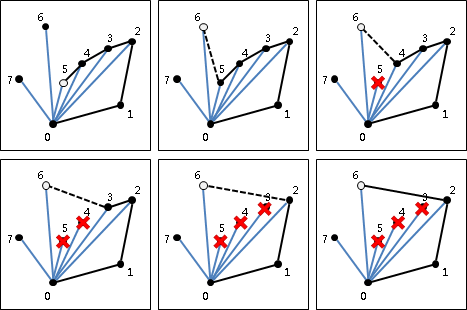
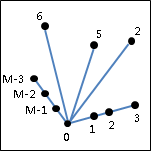
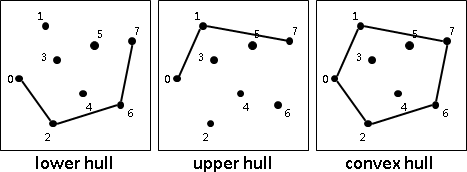
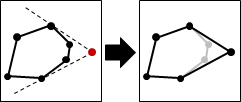
convex hull
convex hull
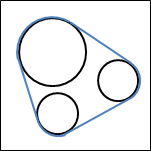
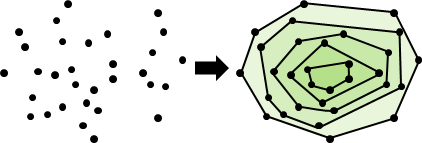
中譯「凸包」或「凸殼」。在高維空間中有一群散佈各處的點,「凸包」是包覆這群點的所有外殼當中,表面積最小的一個外殼,而表面積最小的外殼一定是凸的。
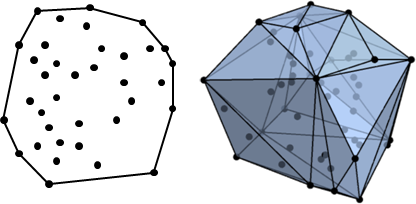
p = RandomInteger[10, {50, 3}]; Show[HighlightMesh[ConvexHullMesh[p], {Style[1, Black, Thick], Style[2, Opacity[0.7]]}], Graphics3D[{PointSize[0.03], Point[p]}]]
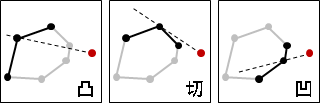
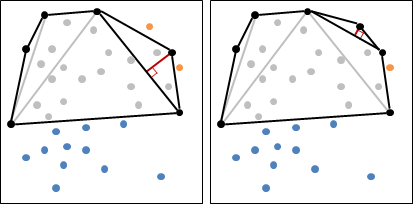
至於「凸」的定義是:圖形內任意兩點的連線不會經過圖形外部。「凸」並不是指表面呈弧狀隆起,事實上凸包是由許多平坦表面組成的。
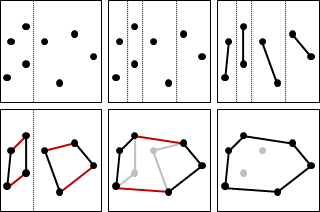
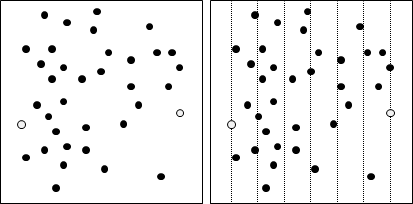
以下討論比較簡單的情況:替二維平面上散佈的點,找到凸包。
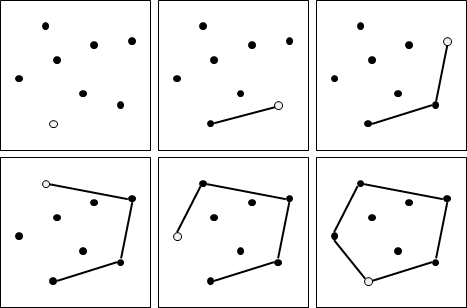
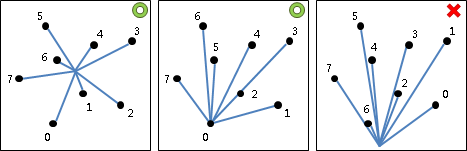
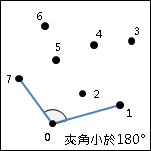
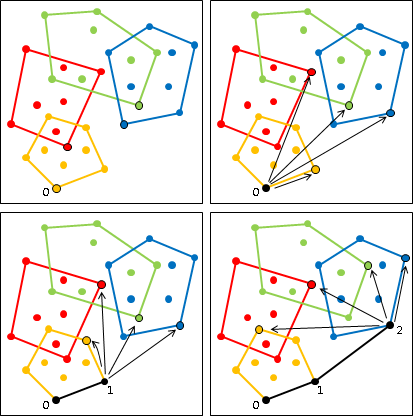
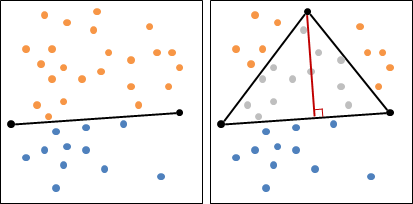
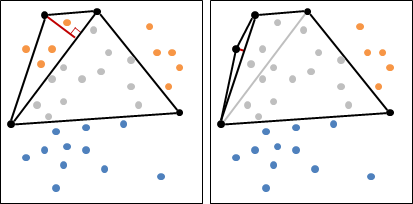
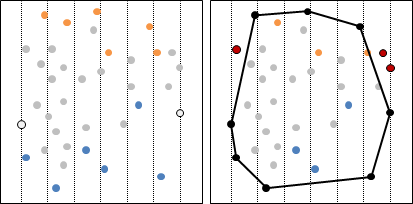
二維平面上的凸包是一個凸多邊形,在所有點的外圍繞一圈即得凸包。另外,最頂端、最底端、最左端、最右端的點,一定是凸包上的點。
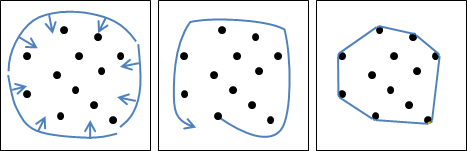
計算凸包時需考慮一些特殊情況:一、凸包上多點重疊;二、凸包上多點共線;三、凸包呈一條線段、一個點、沒有點。通常我們會簡化資訊,以最少的點來記錄凸包,去掉重疊、共線的點。
UVa 109 132 218 361 596 675 681 811 819 10002 10065 10078 10135 10173 10256 10625 11168 11626 ICPC 4450
UVa 802 10089 ICPC 7585
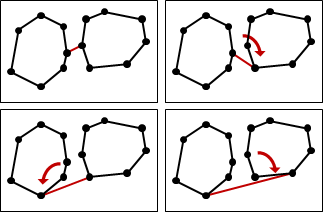
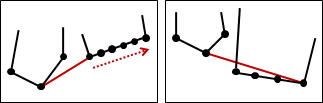
任意圖形的凸包
任意圖形都能求出凸包。例如一個多邊形的凸包、大量三角形的凸包、大量線段的凸包。這些問題都可以簡化為一群點的凸包。

圓形、曲線的凸包,我們以下不討論。