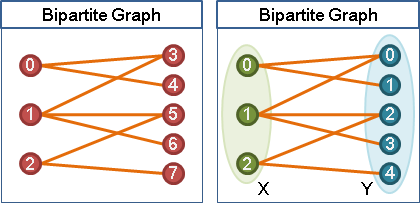
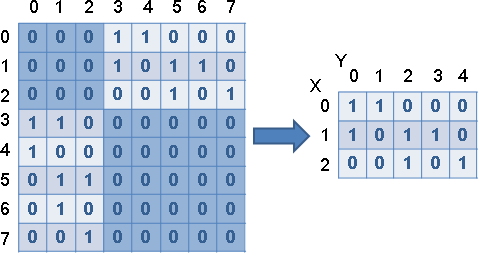
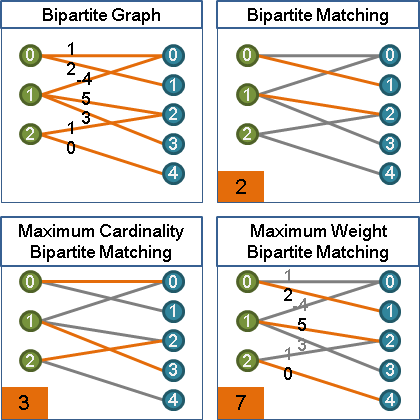
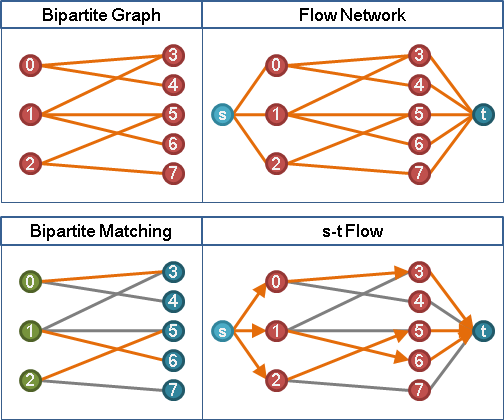
用途
求出一張二分圖的其中一個最大權完美二分匹配。稍做修改,也能求出最大權最大二分匹配、最大權二分匹配,以及最小權版本。
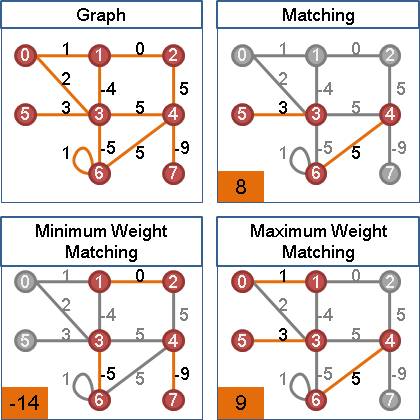
maximum weight bipartite matching
一張二分圖中,權重最大的二分匹配。
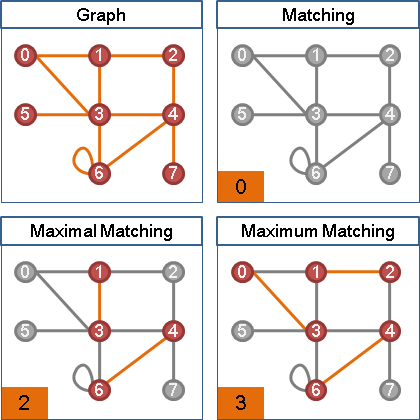
maximum weight maximum (cardinality) bipartite matching
一張二分圖中,配對數最多的前提下,權重最大的二分匹配。
maximum weight perfect bipartite matching
一張二分圖中,所有點都送作堆的前提下,權重最大的二分匹配。
調整權重
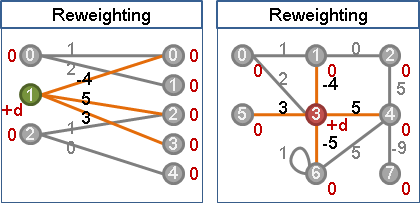
一個點連接的所有邊,等量增加權重、等量減少權重,都不會影響最大權完美匹配的位置。
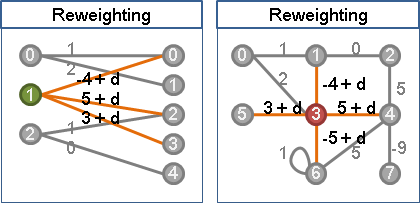
此性質二分圖和一般圖都成立。
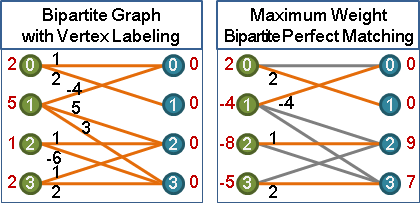
建立vertex labeling
幫各個點都創造一個變數,直接在點上調整權重,代替在邊上調整權重,藉此減少調整權重的時間。
最小化所有點的權重總和 = 最大化所有匹配邊的權重總和
建立一組vertex labeling:令圖上每一條邊,其兩端點的權重總和,大於等於邊的權重。
l(x) + l(y) ≥ adj(x,y)
所有點的權重總和,大於等於任意匹配的權重(所有匹配邊的權重總和)。
∑ l(x) ≥ ∑ adj(x,y)
V M
盡力降低所有點的權重總和,就能逼近最大權完美匹配的權重。
min ∑ l(x) = max ∑ adj(x,y)
V M
求出一組總和最小的vertex labeling,就能得到最大權完美匹配。
求最大值變成了求最小值,這是很實用的數學轉換。這個轉換有個重要目的:操作vertex labeling而不操作edge labeling,藉此減少調整權重的時間。
【註:以linear programming的觀點來看,這個轉換正是primal problem與dual problem之間的轉換。】
equality edge(admissible edge)

「等邊」。兩端點的點權重相加,恰好等於邊權重。
l(x) + l(y) = adj(x,y)
當vertex labeling的總和降低到極限,可以發現最大權完美匹配的所有匹配邊都是等邊。
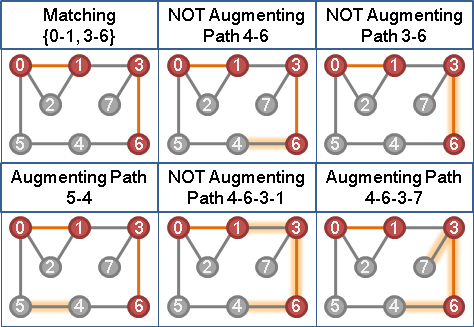
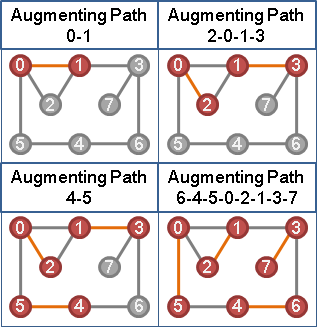
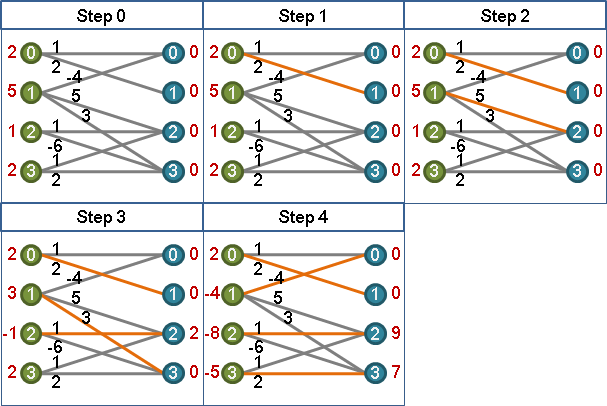
augmenting path algorithm + equality edge
結合擴充路徑與等邊,得到最大權完美匹配演算法。
一、一開始圖上所有點都是未匹配點。
二、每個未匹配點,依序嘗試作為擴充路徑的端點。擴充路徑必須全是「等邊」。
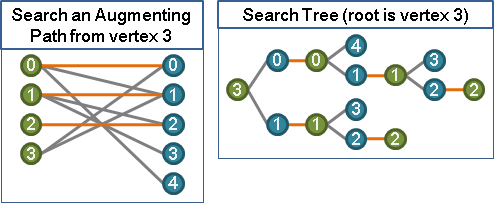
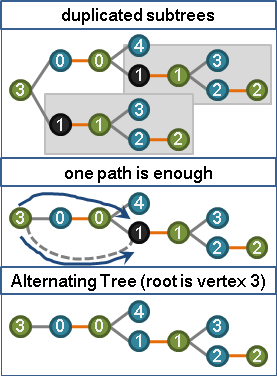
以graph traversal建立交錯樹。交錯樹必須全是「等邊」。
甲、如果找得到「等邊」擴充路徑:進行擴充。
乙、如果找不到「等邊」擴充路徑:?????
擴充路徑全是等邊,最後得到的最大權匹配當然全是等邊。
當找不到等邊,只好想辦法調整vertex labeling了。
調整vertex labeling
必須維持每一條邊的大於等於性質,而且既有等邊不能動。該如何調整權重呢?
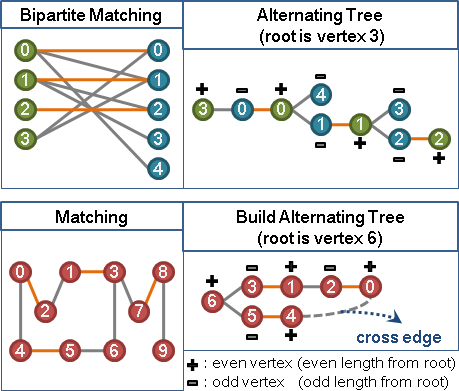
先把等邊交錯樹延伸到極限,再窮舉末梢的非等邊,計算「兩端點的點權重相加、再減掉邊權重」,找到此差值最小者。
d = min { l(x) + l(y) - adj(x,y) } x為樹上一點、y為樹外一點
樹上偶點減此值、樹上奇點加此值。一加一減,樹內樹外既有等邊保持不動,樹梢則有一條(以上)非等邊變成了等邊。
l(x) -= d x為樹上偶點
l(x) += d x為樹上奇點
如此便製造了一條(以上)的等邊,而且既有等邊保持不動,而且維持了每一條邊的大於等於性質。整張圖的等邊只增不減。
【註:這宛如最短路徑問題的調整權重手法。】
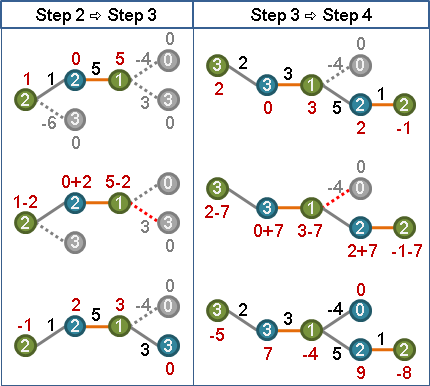
等邊交錯樹宛如最小生成樹,製造等邊宛如Prim's algorithm,屢次找不在樹上、讓匹配權重下降最少的等邊。
演算法
一、建立vertex labeling,使之滿足前述的大於等於性質。
二、一開始圖上所有點都是未匹配點。
三、X的每個未匹配點,依序嘗試作為等邊擴充路徑的端點。
以graph traversal建立等邊交錯樹。
(X的未匹配點一旦處理完畢,Y的未匹配點不會再有擴充路徑,故只需找X側。)
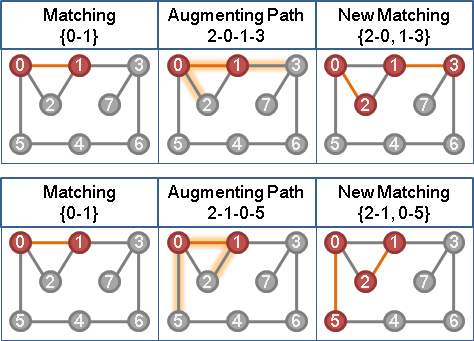
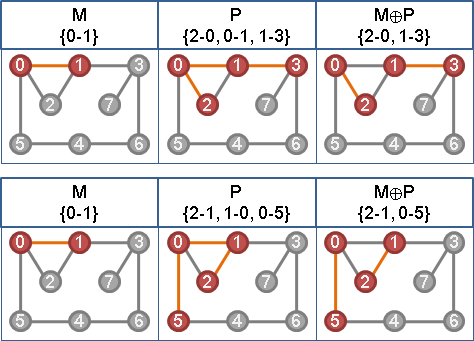
甲、如果找得到等邊擴充路徑:
沿著等邊擴充路徑修改現有匹配,以增加cardinality。
乙、如果找不到等邊擴充路徑,則製造新等邊:
等邊交錯樹末梢的非等邊,算最小差值d。(有人稱作slack)
樹上偶點減d,樹上奇點加d。樹梢新增了一條以上的等邊。
找出一個最大權完美二分匹配
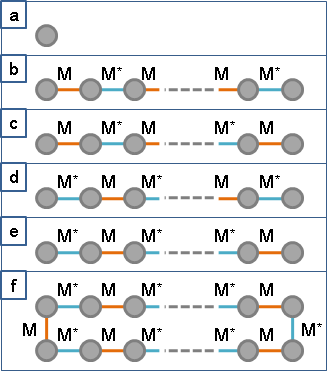
一、V個未匹配點分別建立交錯樹。二、一棵交錯樹最多V點,每次調整權重得以新增一點(以上)。三、每次調整權重之前,需要找到最小差值,最多窮舉E條邊。
時間複雜度是三者相乘。圖的資料結構為adjacency matrix是O(V⁴);圖的資料結構為adjacency lists是O(VVE)。
找出一個最大權完美二分匹配
交錯樹的建立過程,宛如最小生成樹的Prim's algorithm,宛如最短路徑樹的Dijkstra's algorithm,運用各種極值資料結構得以降低時間複雜度。例如建立表格記錄最小差值,時間複雜度降為O(V³)。
UVa 11383 1411
最大權最大二分匹配
化作最大權完美二分匹配:假設X大Y小。Y側,補X-Y個點、連X(X-Y)條零邊。
最大權二分匹配
化作最大權最大二分匹配:最大權二分匹配不必有負邊,預先捨棄圖上所有負邊。
最小權完美二分匹配
化作最大權完美二分匹配:邊權重變號。