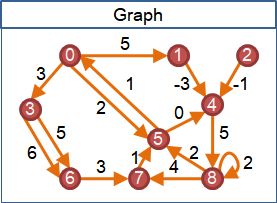
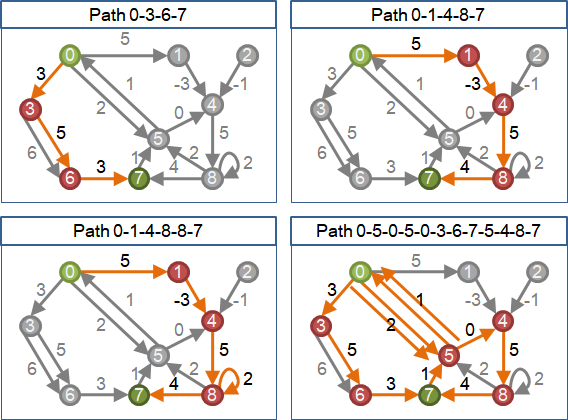
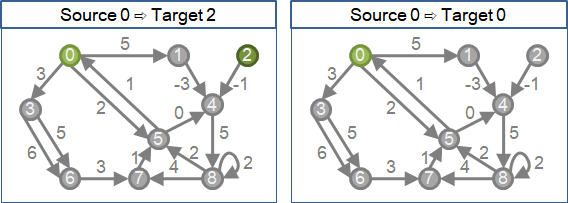
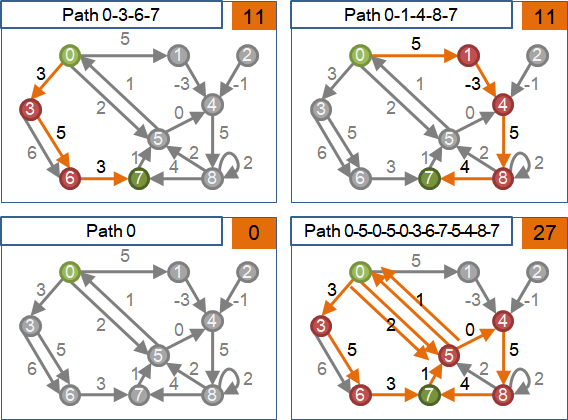
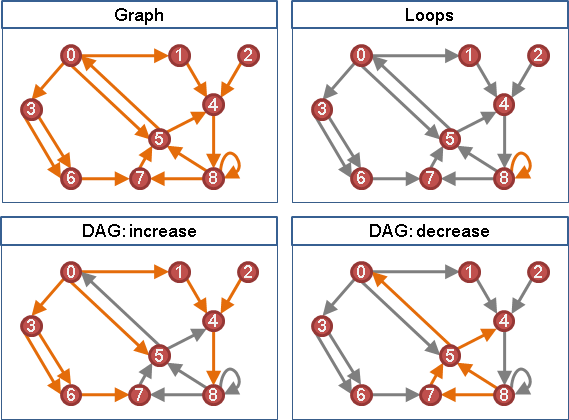
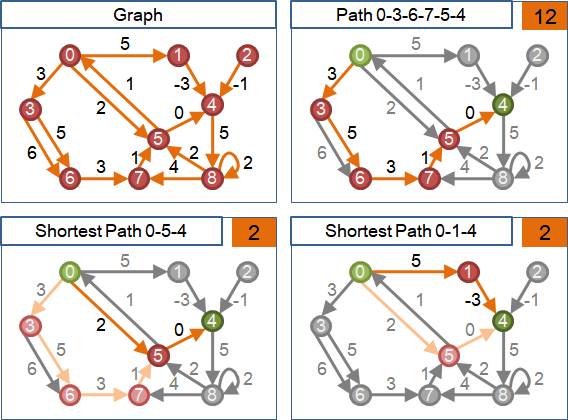
shortest path
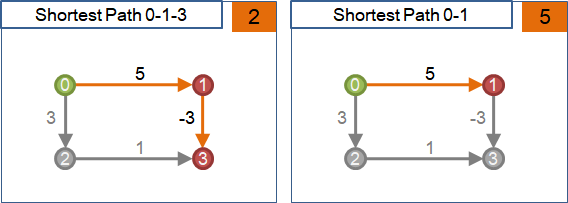
「最短路徑」是由起點到終點、權重最小的路徑,可能有許多條,也可能不存在。起點到終點不通、不存在路徑的時候,就沒有最短路徑。
「最短路徑」不見得是邊最少、點最少的路徑。
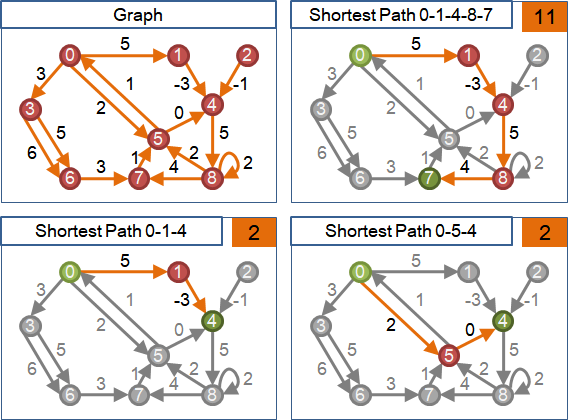
longest path
最長路徑和最短路徑很類似。最長路徑問題當中,每一條邊的權重添上負號,就變成最短路徑問題。反過來也是。
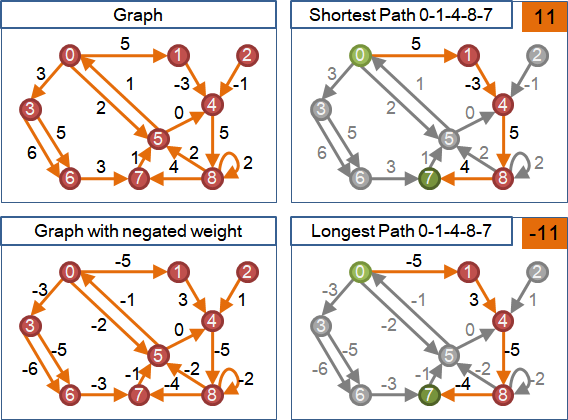
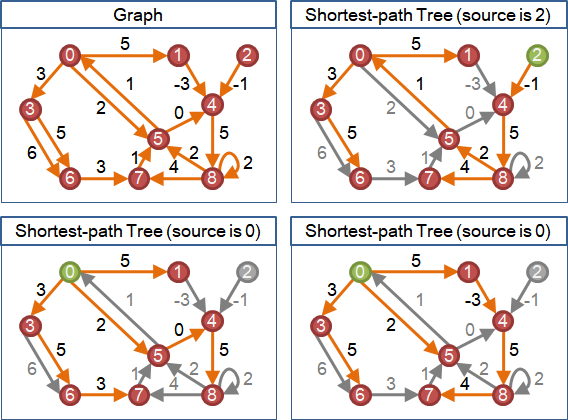
shortest-path tree
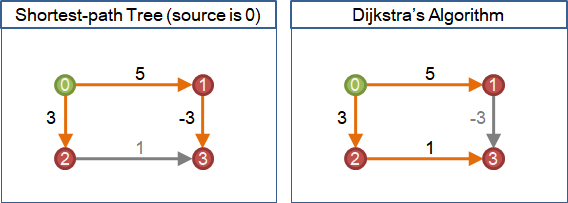
最短路徑有一個特別的性質:每一條最短路徑,都是由其它的最短路徑延展而得。一條最短路徑,截去末端之後,還是最短路徑。
提到延展,就聯想到樹!引入延展的概念,最短路徑們得以形成一棵樹。
在圖上選定一個起點,由起點到圖上各點的最短路徑們,形成一棵有向樹,稱作「最短路徑樹」。由於兩點之間的最短路徑不見得只有一條,所以最短路徑樹也不見得只有一種。
shortest-path graph
在圖上選定一個起點和一個終點,由起點到終點的所有最短路徑們,形成一張有向圖,稱作「最短路徑圖」,只有唯一一種。
當圖上每一條邊的權重都是正數,最短路徑圖是有向無環圖DAG。
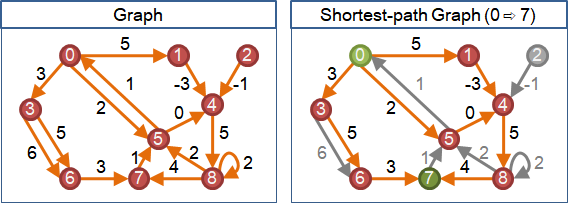
兩點之間有多條邊
當一張圖的兩點之間有多條邊,可以留下一條權重最小的邊。這麼做不影響最短路徑。
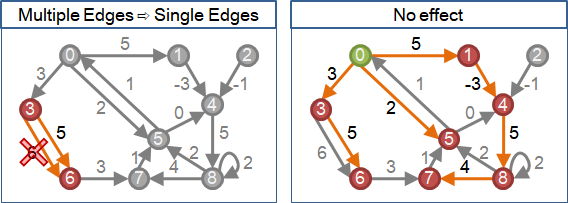
當圖的資料結構為adjacency matrix,任兩點之間只能擁有一個權重值。此時權重值必須設定成權重最小的邊的權重。
兩點之間沒有邊(兩點不相鄰)
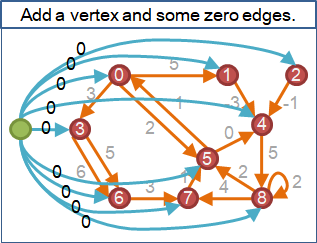
當一張圖的兩點之間沒有邊,可以補上一條權重無限大的邊。這麼做不影響最短路徑。
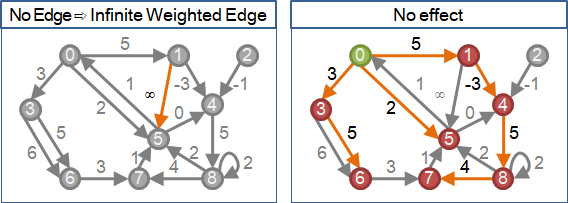
當圖的資料結構為adjacency matrix,任兩點之間一定要有一個權重值。此時權重值必須設定成一個超大數字,當作無限大;不可設定為零,以免計算錯誤。
最短路徑長度正無限大、負無限大
當起點無法到達終點,就沒有最短路徑了。這種情況常被解讀成:起點永遠走不到終點,導致最短路徑長度正無限大。
當起點到終點之間存在負邊、負環,不斷折返負邊、不斷繞行負環,導致最短路徑的長度負無限大。
「負邊negative edge」是權重為負值的邊。「負環negative cycle」是權重為負值的環。
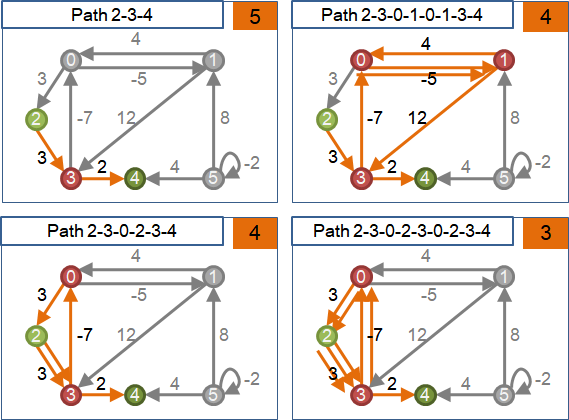
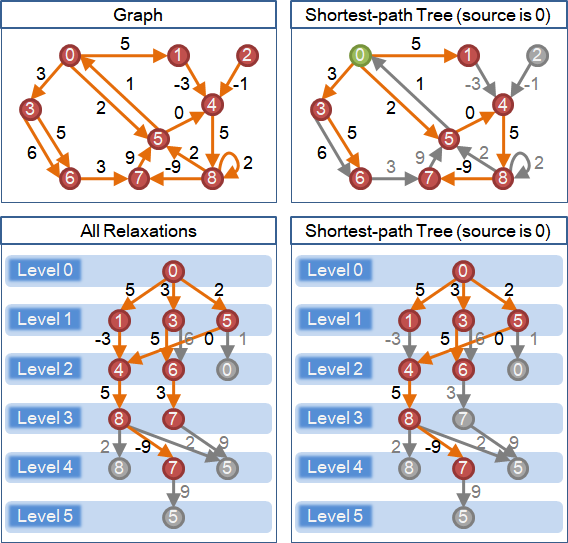
relaxation
最後介紹最短路徑演算法一個共通的重要概念「鬆弛」。
尋找兩點之間的最短路徑時,最直觀的方式莫過於:先找一條路徑,然後再找其他路徑,看看會不會更短,並記住最短的一條。
找更短的路徑並不困難。我們可以尋覓捷徑,以縮短路徑;也可以另闢蹊徑,取代原本的路徑。如此找下去,必會找到最短路徑。
尋覓捷徑、另闢蹊徑的過程,可以以數學方式來描述:現在要找尋起點為s、終點為t的最短路徑,而且現在已經有一條由s到t的路徑,這條路徑上會依序經過a及b這兩點(可以是起點和終點)。我們可以找到一條新的捷徑,起點是a、終點是b的捷徑,以這條捷徑取代原本由a到b的這一小段路徑,讓路徑變短。
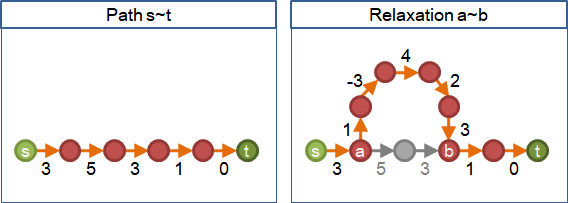
找到捷徑以縮短原本路徑,便是relaxation。
最短路徑演算法的功能類型
point-to-point shortest path,點到點最短路徑:
給定起點、終點,求出起點到終點的最短路徑。一對一。
single source shortest paths,單源最短路徑:
給定起點,求出起點到圖上每一點的最短路徑。一對全。
all pairs shortest paths,全點對最短路徑:
求出圖上所有兩點之間的最短路徑。全對全。
最短路徑演算法的原理
label correcting:
設定某個點的最短路徑長度之後,之後仍可繼續修正,越修越美。
整個過程就是不斷重新標記每個點的最短路徑長度。
label setting:
逐步設定每個點的最短路徑長度,一旦設定後就不再更改。
只適用於圖上只有正邊和零邊。