HOG – histograms of oriented gradients
SIFT – scale-invariant feature transform
GLOH – gradient location and orientation histogram
SURF – speeded up robust features
BRIEF – binary robust independent elementary features
ORB – oriented FAST and rotated BRIEF
BRISK – binary robust invariant scalable keypoints
FREAK – fast retina keypoint
KAZE – KAZE is a Japanese word that means wind
AKAZE – accelerated-KAZE
[相機外]方向 orientation R
位置 position tₓ t t
比例尺度 ratio scale s
[相機內]焦距 focal length f
扭曲係數 distortion coefficient k₁ k₂
長寬比 aspect ratio sᵤ sᵥ
偏移量 offset oᵤ oᵥ
步驟一三可以寫成矩陣運算。步驟二無法寫成矩陣運算。
1. change coordinate system of object (object -> camera)
⎡ xꟲ ⎤ ⎡ R₁₁ R₁₂ R₁₃ tₓ ⎤ ⎡ xᴼ ⎤
⎢ yꟲ ⎥ = s ⎢ R₂₁ R₂₂ R₂₃ t ⎥ ⎢ yᴼ ⎥ s can be eliminated
⎣ zꟲ ⎦ ⎣ R₃₁ R₃₂ R₃₃ t ⎦ ⎢ zᴼ ⎥ due to perspective
⎣ 1 ⎦ projection
2. transform object to image (in camera coordinate system)
⎰ uꟲ = (f/zꟲ) xꟲ perspective projection
⎱ vꟲ = (f/zꟲ) yꟲ
⎰ úꟲ = (1 + k₁r² + k₂r⁴) uꟲ distortion
⎱ v́ꟲ = (1 + k₁r² + k₂r⁴) vꟲ where r² = (uꟲ)² + (vꟲ)²
3. change coordinate system of image (camera -> image)
⎡ uᴵ ⎤ ⎡ sᵤ 0 oᵤ ⎤ ⎡ úꟲ ⎤
⎣ vᴵ ⎦ = ⎣ 0 sᵥ oᵥ ⎦ ⎢ v́ꟲ ⎥
⎣ 1 ⎦
camera calibration
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) find f k₁ k₂ sᵤ sᵥ oᵤ oᵥ
camera resectioning
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) find R t
camera calibration = camera resectioning
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) find R t f k₁ k₂ sᵤ sᵥ oᵤ oᵥ
A = 𝑅𝑄 RQ decomposition
A = 𝑄′𝑅′ QR decomposition
𝑅 and 𝑅′ are upper triangular matrices
𝑄 and 𝑄′ are orthonormal matrices
get “RQ decomposition of A” by “QR decomposition of A⁻¹”
A = 𝑅𝑄 RQ decomposition of A (unknown)
A⁻¹ = 𝑄″𝑅″ QR decomposition of A⁻¹ (known)
A = 𝑅″⁻¹𝑄″⁻¹ inverse formula
⎧ 𝑅 = 𝑅″⁻¹ inverse of upper triangular matrix
⎨ is also an upper triangular matrix
⎪ 𝑄 = 𝑄″⁻¹ = 𝑄″ᵀ inverse of orthonormal matrix
⎩ is also an orthonormal matrix
H = K [R|t]
⎡ | | | | ⎤ ⎡ | | | | ⎤
⎢ h₁ h₂ h₃ h₄ ⎥ = K ⎢ r₁ r₂ r₃ t ⎥
⎣ | | | | ⎦ ⎣ | | | | ⎦
⎡ | | | ⎤
⎢ h₁ h₂ h₃ ⎥ = K R = 𝑅 𝑄
⎣ | | | ⎦
⎧ K = 𝑅
⎨ R = 𝑄
⎩ t = K⁻¹h₄
resolve name collision:
R is rotation matrix (orthonormal matrix)
𝑅 is from RQ decomposition (upper triangular matrix)
y = λ K [R|t] x camera imaging
y = λ H x product of two matrices
⎡ ŭ ⎤ ⎡ u ⎤
⎢ v̆ ⎥ = λ ⎢ v ⎥ vector form
⎣ 1 ⎦ ⎣ w ⎦
λ = (ŭ/u + v̆/v + 1/w) / 3 expected value
⎧ y₁ = λ₁ H x₁ camera imaging of N points
⎨ : :
⎩ yɴ = λɴ H xɴ
λ = (λ₁ + ... + λɴ) / N expected value (slow)
(sum yᵢ) = λ H (sum xᵢ) additivity
⎡ ŭ ⎤ ⎡ u ⎤
⎢ v̆ ⎥ = λ ⎢ v ⎥ vector form
⎣ 1 ⎦ ⎣ w ⎦
λ = (ŭ/u + v̆/v + 1/w) / 3 expected value (fast)
some formulas for quaternion
q = a + bi + cj + dk
exp(q) = exp(a) [ cos(‖v‖) + (v/‖v‖) sin(‖v‖) ]
ln(q) = ln(‖q‖) + (v/‖v‖) cos⁻¹(a/‖q‖)
let real part be a
let imagine part be v = bi + cj + dk
quaternion of spin
q = exp(u ½θ)
= cos(½θ) + u sin(½θ)
= cos(½θ) + uₓ sin(½θ) i + u sin(½θ) j + u sin(½θ) k
logarithm of quaternion of spin (real part is zero!)
p = ln(q) = u ½θ
let spin axis be unit vector (uₓ,u,u) (uₓ²+u²+u² = 1)
let spin angle be θ
let quaternion of spin axis be u = uₓi + uj + uk
logarithm of quaternion of spin
p = wₓi + wj + wk
quaternion of spin
exp(p) = exp(0) [ cos(‖w‖) + (w/‖w‖) sin(‖w‖) ]
= cos(½θ) + u sin(½θ)
let real part be 0
let imagine part be w = wₓi + wj + wk
thus w/‖w‖ is spin axis
thus 2‖w‖ is spin angle
camera calibration
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) find R t f k₁ k₂ sᵤ sᵥ oᵤ oᵥ
camera pose estimation
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) find R t
camera pose estimation (with calibrated camera) ✔
given ((xᴼ,yᴼ),(uᴵ,vᴵ)) f k₁ k₂ sᵤ sᵥ oᵤ oᵥ find R t
Shape and Motion from Image Streams under Orthography: A Factorization Method
相機成像模型,透視投影硬是改成仿射變換,形成一次函數,以便使用奇異值分解。
Factorization Methods for Projective Structure and Motion
相機成像模型,仿射變換硬是調整成透視投影。
PowerFactorization: 3D Reconstruction with Missing or Uncertain Data
走火入魔。
nonlinear triangulation:nonlinear least squares。效果最好。無視原本射線。找到最佳物體位置,物體位置分別重新投影到兩張圖片,兩個投影點與原本對應點對差異盡量小,差異採用距離平方總和。簡單來說,image feature matching的觀測值,camera imaging的估計值,平方誤差總和盡量小。此誤差稱作reprojection error。
two-view triangulation:
min ‖y₁ - F(x; R₁,t₁,λ₁,f₁,⋯)‖² + ‖y₂ - F(x; R₂,t₂,λ₂,f₂,⋯)‖²
x
multi-view triangulation:
N
min sum ‖yₙ - F(x; Rₙ,tₙ,λₙ,fₙ,⋯)‖²
x n=1
Hartley–Sturm linear triangulation:homogeneous linear least squares。效果尚可。一、camera imaging的估計值,採用y = λ K [R|t] x,省略λ = 1/zꟲ。導致估計值不在圖片上面。導致估計值從點座標變成射線向量。二、使用共線製造等式。令觀測向量和估計向量盡量共線(叉積盡量為零)。三、以焦距f求得點座標。
ego-motion = camera motion estimation in static scene
Scene Flow Estimation = optical flow with depth map
Moving Object Detection by 3D Flow Field Analysis
https://hal.science/hal-03565160
BundleSDF
https://bundlesdf.github.io/
Solving these problems will unlock
a wide range of applications in areas such as
augmented reality [34], robotic manipulation [22, 70],
learning-from-demonstration [71], and sim-to-real transfer.
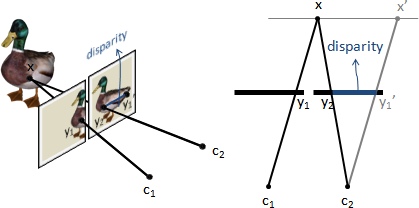
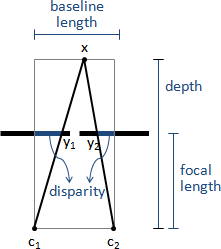
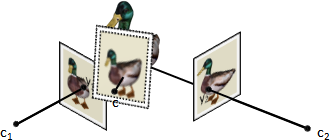
block matching:dynamic programming。一、最佳匹配:對應scanline,一口氣找到所有對應像素。對應像素位置單調遞增。左右視野看見不同部件必須刪除。綜上所述就是longest common subsequence或dynamic time warping。二、匹配成本:左圖每個像素的每種視差的成本C(p,d)。左圖像素p利用視差d取得右圖對應像素p',考慮兩個像素的差異。三、像素差異:針對一個像素,取得周遭像素,形成方形區塊(自訂大小),考慮兩個區塊的差異。四、區塊差異:三種公式sum of absolute differences、sum of squared differences、zero-mean normalized cross correlation。採用後者。五、狀態轉移成本:視差差異(乘上自訂權重)。六、匹配範圍:事先做image segmentation。景色陡變之處通常是視差陡變之處。








{kind=link}
{kind=link}