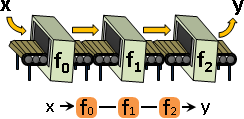
function network🚧
function network(computational graph)
函數:輸入多個數值,輸出一個數值。
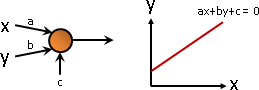
計算學家擅長線性函數、多項式函數。以下以一次函數為例。
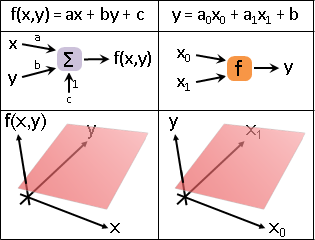
函數網路:形成網路。可以宏觀地視作一個函數。
計算學家擅長樹、有向無環圖。以下以分層圖為例。
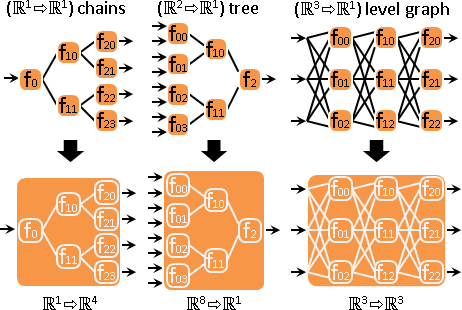
一次函數不斷串接,仍是一次函數。
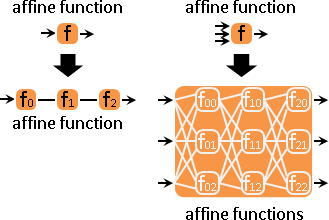
function network運算
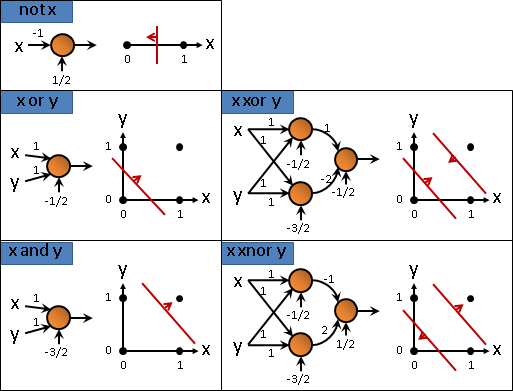
函數網路按理可以定義加減乘除微積運算,可以求根、求解、求極值,可以用於迴歸、內插、擬合、分群、分類。
不過這些運算仍在研究當中,尚未定義。
求值
函數:代入x,求得y。
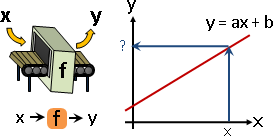
函數鏈:按照順序,每個函數各自求值。
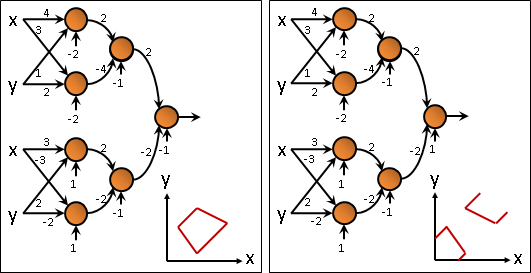
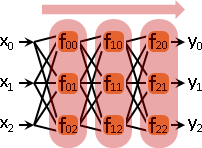
函數網路:按照層級順序、拓樸順序,每個函數各自求值。
求根
全部展開之後,等同於解一次方程組。目前沒有演算法。
最佳化
函數:一次函數,呈直線,極值在無限遠處,沒有討論意義。
話雖如此,但這裡還是介紹一下最佳化演算法,以鋪陳後文。
一次函數可以一次微分,適用梯度下降法。朝梯度方向走會上升、得極大值,朝梯度反方向走會下降、得極小值。
函數鏈:展開之後仍是一次函數。
沿總梯度方向走。梯度是「f(x)變化」和「x變化」的比值。總梯度是「f(...f(x))變化」和「x變化」的比值。梯度逐層連乘,得到總梯度。
另外介紹一個畫蛇添足的方法:最內層x走一步,每一層x也都跟著走一步。
梯度是「f(x)變化」和「x變化」的比值,乘以梯度估得外層步伐大小,除以梯度估得內層步伐大小。當f是一次函數、呈直線,則步伐大小精準無誤。
函數網路:由兩種情況混合而成。
一、多到一。多個函數的輸出,是同一個函數的輸入。
整體視作一個函數。每條路線分別統計總梯度。根據輸入維度,取得梯度維度。數學術語是partial derivative。
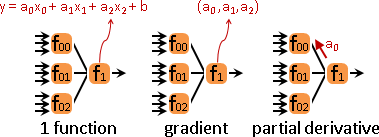
二、一到多。同一個函數的輸出,是多個函數的輸入。
一條路線視作一個函數。函數們相加合併。梯度們也跟著相加合併。數學術語是multiobjective optimization與scalarization。
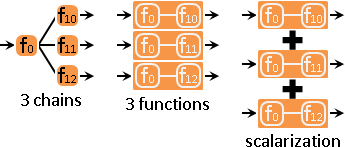
函數網路化作函數鏈,函數鏈化作函數,函數們相加合併,求得總梯度,實施梯度下降法。
一、任意多項式函數:函數用於複合再總和=函數的總和用於複合。窮舉每條路線,逐條合併函數=逆拓樸順序,逐層合併函數。
二、任意可微函數:函數的總和的梯度=函數的梯度的總和。窮舉每條路線,逐條合併梯度=逆拓樸順序,逐層合併梯度。
逐條合併化作逐層合併。數學術語是distributive law。
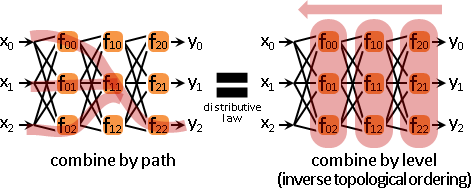
拓樸順序,求得每個函數的x值。逆拓樸順序,統計每個函數的總梯度。第一層函數各自沿總梯度方向走、得極大值。
內插
古代有一種做法叫做radial basis function network。
迴歸
函數:迴歸函數是一次函數,即是一次迴歸。
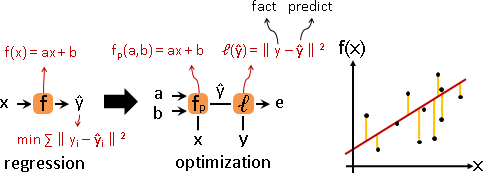
化作最佳化問題,實施梯度下降法。
函數末端接上平方誤差函數。函數的變數與係數,角色互調。
先前小節的各種性質,一次函數換成多項式函數,性質依然成立。平方誤差函數是多項式函數,最佳化依然堪用。
平方誤差函數是拋物線函數(凸函數)。誤差總和是拋物線函數總和,仍是拋物線函數。有唯一最小值,沒有鞍點,有公式解。
大量數據的最佳化演算法,衍生兩種版本offline和online,又叫做batch和stochastic。實務上使用online版本,優點是數據存取時間大幅降低,缺點是答案不太正確。
函數鏈:展開之後,仍是一次迴歸。
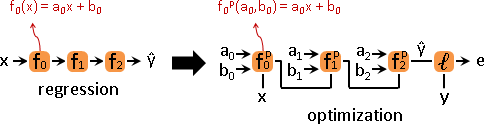
函數鏈展開、迴歸函數,兩邊的係數一一對應,顯然有解。函數鏈係數太多,導致多解。嘗試尋找其中一解。沿用梯度下降法:
正向求得每個函數的x值。逆向統計每個函數的總梯度。每個函數各自沿總梯度反方向走,求得每個函數的係數。
梯度下降法可以找到其中一解嗎?這是懸案!
若已知x值,則ab擁有唯一解。可是必須先利用ab才能求得每個函數的x值──雞蛋悖論,給x求ab,給ab求x。也許它們成對收斂,宛如EM algorithm,我不是很確定。【尚待確認】
函數網路:許多個一次迴歸。誤差合一,乍看相關,實則獨立。
梯度下降法此時又稱作「反向傳播法backpropagation」:
拓樸順序,求得每個函數的x值。逆拓樸順序,統計每個函數的總梯度。每個函數各自沿總梯度反方向走,求得每個函數的係數。
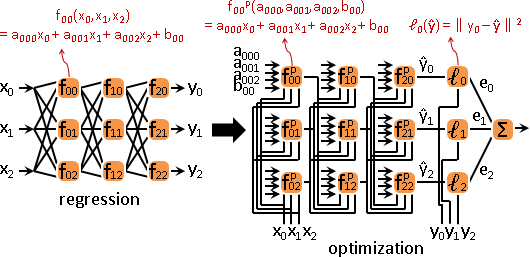
另一種觀點:每個函數各自迴歸。
逆拓樸順序,統計每個函數的總誤差。總誤差是後繼函數的誤差的加權總和,權重是後繼函數的梯度、亦是係數(一次函數)。
當權重均為正數,則總誤差是橢圓拋物面函數elliptic paraboloid。有唯一最小值,沒有鞍點,有公式解。【尚待確認】
正常情況下,權重不見得均為正數。後面章節將介紹一種特別的函數ReLU,當後繼函數梯度過小,強制權重為零。【尚待確認】
scalarization vs. 數據誤差總和。平方誤差函數的梯度是一次函數。【待補文字】
反向傳播法可以找到其中一解嗎?這是懸案!
根據一次方程組演算法「Gauss–Seidel iteration」,剛出爐的新梯度,馬上傳播,也許可以加快收斂速度。【尚待確認】
函數網路太深,總梯度巨大與渺小,浮點數溢位與歸零。解法是數據預先正規化:減去平均數、除以標準差,讓數值接近[-1,+1]。如此一來,迴歸函數的係數、亦是梯度,也自然而然正規化了。關鍵字vanishing gradient problem與batch normalization。
承上,scalarization,梯度總和也改成梯度平均數。
函數網路迴歸,幾何意義不明。也許是階層迴歸:每個函數,網羅總截距,實施總迴歸。【尚待確認】
順便補充一下。各筆數據的x值,一齊實施仿射變換(一次函數),平行、共線、凹凸保持不變。總迴歸的x值,這些性質完好如初。
擬合
函數網路方程式,幾何意義不明。點到它的距離,如何定義呢?
變換
函數網路就是對數據實施一連串變換。
一個有趣的觀點是摺紙:
一個有趣的觀點是流形: