排序資料結構: search tree系列
排序資料結構
置放大量數字,並且進行排序的資料結構。可以隨時新增數字、隨時刪除數字。這樣的資料結構,目前沒有正式學術名稱。
binary search tree
「二元搜尋樹」。原理是divide-and-conquer method,樹根居中,左子樹較小或相等,右子樹較大,然後遞迴分割下去。
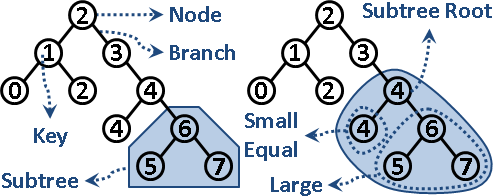
最小節點:從樹根開始往左小孩走到底。最大節點:從樹根開始往右小孩走到底。時間複雜度等同於二元搜尋樹的高度。
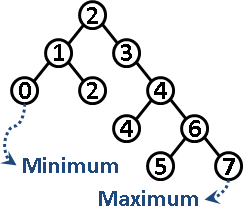
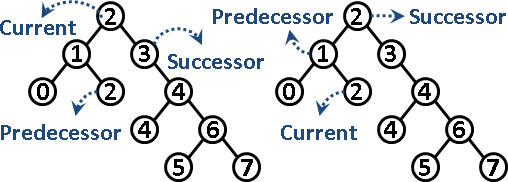
次小節點:先往左小孩走一步、再往右小孩走到底。如果一開始沒有左小孩,就往右上父親走到底,再往左上父親走一步就可以了。次大節點:方法類似。時間複雜度等同於二元搜尋樹的高度。
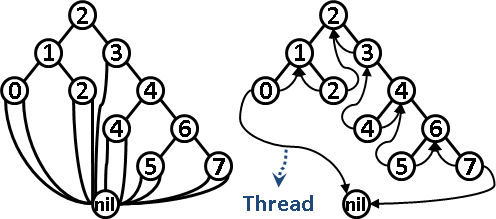
樹葉可以額外建立線索(thread),左小孩連往次小節點,右小孩連往次大節點,如此就能迅速地依照次序走訪節點。建立線索不影響時間複雜度與空間複雜度。實作僅需迴圈、毋需遞迴。
搜尋數字:從樹根開始走往左小孩或右小孩,直至目標。
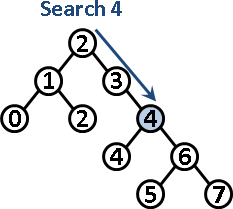
插入數字:搜尋直至樹葉。接著新增左小孩或右小孩。
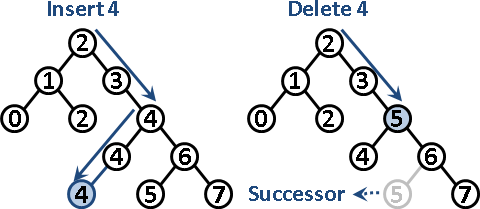
刪除數字:搜尋直至目標。接著分為三類情況。沒有小孩:直接刪除節點。一個小孩:小孩連往父親,然後刪除節點。兩個小孩:次大節點取代目標節點。因為次大節點沒有左小孩,所以刪除次大節點只有兩類情況,於是到此為止不再遞迴。
搜尋、插入、刪除的時間複雜度等同於二元搜尋樹的高度。
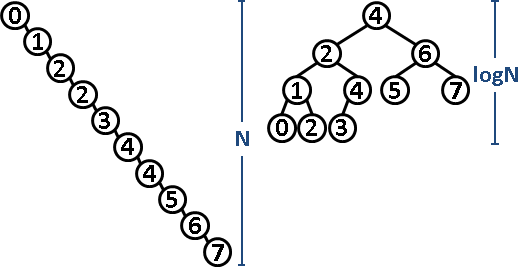
數字動態增減,二元搜尋樹的高度亦隨之變動,最差是O(N),最佳是O(logN)。所有節點連成一線的時候是最差的,所有節點形成perfect binary tree是最佳的。
空間複雜度等同於節點數目,空間複雜度O(N)。
自平衡二元搜尋樹(self-balancing binary search tree)
每當數字動態增減,則即時調整每個節點的位置,即時調整每棵子樹的高度,讓整棵二元搜尋樹的高度維持是O(logN),讓各項操作維持是O(logN)。
稍後介紹的AVL tree、red–black tree、splay tree,都是自平衡二元搜尋樹。
最佳二元搜尋樹(optimum binary search tree)
如果數字不會動態增減,則依照每個節點被搜尋到的次數(頻率),使用dynamic programming求得結構最佳的二元搜尋樹,藉此減少搜尋時間。建立時間為O(N²)。
UVa 10304
擴充二元搜尋樹(augmented binary search tree)
二元搜尋樹的每個節點,可以擴充資訊,例如子樹的高度、節點總數、數字總和、數字最大值、數字最小值、……。
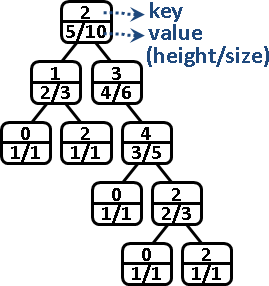
名次(rank)
二元搜尋樹雖然有排序的功效,但是卻沒有排名的功效。想要排名,必須在每個節點新增一個變數,記錄其子樹的節點個數。不影響時間複雜度與空間複雜度。
第k名的節點:從根往葉,取得左小孩的節點個數,判斷第k名位於左子樹還是右子樹。時間複雜度等同於二元搜尋樹的高度。
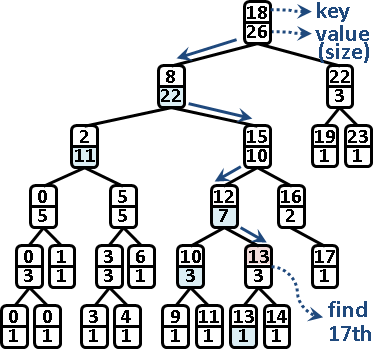
節點是第幾名:從葉往根,累計左子樹的節點個數,判斷當前節點是左小孩或右小孩以決定是否累計。時間複雜度等同於二元搜尋樹的高度。
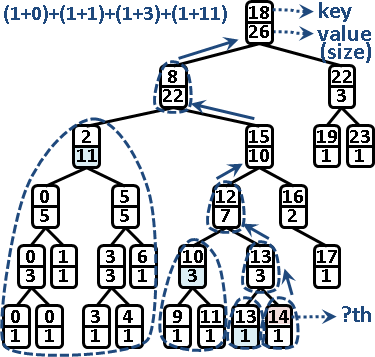
UVa 10909
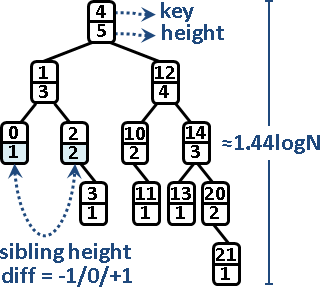
AVL tree(balanced binary search tree)
「AVL樹」。每一個節點(每一棵子樹),左子樹與右子樹的高度差最多為一。此舉造成二元搜尋樹的高度最多是1.44logN = O(logN),讓各項操作穩定運行,不會產生忽快忽慢的極端現象。
旋轉:改變連接方式,調整高度差。時間複雜度O(1)。
旋轉不影響次序,但是會影響分割基準,使得右子樹較大或相等,導致搜尋、插入、刪除完全失效。AVL tree必須數字相異。
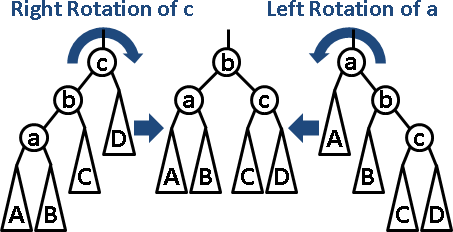
每次插入、刪除之後,馬上旋轉,讓整棵樹平衡。
插入平衡:沿著插入路線,找到最深、高度差超過一的節點(子樹),接著分為四類情況。左左/右右:旋轉子樹樹根,立即平衡。左右/右左:先旋轉子樹樹根的左/右小孩,成為左左/右右,後續同前。旋轉一至兩次,就使整棵樹平衡。時間複雜度O(1)。
刪除平衡:沿著刪除路線,找到高度差超過一的節點。旋轉次數等同於二元搜尋樹的高度。時間複雜度O(logN)。
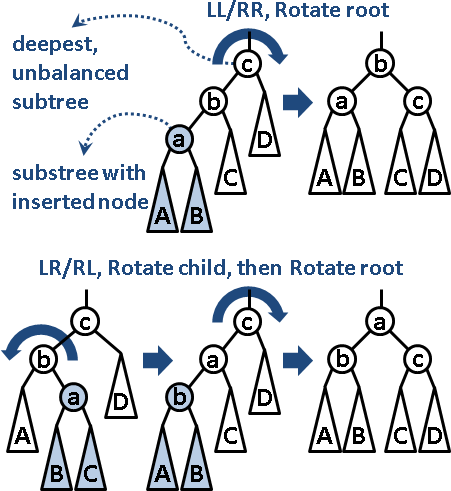
UVa 11688
red–black tree
「紅黑樹」。沒有完全平衡,高度最多是2logN。
紅黑樹規則複雜,速度慢,此處不介紹。
早期謠言:AVL tree高度均勻、搜尋快、插入刪除慢;red–black tree與之相對。
近期實測:日常應用,AVL tree比red–black tree快20%。隨機亂數,差異不明顯。
https://benpfaff.org/papers/libavl.pdf
可以直接使用C++標準函式庫的set、map。
splay tree
「伸展樹」。沒有完全平衡,不過大致平衡。
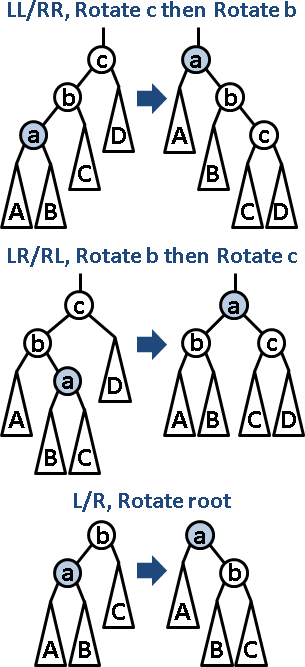
伸展:把一個節點不斷雙旋至根。徹底縮短搜尋路線。也讓整棵樹更平衡。
每次插入、刪除之後,馬上伸展。此舉使得搜尋、插入、刪除、伸展的均攤時間複雜度成為O(logN)。
weak AVL tree / relaxed AVL tree
「弱AVL樹」。樹葉等級是0。父親等級多1或2。升級、降級、旋轉:調整等級。插入平衡:升級平均5次,旋轉1至2次。刪除平衡:降級平均1次,旋轉1至2次。《Rank-Balanced Trees》。
「鬆弛AVL樹」。樹葉等級非負。父親等級相等或更高。等級大於等於高度。不做刪除平衡。《Deletion Without Rebalancing in Binary Search Trees》。
僅有理論上的價值,沒有實務上的價值。
finger search tree
我沒有研究。有空再來整理吧!

