個狀態,衍生各式各樣的狀態,形成一棵樹。狀態空間樹無窮無盡。狀態可能重複出現、四處散布。

用途:從「起始狀態」到其他狀態,求得轉移過程。
用途:從「起始狀態」到「目標狀態」,求得轉移過程。
搜尋順序
如何迅速找到目標狀態呢?
狀態空間樹無窮無盡,只好一邊建立、一邊搜尋。乍看離目標狀態比較近的狀態,優先搜尋。
如何衡量目標狀態的遠近呢?
已經搜尋的狀態,累計轉移成本;尚未搜尋的狀態,估計轉移成本。成本較低的狀態,優先搜尋。
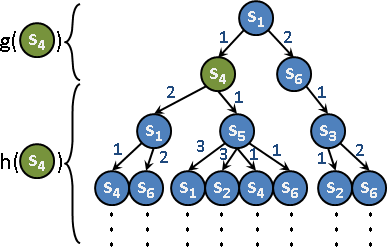
cost function g(x):起始狀態到當前狀態x,真正的轉移成本。c(s⤳x)。
heuristic function h(x):當前狀態x到目標狀態,預估的轉移成本。c̃(x⤳t)。
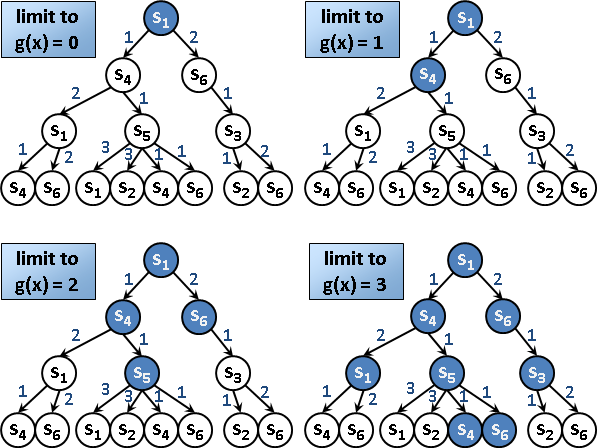
g(x)由小到大搜尋:首次遇到的目標狀態,就是g(x)最小的目標狀態。
h(x)由小到大搜尋:首次遇到的目標狀態,不一定就是g(x)最小的目標狀態。因為h(x)不準確。
g(x)+h(x)由小到大搜尋:首次遇到的目標狀態,不一定就是g(x)最小的目標狀態。因為h(x)不準確。
admissible heuristic:h(x)小於等於真正的轉移成本。h(x) ≤ c(x⤳t)。
consistent heuristic:h(x)滿足單調性。h(x) ≤ c(x⤳y) + h(y)。
g(x)+h(x)由小到大搜尋,並且h(x)小於等於真正的轉移成本(不高估):首次遇到的目標狀態,就是g(x)最小的目標狀態。當h(x)預估精準,得以迅速走往目標狀態,不會四處閒逛。
g(x)+h(x)由小到大搜尋,並且h(x)滿足單調性:首次遇到的各種狀態,都是g(x)最小的狀態。也就是說,每種狀態只需拜訪一次。時間複雜度O(NDK),其中狀態數量為N,分枝數量為D,轉移需時O(K)。
UVa 260 298 314 321 429 571 589 704 985 10047 10603 10653 10682 10923 10103 10704 10067
UVa 529 851 10073 10422 10798 11163 11376 10314
搜尋演算法
圖論的遍歷演算法,進行改良,建立暨搜尋狀態空間樹。
breadth-first search(BFS)
忽視g(x)、h(x),優先建立離起始狀態最近的狀態。
適用於轉移成本是固定值。
depth-first search(DFS)
忽視g(x)、h(x),優先建立離起始狀態最遠的狀態。
適用於轉移成本是固定值。
depth-limited search(DLS)/ 過去稱作 depth-first branch-and-bound(DFBnB)
DFS的改良版本。限制建立的深度(或成本),當深度(或成本)太深就不再往下分枝衍生。
iterative deepening DFS(IDS)
DLS的改良版本。反覆使用DLS,並逐次放寬深度限制。
若每次放寬的量極少時,可達到類似於BFS的功能。
uniform-cost search(UCS)
g(x)由小到大建立。以BFS實作。
iterative lengthening search(ILS)
g(x)由小到大建立。以IDS實作,逐次放寬g(x)的限制。
若每次放寬的量極少時,可達到類似UCS的功能。
best-first search
h(x)由小到大建立。以BFS實作。
recursive best-first search(RBFS)
h(x)由小到大建立。以IDS實作,逐次放寬h(x)的限制。
若每次放寬的量極少時,可達到類似best-first search的功能。
A* search(A*)
g(x)+h(x)由小到大建立。以BFS實作。
iterative deepening A* search(IDA*)
g(x)+h(x)由小到大建立。以IDS實作,逐次放寬g(x)+h(x)的限制。
若每次放寬的量極少時,可達到類似A*的功能。
memory-bounded A* search(MA*) / simplified memory-bounded A* search(SMA*)
限制記憶體用量的A*。當queue全滿時,就從中刪除g(x)+h(x)最大的狀態。
名稱天花亂墜,令人眼花撩亂。其實最關鍵的地方,在於搜尋順序、搜尋演算法的差別。
搜尋順序:g(x)、h(x)、g(x)+h(x)
搜尋演算法:BFS、IDS
搜尋順序,採用g(x)或者g(x)+h(x),以正確求得最佳成本。
搜尋演算法,BFS系列,效率較差;IDS系列,效率較好。
假設狀態空間樹剛好是一棵二元樹,而目標狀態位於第N層。BFS搜尋的狀態數目是(1+2+4+8+...+2ᴺ),IDS搜尋的狀態數目是1 + (1+2) + (1+2+4) + ... + (1+2+4+8+...+2ᴺ),大約是前者的兩倍。如果狀態空間樹是K元樹,則大約是前者的K倍。
儘管BFS搜尋的狀態數目比起IDS少了許多倍,然而BFS必須維護priority queue,還得indexing,因此BFS的執行時間通常比起IDS長上許多,而且記憶體用量也大上許多。
IDS逐步放寬g(x)或者g(x)+h(x)的限制,不必比較成本大小。這使得IDS不需要priority queue。
搜尋策略
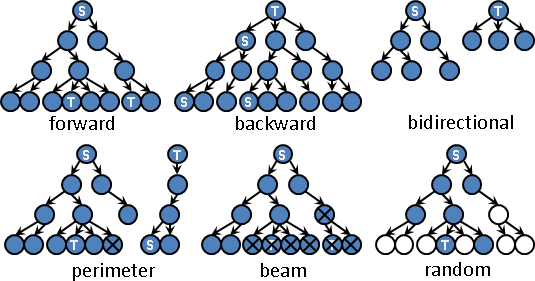
forward search:正向搜尋。起始狀態建立狀態空間樹,從中搜尋目標狀態。
backward search:反向搜尋。目標狀態建立狀態空間樹,從中搜尋起始狀態。
bidirectional search:雙向搜尋。起始狀態、目標狀態分別建立狀態空間樹,搜尋共同狀態。實作時,通常是輪流衍生。狀態空間樹輪流增加一層,直到兩邊出現共同狀態。
perimeter search:周界搜尋。起始狀態建立狀態空間樹,儲存所有狀態,直到記憶體幾乎用光。然後目標狀態建立狀態空間樹,直到出現儲存過的狀態。實作時,通常起始狀態採用BFS,目標狀態採用DFS、IDS、IDA*等節省記憶體的搜尋演算法。
beam search:柱狀搜尋。限制狀態空間樹每一層的狀態數目。當某一層抵達上限後,該層後來產生的狀態皆捨棄。
random search:隨機搜尋。隨機決定衍生哪些狀態。
heuristic search:啟發搜尋。按照經驗法則,決定衍生哪些狀態。例如台灣的交通網,西部比東部密集。從基隆到屏東,首先去台北,而不是去宜蘭──根據交通網密度,台北可能更快到達屏東。
ICPC 5098
搜尋技巧
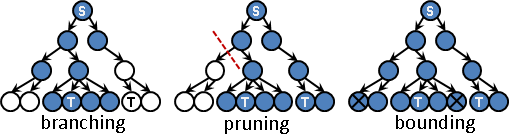
branching:視情況衍生分枝。逐漸增加成本下限,逼近正確答案;一旦超過成本上限,立即停止分枝。
pruning:參照問題本身的特殊限制,裁剪狀態空間樹,避開冗餘子樹。好處是減少搜尋時間。
bounding:搜尋時,隨時檢查成本。成本太壞,就不再往深處搜尋;成本足夠好,也不必往深處搜尋。好處是減少搜尋時間。
tie-breaking:搜尋時,當g(x)或者g(x)+h(x)平手,則比較h(x),優先搜尋h(x)較小的狀態,以便提早抵達目標狀態。
memoization:記錄所有遭遇到的狀態,避免狀態空間樹重複衍生相同狀態。當記憶體不足時,也可以只記錄一部分的狀態。
indexing:狀態編號,方便memoization。當記憶體不足時,indexing可以改為hashing。
UVa 233 10536 10941 690 ICPC 6010
應用:pathfinding
即時戰略遊戲,用滑鼠點選角色的目的地,角色自動繞過障礙物,找到最短路徑。