sort
「排序」。把一群數字由小到大排好。
排序演算法類型
一、使用循序資料結構,例如array、list,將數字依序放進去,執行排序演算法。
二、使用具備排序功效的資料結構,例如binary search tree、binary heap,將數字整個倒進去、整個倒出來,完成排序。
本文討論第一種類型。第二種類型請見本站文件「binary search tree」。
排序原理
一、對調(比較)。二、放置(索引)。
對調式排序,將小數字往前挪、大數字往後挪。基礎的對調式排序是selection sort。當前最快的對調式排序是pdqsort。
放置式排序,需要額外的記憶體空間來放置數字,但是計算時間遠少於對調式排序。基礎的放置式排序是counting sort。當前最快的放置式排序是radix sort。
英文說法:一、比較式排序演算法comparison-based sorting algorithm、交換排序exchange sort。二、非比較式排序演算法non-comparison-based sorting algorithm、分布排序distribution sort。
等價於數字的東西也可以排序
字元也可以排序。字元就是ASCII碼、就是數字。
指標也可以排序。指標就是記憶體位址、就是數字。
資料也可以排序。只要資料的某個特定欄位是數字,這個欄位稱作鍵值(key)。
等價於數組的東西也可以排序
數組(tuple)也可以排序。其中一種方式:先比較第一維度;如果平手,再比較第二維度;如果又平手,再比較第三維度;以此類推。這個比較方式稱作字典序(lexicographical order)。
字串也可以排序。字串就是一串ASCII碼、就是數組。
英文單字也可以排序。英文單字就是一串字母、字母可以編號、整體宛如數組。英文字典,採用了字典序,排序所有英文單字。
UVa 482
能夠建立全序的東西也可以排序
所有東西均可兩兩比較大小,而且沒有矛盾,稱作全序(total order)。
排序對象沒必要是數字。沒有數字,只有比較;沒有絕對大小,只有相對大小;無法使用放置式排序,只能使用對調式排序。
間接排序
排序會搬動資料,但是大多數時候我們不希望搬動資料。此時可以取出資料的記憶體位址,另外建立指標,對指標進行排序,但是比較對象是指標所指的資料鍵值大小。
也有人使用陣列索引值,道理跟指標相同。
stable
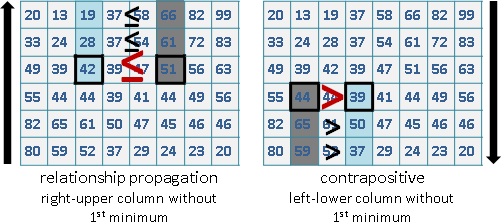
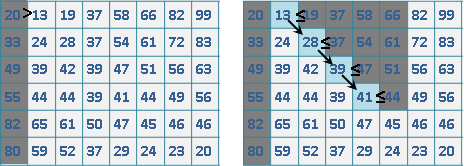
鍵值相同的資料們,原本排在前頭的,排序後仍在前頭;原本排在後頭的,排序後仍在後頭。這稱作「穩定的」排序演算法,鍵值相同、順序不變。
只要是放在陣列的資料,任何一種排序演算法,都可以擴展成穩定的排序演算法。你想到解決方法了嗎?
comparison function(comparator)
對調式排序必須使用「比較函數」。
C標準函式庫的qsort(),其參數cmp就是比較函數。意義是小於,回傳值是int變數,正零負代表< = >。
C++標準函式庫的sort(),其參數cmp就是比較函數。意義是小於,回傳值是bool變數,true false代表< ≮。
C++標準函式庫也有比較函數less(),以便作為參數預設值。
sorting network
「排序網路」。兩兩比較的先後次序圖。
每一種對調式排序演算法,都可以畫出排序網路。但是也有例外,例如quicksort的加速技巧:三個中位數的中位數,必須知道數字多寡,才能決定比較對象,此時就無法畫出排序網路。
事情也可以反過來。設計一個新的排序網路,就得到一種新的對調式排序演算法。
排序網路的深度,即是排序演算法的步驟數量。深度下限,已被證明是Ω(NlogN),不可能更少了。深度最小值,則是NP-complete問題。換句話說,找到一個深度盡量小的排序網路,目前沒有(以後大概也不會有)快速的演算法。
設計排序網路演算法,製造排序演算法,以演算法產生演算法,這件事簡直超酷的。但是很不幸的,這條路很難走。
UVa 1117
assembly instruction
得到一支程式的步驟:設計演算法,實作程式碼,再變成抽象語法樹,再變成組合指令,再變成機器碼。
想要讓程式變快,可以著眼於演算法,也可以著眼於組合指令。由於機器碼隨著電腦規格而變,故此處不討論機器碼。
已有團隊利用reinforcement learning,針對特定的排序網路,產生更少的組合指令。並且以此改良了C++標準函式庫的sort()。專案名稱是AlphaDev。
排序演算法
| average worst | extra | stable
| case case | space | sort
---------------+---------------------+-------+----
searching sort | O(NR) O(NR) | O(N) | ✓ → my favorite
selection sort | O(NN) O(NN) | O(1) | ✓
---------------+---------------------+-------+----
bubble sort | O(NN) O(NN) | O(1) | ✓
gnome sort | O(NN) O(NN) | O(1) | ✓ best
insertion sort | O(NN) O(NN) | O(1) | ✓ stable
Shell sort | O(NN) O(NN) | O(1) | comparison-
merge sort | O(NlogN) O(NlogN) | O(N) | ✓ based
Timsort | O(NlogN) O(NlogN) | O(N) | ✓ → sort
---------------+---------------------+-------+----
heapsort | O(NlogN) O(NlogN) | O(1) |
splaysort | O(NlogN) O(NlogN) | O(1) |
---------------+---------------------+-------+----
quicksort | O(NlogN) O(NN) | O(N) | best
introsort | O(NlogN) O(NlogN) | O(N) | comparison-
BlockQuicksort | O(NlogN) O(NlogN) | O(N) | based
pdqsort | O(NlogN) O(NlogN) | O(N) | → sort
---------------+---------------------+-------+----
counting sort | O(N+R) O(N+R) | O(R) | ✓ best
radix sort | O((N+β)D) O((N+β)D) | O(β) | ✓ → sort
---------------+---------------------+-------+----
bucket sort | O(N+β) O((N+β)D) | O(βD) | ✓
flashsort | O(N+β) O((N+β)D) | O(βD) | ✓ best
samplesort | O(NlogN) O(NN) | O(N) | ✓ parallel
IPS⁴o | O(NlogN) O(NN) | O(N) | ✓ → sort
---------------+---------------------+-------+----
sleep sort | O(N+R) O(N+R) | O(N) | ✓ → best of
the best
N: input size
R: input range
β: radix / bucket count (β = 2, generally speaking)
D: digits / recursion depth (D = logᵦR) (R = βᴰ)
searching sort
搜尋排序。依序枚舉每一個整數,看看陣列裡頭有沒有。
令最小值是A,最大值是B,從最小值到最大值有R = B-A+1個整數。時間複雜度O(RN)。
selection sort
選擇排序。掃描一遍所有數字,找到最小值,挪至陣列左端。遞迴處理尚未排序的N-1個數字。
bubble sort
氣泡排序。由左到右,相鄰兩兩比較,較大者往右挪,最後最大值會出現在陣列右端。遞迴處理尚未排序的N-1個數字。
gnome sort
地精排序。bubble sort加強版。調整兩兩比較的先後次序。
特色是程式碼只有一個迴圈,結構簡單。
insertion sort
插入排序。由左到右,逐一把數字插入到目前已排序的陣列當中。將大量數字往右挪,以騰出空間插入數字。
資料結構如果是array,可以使用binary search快速找到插入點;但是很不幸的,插入時還是要挪動整塊記憶體。
資料結構如果是list,就無法使用binary search得到插入點;但是很幸運地,插入時不必挪動整塊記憶體。
UVa 10107
Shell sort
Shell是作者姓名。insertion sort加強版。
scaling method。固定間隔取得數字作為一組,各組各自做insertion sort;間隔大小減半,重複上述動作。
特色是往右挪的總次數變少了。
merge sort
合併排序。divide-and-conquer method。分兩半、分別排序、合併。
可以直接使用C++標準函式庫的stable_sort()。
UVa 10810
Timsort
Tim是作者姓名。merge sort加強版。
合併時,若數字大小順序交錯,則適合原本方式,步步前進;若數字大小順序連貫,則適合binary search,大步邁進。
對於短區間,交錯機會少,連貫機會大,於是改成大步邁進。
分水嶺通常設定成64,沒有科學根據。
實務上速度最快的stable的對調式排序演算法。
heapsort
堆積排序。陣列可以當作二元樹。陣列可以當作binary heap。逐一把數字放入binary heap,達到排序功效。
splaysort
伸展排序。陣列可以當作二元樹。陣列可以當作splay tree。逐一把數字放入splay tree,達到排序功效。
quicksort
快速排序。divide-and-conquer method。選定pivot,挪到陣列邊緣,然後把陣列分成大的一邊和小的一邊,兩邊分別排序。
任選一個數字當作pivot,排序結果皆正確。想讓quicksort達到最佳效率,就讓每次選中的pivot,每次都把陣列分成兩等份,如此一來時間複雜度是O(NlogN)。幸運的是,即便把陣列分成數量懸殊的兩半,即便是1000000:1,只要是固定比例,時間複雜度還是O(NlogN)。但是這種事帶點運氣成份。
固定選擇最後一個數字當作pivot,也有機會把陣列分成兩等份。然而這卻產生一個古怪現象:遇到已經排序的陣列,每次都把陣列分成(N-1):1,時間複雜度變成O(N²),超級慢。quicksort有時快、有時慢;遇到幾乎排序好的陣列,更是慢到吐血。
為了避免這種情況,可以每次都用亂數選擇pivot,如此一來比較不容易出現上述古怪現象。然而這又衍生一個難纏問題:只是做個排序,卻還得載入亂數模組,耗損系統資源、拖慢系統速度,帶來了新的壞處。
最後大家捨棄亂數,轉而構思一些小技巧,讓pivot儘可能把陣列分成兩等分。例如Java的quicksort,把陣列切成前中後三段,拿這三段中央的數字,三個數字的中位數當作pivot。這便是一個簡單實用的小技巧。
UVa 755
© 2010 tkcn. All rights reserved.
introsort
內排序。quicksort加強版。遞迴分割陣列,區間越來越短,數字也幾乎排序好了。對於幾乎已經排序好的短區間,quicksort慢到吐血。此時改用heapsort,強硬地壓低最差時間複雜度。
分水嶺通常設定成logN² = 2logN,N是陣列長度。
可以直接使用C++標準函式庫的sort()。
BlockQuicksort
分塊快速排序。quicksort加強版。比較大小,避免branch misprediction,改用整數運算。對調數字,避免cache miss,改用分塊搬運。
pattern-defeating quicksort(pdqsort)
破格快速排序。introsort暨BlockQuicksort加強版。比較大小、對調數字,進行細部改良。盡量避免使用緩慢的heapsort。
實務上速度最快的對調式排序演算法。
counting sort
計數排序。全部數字,依其數值,放到相符位置。由小到大讀取各個位置的數字。只能處理整數。
UVa 484 11462
radix sort
基數排序。scaling method。低位數到高位數,每個位數依序作為鍵值,總共做D回合counting sort,D為位數大小。
二進位數字,基數β = 2,位數D = logᵦR。實務上取基數β = 256 = 2⁸,記憶體剛好是1 byte = 8 bit。
也能處理二補數。仔細判讀正負號位置。
也能處理浮點數。仔細判讀正負號位置、次方值位置。
實務上速度最快的排序演算法。
bucket sort
桶排序。divide-and-conquer method。自訂桶子數量β、自訂桶子區間[a₀,a₁)到[aᵦ₋₁,aᵦ)。每個數字放到相符桶子。各個桶子各自排序。由小到大讀取各個桶子的數字。可以處理非整數。
桶子區間,習慣遞迴等分。數字範圍,除以桶子數量,作為桶子區間寬度。每個數字經由除法運算、取整運算,求得相符桶子編號。
flashsort
閃排序。bucket sort加強版。預先求得最小值、最大值,作為數字範圍。最大值減最小值,除以桶子數量,作為桶子區間寬度。
samplesort
抽樣排序。bucket sort加強版。隨機抽樣,作為桶子區間。
可以視作quicksort的通例。大量pivot,將陣列分成多段。
in-place parallel super scalar samplesort(IPS⁴o)
原地平行超純量抽樣排序。samplesort平行化版本。
in-place:額外記憶體空間為O(1),甚至不需要額外記憶體空間。
parallel:多個中央處理器。此處是指,各桶各自排序。
superscalar:中央處理器,整合處理多個指令。此處是指,整合處理比較與交換。
cache-efficient:記憶體區塊,鮮少反覆載入。此處是指,比較集中在同一區塊。
branch-prediction:if判斷結果,經常預測成功。此處是指,比較結果經常一致。
平行計算的情況下,實務上速度最快的對調式排序演算法。
sleep sort
睡眠排序。源自網路論壇4chan。
延遲輸出,延遲時間是數字大小。數字越小,輸出越早。
實務上最適合拿來裝逼的排序演算法。