multivariate root finding
multivariate root finding(nonlinear equation)
「多變量求根」。多變量函數求根。
輸出變成多個數值,衍生一個問題:如何求斜率?
導數們從上到下、從左到右依序併成矩陣。細節請見後面章節。
⎡ f₁(x) ⎤
F(x) = ⎢ f₂(x) ⎥
⎣ f₃(x) ⎦
∂ ⎡ | | | ⎤
F′(x) = —— F(x) = ⎢ f₁′(x) f₂′(x) f₃′(x) ⎥
∂x ⎣ | | | ⎦
演算法(ℝ⇨ℝ Newton's method)
從頭複習一遍牛頓法吧。
座標(x, f(x))的切線,與座標軸相交之處,作為下一個x。
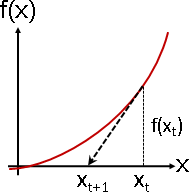
斜率是直除以橫。得到一道等式。
高度f(xₜ),除以跨距(xₜ - xₜ₊₁),得到切線斜率f′(xₜ)。
f′(xₜ) = f(xₜ) / (xₜ - xₜ₊₁)
只有乘法,沒有除法。
f′(xₜ) (xₜ - xₜ₊₁) = f(xₜ)
移項整理,提出xₜ₊₁。得到牛頓法公式。
xₜ₊₁ = xₜ - f(xₜ) / f′(xₜ)
時間複雜度O(T),T是遞推次數。
演算法(ℝⁿ⇨ℝ Newton's method)
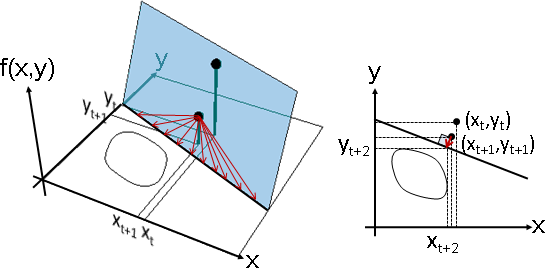
牛頓法,推廣成許多個輸入變數。
斜率推廣成梯度。切線推廣成切面。交點推廣成交線。
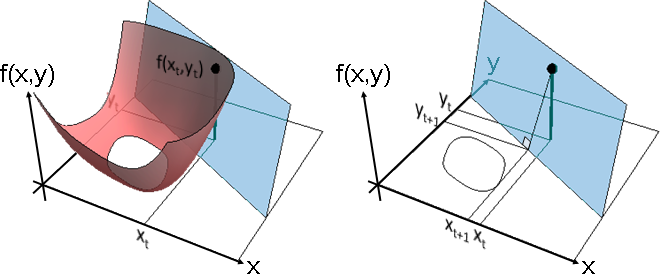
k[x_, y_] := Sqrt[(1.5*x*x*x)^2] + Sqrt[(2*y*y*y)^2] + 0.5*x*y - 0.05; f[x_, y_] := k[x + .4, y + .3]; x0 = .5 - .4; y0 = .65 - .3; f0 = f[x0,y0]; gx0 = N[Derivative[1,0][f][x0,y0]]; gy0 = N[Derivative[0,1][f][x0,y0]]; xyplane = Graphics3D[{Opacity[0], Polygon[{{-1,-1,0},{-1,1,0},{1,1,0},{1,-1,0}}]}, Boxed -> False (*, ViewPoint -> {0, 0, -Infinity}*) ]; func = Plot3D[f[x,y], {x, -1, 1}, {y, -1, 1}, PlotRange -> {-1, 1}, ClippingStyle -> None, Mesh -> None, PlotStyle->Opacity[0.8], RegionFunction -> Function[{x, y, z}, 0 <= z <= 1], ColorFunction -> (ColorData["CherryTones"][Rescale[#3, {-2, 2}]] &)]; plane = Plot3D[gx0*(x-x0)+gy0*(y-y0)+f0, {x, -1, 1}, {y, -1, 1}, Mesh -> None, PlotStyle -> Opacity[0.8], ColorFunction -> (RGBColor[0,112,192] &), RegionFunction -> Function[{x, y, z}, 0 <= z <= 1]]; root = Plot3D[0, {x, -1, 1}, {y, -1, 1}, PlotRange -> {-1, 1}, PlotStyle -> Opacity[0], Mesh -> None, RegionFunction -> Function[{x, y, z}, f[x,y] > 0]]; levelset = SliceContourPlot3D[f[x,y], z == 0, {x, -1, 1}, {y, -1, 1}, {z, -1, 1}, PlotRange -> {-1, 1}, Contours -> Table[i,{i,0,1,0.1}], ContourShading -> None, ContourStyle -> LightGray, BoundaryStyle -> LightGray]; x0bar = Graphics3D[{Black, Line[{{x0, -1, 0},{x0, y0, 0}}]}]; y0bar = Graphics3D[{Black, Line[{{-1, y0, 0},{x0, y0, 0}}]}]; f0bar = Graphics3D[{Thickness[0.01], CapForm["Butt"], Black, Line[{{x0, y0, 0},{x0, y0, f0}}]}]; f0point = Graphics3D[{Black, Sphere[{x0, y0, f0}, 0.05]}]; x1 = x0 - f0 * gx0 / ((gx0 ^ 2) + (gy0 ^ 2)); y1 = y0 - f0 * gy0 / ((gx0 ^ 2) + (gy0 ^ 2)); x1bar = Graphics3D[{Black, Line[{{x1, -1, 0},{x1, y1, 0}}]}]; y1bar = Graphics3D[{Black, Line[{{-1, y1, 0},{x1, y1, 0}}]}]; line = Graphics3D[{Black, Line[{{x0, y0, f0},{x1, y1, 0}}]}]; xs = -f0 / gx0 + x0; ys = -f0 / gy0 + y0; xsline = Graphics3D[{Black, Line[{{xs, y0, 0},{x0, y0, f0}}]}]; ysline = Graphics3D[{Black, Line[{{x0, ys, 0},{x0, y0, f0}}]}]; xspoint = Graphics3D[{Black, Sphere[{xs, y0, 0}, 0.05]}]; yspoint = Graphics3D[{Black, Sphere[{x0, ys, 0}, 0.05]}];
Show[xyplane,func,plane,f0point,f0bar,x0bar,y0bar] (* RGBColor[168,206,234] *) Show[xyplane,plane,f0point,f0bar,x0bar,y0bar,x1bar,y1bar,line] Show[xyplane,root,plane]
X方向切線與XY平面的交點、Y方向切線與XY平面的交點,兩交點連線,得到交線。
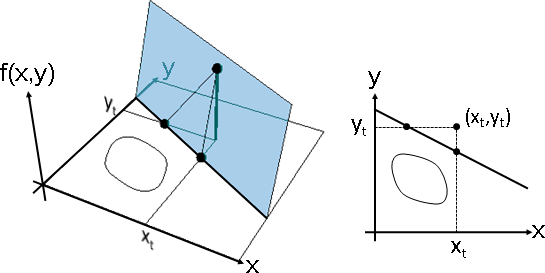
Show[xyplane,plane,f0point,f0bar,x0bar,y0bar,xsline,ysline,xspoint,yspoint] Show[xyplane,func,plane] (* ViewPoint -> {0, 0, -Infinity} *)
切面上有許多切線,可以作為前進方向;交線上有許多點,可以作為下一個x。牛頓法選擇了最短切線:垂直於交線。
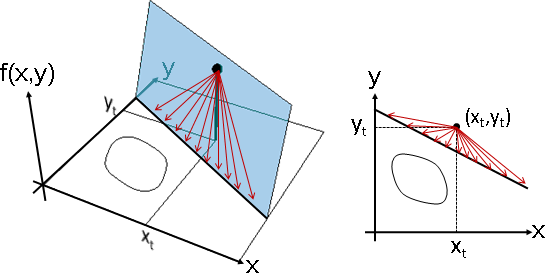
Show[xyplane,plane,f0point,f0bar,x0bar,y0bar]
最短切線一定是梯度方向。等高線的垂直方向。
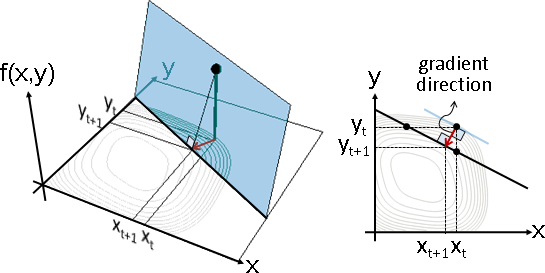
Show[xyplane,plane,levelset,f0point,f0bar,x0bar,y0bar,x1bar,y1bar,line] ContourPlot[f[x,y], {x, -1, 1}, {y, -1, 1}, Frame -> False, ContourShading -> None, Contours -> Table[i,{i,0,1,0.1}]]
接下來把上述概念寫成數學式子。
乘法推廣成點積。得到所有切線。
∇f(xₜ)ᵀ (xₜ - xₜ₊₁) = f(xₜ)
除法推廣成點積反運算(虛擬反矩陣)。得到最短切線。
∇f(xₜ) f(xₜ) ∇f(xₜ) f(xₜ)
(xₜ - xₜ₊₁) = ∇f(xₜ)ᵀ⁺ f(xₜ) = ———————————— = ——————————————
‖∇f(xₜ)‖² ∇f(xₜ)ᵀ ∇f(xₜ)
移項整理,提出xₜ₊₁。得到牛頓法公式。
∇f(xₜ) f(xₜ)
xₜ₊₁ = xₜ - ∇f(xₜ)ᵀ⁺ f(xₜ) = xₜ - ——————————————
∇f(xₜ)ᵀ ∇f(xₜ)
時間複雜度O(NT),N是變數數量,T是遞推次數。
演算法(ℝⁿ⇨ℝᵐ Newton's method)
牛頓法,推廣成多變量函數。
F′(xₜ)ᵀ (xₜ - xₜ₊₁) = F(xₜ) (xₜ - xₜ₊₁) = F′(xₜ)ᵀ⁺ F(xₜ) xₜ₊₁ = xₜ - F′(xₜ)ᵀ⁺ F(xₜ)
改寫成Jacobian matrix風格。
xₜ₊₁ = xₜ - J(xₜ)⁺ F(xₜ) where J(xₜ) = F′(xₜ)ᵀ
時間複雜度O(N³T),N是變數數量與函數數量較大者,T是遞推次數。
演算法(ℝ⇨ℝ secant method)
從頭複習一遍割線法吧。
座標(x₁, f(x₁))與(x₂, f(x₂))的割線,與座標軸相交之處,作為下一個x。
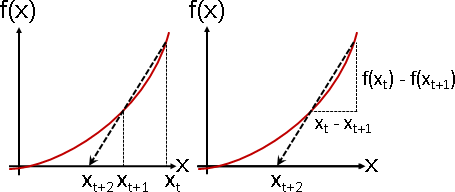
牛頓法是切線斜率f′(xₜ)。割線法是割線斜率sₜ。
Newton's method f′(xₜ) = f(xₜ) / (xₜ - xₜ₊₁) secant method ⎰ sₜ = (f(xₜ₋₁) - f(xₜ)) / (xₜ₋₁ - xₜ) ⎱ sₜ = (f(xₜ) - 0) / (xₜ - xₜ₊₁)
只有乘法,沒有除法。
⎰ sₜ (xₜ₋₁ - xₜ) = f(xₜ₋₁) - f(xₜ) ⎱ sₜ (xₜ - xₜ₊₁) = f(xₜ) - 0
二式移項整理,提出xₜ₊₁。
xₜ₊₁ = xₜ - f(xₜ) / sₜ
一式代入二式,得到割線法公式。
xₜ₊₁ = xₜ - f(xₜ) (xₜ₋₁ - xₜ) / (f(xₜ₋₁) - f(xₜ))
改寫成跨距風格。負負得正。
xₜ₊₁ = xₜ - f(xₜ) Δxₜ / Δfₜ where Δxₜ = xₜ - xₜ₋₁
Δfₜ = f(xₜ) - f(xₜ₋₁)
時間複雜度O(T),T是遞推次數。
演算法(ℝⁿ⇨ℝ secant method)
割線法,推廣成許多個輸入變數。
斜率推廣成梯度。割線推廣成割面。交點推廣成交線。
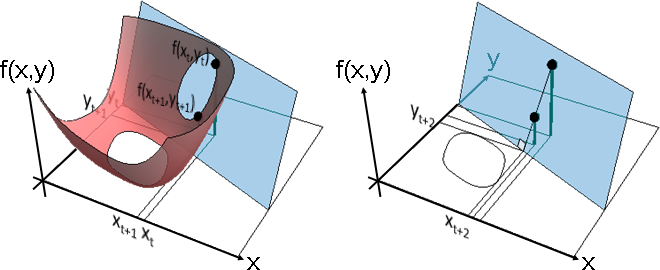
k[x_, y_] := Sqrt[(1.5*x*x*x)^2] + Sqrt[(2*y*y*y)^2] + 0.5*x*y - 0.05; f[x_, y_] := k[x + .4, y + .3]; x0 = .5 - .4; y0 = .65 - .3; f0 = f[x0,y0]; x1 = .425 - .4; y1 = .45 - .3; f1 = f[x1,y1]; dx = x0 - x1; dy = y0 - y1; df = f0 - f1; d = (dx ^ 2) + (dy ^ 2); gx1 = df * dx / d; gy1 = df * dy / d; g1 = (gy1 ^ 2) + (gx1 ^ 2); x2 = x1 - f1 * gx1 / g1; y2 = y1 - f1 * gy1 / g1; t[x_, y_] := gx1*(x-x1) + gy1*(y-y1) + f1; x0bar = Graphics3D[{Black, Line[{{x0, -1, 0},{x0, y0, 0}}]}]; y0bar = Graphics3D[{Black, Line[{{-1, y0, 0},{x0, y0, 0}}]}]; f0bar = Graphics3D[{Thickness[0.01], CapForm["Butt"], Black, Line[{{x0, y0, 0},{x0, y0, f0}}]}]; f0point = Graphics3D[{Black, Sphere[{x0, y0, f0}, 0.05]}]; x1bar = Graphics3D[{Black, Line[{{x1, -1, 0},{x1, y1, 0}}]}]; y1bar = Graphics3D[{Black, Line[{{-1, y1, 0},{x1, y1, 0}}]}]; f1bar = Graphics3D[{Thickness[0.01], CapForm["Butt"], Black, Line[{{x1, y1, 0},{x1, y1, f1}}]}]; f1point = Graphics3D[{Black, Sphere[{x1, y1, f1}, 0.05]}]; x2bar = Graphics3D[{Black, Line[{{x2, -1, 0},{x2, y2, 0}}]}]; y2bar = Graphics3D[{Black, Line[{{-1, y2, 0},{x2, y2, 0}}]}]; line = Graphics3D[{Black, Line[{{x0, y0, f0},{x2, y2, 0}}]}]; xyplane = Graphics3D[{Opacity[0], Polygon[{{-1,-1,0},{-1,1,0},{1,1,0},{1,-1,0}}]}, Boxed -> False (*, ViewPoint -> {0, 0, -Infinity}*) ]; func = Plot3D[f[x,y], {x, -1, 1}, {y, -1, 1}, PlotRange -> {-1, 1}, ClippingStyle -> None, Mesh -> None, PlotStyle->Opacity[0.8], RegionFunction -> Function[{x, y, z}, 0 <= z <= 1], ColorFunction -> (ColorData["CherryTones"][Rescale[#3, {-2, 2}]] &)]; plane = Plot3D[t[x,y], {x, -1, 1}, {y, -1, 1}, Mesh -> None, PlotStyle -> Opacity[0.8], ColorFunction -> (RGBColor[0,112,192] &), RegionFunction -> Function[{x, y, z}, 0 <= z <= 1]]; intersect = Plot3D[t[x,y]+0.02, {x, -1, 1}, {y, -1, 1}, Mesh -> None, PlotStyle -> Opacity[0.8], ColorFunction -> (RGBColor[0,112,192] &), RegionFunction -> Function[{x, y, z}, z >= f[x,y]+0.02]];
Show[xyplane,func,plane,intersect,x0bar,y0bar,f0bar,f0point,x1bar,y1bar,f1bar,f1point] (* RGBColor[168,206,234] *) Show[xyplane,plane,x0bar,y0bar,f0bar,f0point,x1bar,y1bar,f1bar,f1point,x2bar,y2bar,line]
兩點之間有許多割面。割線法選擇了最正割面:其交線垂直於兩點連線。
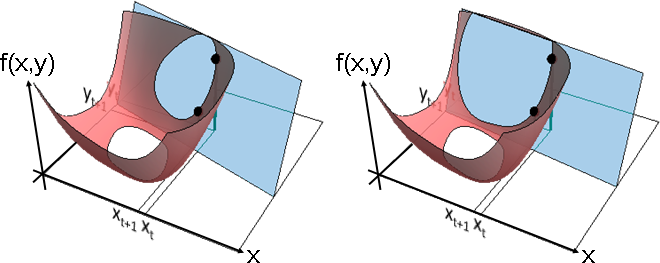
par = LinearSolve[{{x0, y0, 1}, {x1, y1, 1}, {x0 - 0.07, 0, 1}}, {f0, f1, 0}]; par = LinearSolve[{{x0, y0, 1}, {x1, y1, 1}, {x0 + 0.005, 0, 1}}, {f0, f1, 0}]; planebad = Plot3D[(par[[1]]*x)+(par[[2]]*y)+par[[3]], {x, -1, 1}, {y, -1, 1}, Mesh -> None, PlotStyle -> Opacity[0.8], ColorFunction -> (RGBColor[0,112,192] &), RegionFunction -> Function[{x, y, z}, 0 <= z <= 1]]; intersectbad = Plot3D[(par[[1]]*x)+(par[[2]]*y)+par[[3]]+0.02, {x, -1, 1}, {y, -1, 1}, Mesh -> None, PlotStyle -> Opacity[0.8], ColorFunction -> (RGBColor[0,112,192] &), RegionFunction -> Function[{x, y, z}, 1 >= z >= f[x,y]+0.02]]; Show[xyplane,func,planebad,intersectbad,x0bar,y0bar,f0bar,f0point,x1bar,y1bar,f1bar,f1point]
割面上有許多割線,可以作為前進方向;交線上有許多點,可以作為下一個x。割線法選擇了最短割線:垂直於交線。
Show[xyplane,plane,x0bar,y0bar,f0bar,f0point,x1bar,y1bar,f1bar,f1point]
接下來把上述概念寫成數學式子。
點積。得到所有割面。
sₜᵀ (xₜ₋₁ - xₜ) = f(xₜ₋₁) - f(xₜ)
點積反運算(虛擬反矩陣)。得到最正割面。
sₜᵀ = (f(xₜ₋₁) - f(xₜ)) (xₜ₋₁ - xₜ)⁺ = Δfₜ Δxₜ⁺
點積。得到所有割線。
sₜᵀ (xₜ - xₜ₊₁) = f(xₜ) where sₜᵀ = Δfₜ Δxₜ⁺
點積反運算(虛擬反矩陣)。得到最短割線。
(xₜ - xₜ₊₁) = sₜᵀ⁺ f(xₜ) = (Δfₜ Δxₜ⁺)⁺ f(xₜ) = Δxₜ Δfₜ⁺ f(xₜ)
移項整理,提出xₜ₊₁。得到割線法公式。
xₜ₊₁ = xₜ - Δxₜ Δfₜ⁺ f(xₜ)
然而割線法只會走一直線,往往走不到根。沒人使用割線法。
演算法(ℝⁿ⇨ℝᵐ secant method)
割線法,推廣成多變量函數。
xₜ₊₁ = xₜ - Δxₜ ΔFₜ⁺ F(xₜ)
一樣沒人用。
演算法(Broyden's method)
割線法改良版。不選擇最正割面,避免走一直線。
割線法寫成兩道式子,先改良第一式,再改良第二式。
⎰ Sₜᵀ = (F(xₜ₋₁) - F(xₜ)) (xₜ₋₁ - xₜ)⁺ = ΔFₜ Δxₜ⁺ ⎱ xₜ₊₁ = xₜ - Sₜᵀ⁺ F(xₜ)
一、改成遞推更新割面。用前一個割面,求後一個割面。
故意製造Sₜ₋₁。移項整理,提出Sₜ。得到割面遞迴公式。
最初的割面,設定成隨機梯度(隨便亂歪),或者第一點的切面的梯度(不會太歪)。
最初的割面,故意設定成歪的;之後的割面,故意保持是歪的。得以螺旋行進至根。
Sₜᵀ Δxₜ = ΔFₜ (Sₜ - Sₜ₋₁ + Sₜ₋₁)ᵀ Δxₜ = ΔFₜ (Sₜ - Sₜ₋₁)ᵀ Δxₜ + Sₜ₋₁ᵀ Δxₜ = ΔFₜ (Sₜ - Sₜ₋₁)ᵀ Δxₜ = ΔFₜ - Sₜ₋₁ᵀ Δxₜ (Sₜ - Sₜ₋₁)ᵀ = (ΔFₜ - Sₜ₋₁ᵀ Δxₜ) Δxₜ⁺ Sₜᵀ - Sₜ₋₁ᵀ = (ΔFₜ - Sₜ₋₁ᵀ Δxₜ) Δxₜ⁺ Sₜᵀ = Sₜ₋₁ᵀ + (ΔFₜ - Sₜ₋₁ᵀ Δxₜ) Δxₜ⁺
Δxₜ⁺ = Δxₜᵀ / ‖Δxₜ‖² = Δxₜᵀ / (Δxₜᵀ Δxₜ)
第一式改良完畢,得到計算公式。
⎰ Sₜᵀ = Sₜ₋₁ᵀ + (ΔFₜ - Sₜ₋₁ᵀ Δxₜ) Δxₜ⁺ ⎱ xₜ₊₁ = xₜ - Sₜᵀ⁺ F(xₜ)
移項的效果:前後兩個割面,梯度差異盡量小。
min ‖Sₜ - Sₜ₋₁‖² subject to Sₜᵀ Δxₜ = ΔFₜ
二、改成直接紀錄虛擬反矩陣。避免不斷計算虛擬反矩陣。
令Cₜᵀ = Sₜᵀ⁺。
Sₜᵀ Δxₜ = ΔFₜ Cₜᵀ ΔFₜ = Δxₜ (Cₜ - Cₜ₋₁ + Cₜ₋₁)ᵀ ΔFₜ = Δxₜ (Cₜ - Cₜ₋₁)ᵀ ΔFₜ + Cₜ₋₁ᵀ ΔFₜ = Δxₜ (Cₜ - Cₜ₋₁)ᵀ ΔFₜ = Δxₜ - Cₜ₋₁ᵀ ΔFₜ (Cₜ - Cₜ₋₁)ᵀ = (Δxₜ - Cₜ₋₁ᵀ ΔFₜ) ΔFₜ⁺ Cₜᵀ - Cₜ₋₁ᵀ = (Δxₜ - Cₜ₋₁ᵀ ΔFₜ) ΔFₜ⁺ Cₜᵀ = Cₜ₋₁ᵀ + (Δxₜ - Cₜ₋₁ᵀ ΔFₜ) ΔFₜ⁺
ΔFₜ⁺ = ΔFₜᵀ / ‖ΔFₜ‖² = ΔFₜᵀ / (ΔFₜᵀ ΔFₜ)
第二式改良完畢,得到計算公式。
⎰ Cₜᵀ = Cₜ₋₁ᵀ + (Δxₜ - Cₜ₋₁ᵀ ΔFₜ) ΔFₜ⁺ ⎱ xₜ₊₁ = xₜ - Cₜᵀ F(xₜ)
移項的效果:前後兩個割面,梯度的虛擬反矩陣差異盡量小。
min ‖Cₜ - Cₜ₋₁‖² subject to Cₜᵀ ΔFₜ = Δxₜ
時間複雜度O(NMT),N是變數數量,M是函數數量,T是遞推次數。
演算法(fixed-point iteration)
不動點遞推法,推廣成多變量函數。
函數和變數必須一樣多個。
xₜ₊₁ = xₜ + λ F(xₜ)
