clustering
同聲相應,同氣相求;水流濕,火就燥,雲從龍,風從虎。《易傳》
clustering
「分群」。所有數據進行分組,相似數據歸類於同一組,一筆數據只屬於某一組,每一組稱作一個「群集cluster」。
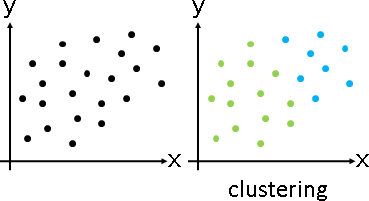
如何定義所謂的相似呢?方法很多:距離越近,推定為越相似;鄰居越密集,推定為越相似。
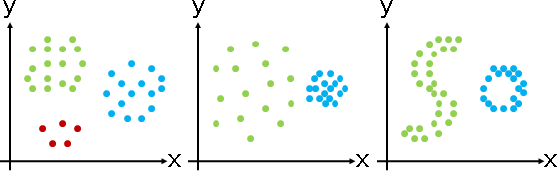
分群演算法的基本原理,一類是近朱者赤、近墨者黑,不斷將數據重新分組;另一類是不斷切割群集,表示成樹狀圖。
clustering
同聲相應,同氣相求;水流濕,火就燥,雲從龍,風從虎。《易傳》
clustering
「分群」。所有數據進行分組,相似數據歸類於同一組,一筆數據只屬於某一組,每一組稱作一個「群集cluster」。
如何定義所謂的相似呢?方法很多:距離越近,推定為越相似;鄰居越密集,推定為越相似。
分群演算法的基本原理,一類是近朱者赤、近墨者黑,不斷將數據重新分組;另一類是不斷切割群集,表示成樹狀圖。
partitional clustering
演算法(k-means clustering)(Lloyd–Max algorithm)
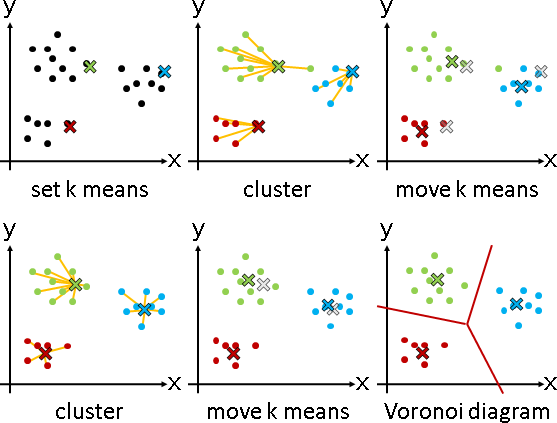
一、群集數量推定為K,隨機散佈K個點作為群集中心(常用既有的點)。
二、每一點分類到距離最近的群集中心(常用直線距離)。
三、重新計算每一個群集中心(常用平均數)。
重複二與三,直到群集不變、群集中心不動為止。最後形成群集中心的Voronoi diagram。
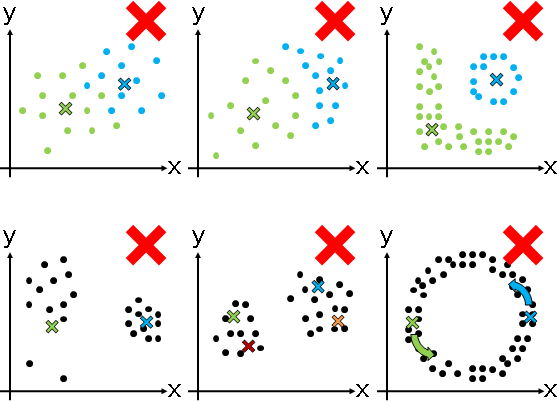
時間複雜度O(NKT),N是數據數量,K是群集數量,T是重複次數。我們無法預先得知群集數量、重複次數。數據分布情況、群集中心的初始位置,都會影響重複次數,運氣成份很大。
缺點是群集不能重疊、群集分界不能是曲線和折線、極端數據容易使群集中心偏移、一開始難以決定群集數量與群集中心、數據分布呈甜甜圈時群集中心可能永不停住。
演算法(k-means++ clustering)
改良k-means clustering第一個步驟。
逐一設定K個群集中心。計算每一個點到已設定的群集中心的最短距離,以最短距離的n次方作為機率大小,決定下一個群集中心。距離越遠,機率越大。
0次方是k-means,等同隨機散佈。2次方是k-means++。∞次方是farthest-point traversal,等同找最遠點。次方越高,效果越好,計算越久。
優點是群集中心比較分散,不容易擠在一起。
演算法(Linde–Buzo–Gray clustering)

首先隨機設定一個群集中心(常用平均數)。不斷讓群集中心往反方向分裂成兩倍數量(常用少量移動、群集內最遠點對),並且重新實施k-means clustering。
優點是不用煩惱群集中心的初始位置。
演算法(k-nearest neighbor clustering)
每一點各自找到距離最近的K個點作為鄰居,採多數決歸類到群集。如果距離超過了自訂臨界值,找不足K個鄰居,就替該點創造一個新的群集。
優點是不用煩惱群集數量,缺點是群集鬆散。
演算法(shared nearest neighbors clustering)
每一點各自找到距離最近的K個點作為鄰居。當a和b彼此都是鄰居,或者a和b至少有K'個相同鄰居(K'是自訂臨界值,K' ≤ K),則a和b歸類到同一個群集。
優點是不用煩惱群集數量、群集形狀。
演算法(DBSCAN)
實務上效果最好的分群演算法。
hierarchical clustering
演算法(nearest neighbor chain)
演算法(Minimum spanning tree)
運用「minimum spanning tree」的瓶頸性質。實施Kruskal's algorithm,每次新添的邊,若距離不超過threshold,則邊的兩端就視作同一個群集。
演算法(minimum cut tree)
運用「minimum cut tree」的瓶頸性質。然而最小割是距離最近而不是距離最遠,無法用於分離群集,所以就把一個割的權重修改為:
∑ w(i, j) ÷ min(|S|, |S|) i∈S j∈S
classification
方以類聚,物以群分,吉凶生矣。《易傳》
classification
分群:未知群集(類別),找到群集(類別)。某些演算法會順便找到分界線,例如k-means clustering。
分類:已知群集(類別),找到分界線。
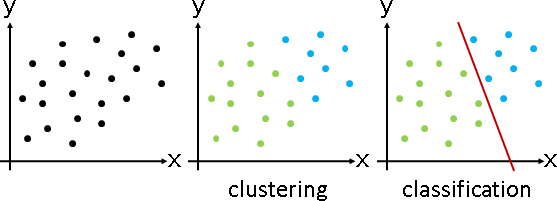
群聚與隔離,一體兩面。相似數據群聚,相異數據也漸漸隔離。最後出現了群聚中心,也出現了隔離界線。
不同類別的數據稍微黏在一起,仍然可以找到大致的分界線。如果不同類別的數據幾乎混在一起(例如太極圖案),那麼分界線沒有任何意義。
找到分界線之後,對於一筆新的數據,就利用分界線來決定其類別──這就是classification的用途。
如何應用classification?
classification應用十分廣泛,是世上最實用的演算法之一。
比如說,讓電腦揀土豆。一粒土豆是一筆數據,(土豆重量,土豆顏色)是其數值。
首先,取一百粒土豆,個別以儀器測量其數值,然後人工進行分類,分為良與劣兩類。這些數據全數輸入到電腦當中。
接著,利用任何一種classification的演算法,找到良與劣的分界線。
最後,每一粒新產的土豆,以儀器自動測量其數值,再用演算法判斷數值在分界線的哪一側,就能判斷出土豆的良劣了。
應用classification需要考量的關鍵點
這整套自動辨識的流程當中,我們需要考量的有:
一、我們要挑選哪些特徵?例如重量、顏色、形狀等等。
二、我們要如何將特徵化為數值?例如用磅秤得到重量數值,用攝影機得到顏色數值,用影像處理演算法得到形狀數值。
三、我們要取哪些土豆當作樣本?這跟統計學有關。
四、我們如何提升分類的正確率?這跟統計學有關。
五、我們如何從分界線當中發現新的性質?例如重量越重則土豆越優、形狀越圓則土豆越優之類的。
linear classification
linear classification
以直線當作分界線。
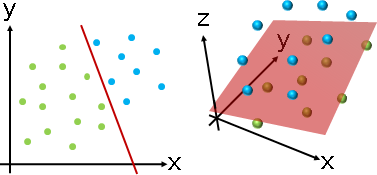
數據的維度可以推廣到三維以上,此時分界線就成了分界面、分界體等等。分界物是數據維度減少一維(hyperplane)。
雖然可以視作計算幾何問題,但是當維度太高的時候,計算相當複雜,難以快速求得精確解。因此採用了數值分析的套路。
演算法(perceptron)
不考慮分界線到數據的距離。分界線只要分開數據即可。
分界線是一條直線ax+by+c=0。想判斷一筆數據(x₁,y₁)位於分界線的哪一側,就將(x₁,y₁)代入直線方程式,計算ax₁+by₁+c,大於零就是在正側,小於零就是在反側,等於零就是在分界線上。
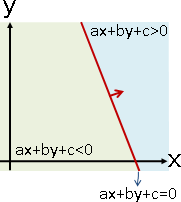
每一筆數據都代入計算,不見得都能正確分類。我們必須調整分界線的位置,也就是調整a b c三個參數。該如何調整才好呢?我們可以利用最佳化的思維。
設定誤差是「正確結果、分類結果不相符的數據筆數」,誤差越小越好。為了方便統計誤差,將結果定為數值0和1。正確結果:數據共兩類,第一類數據定為0,第二類數據定為1。分類結果:數據在反側定為0,數據在分界線上、在正側定為1。
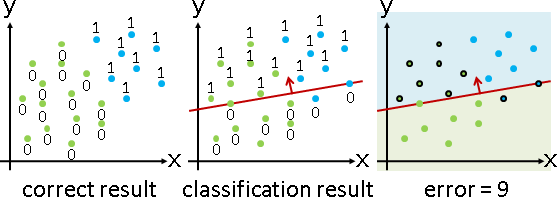
如此一來,統計誤差,只需數值運算、無需邏輯運算。正確結果和分類結果先相減再平方,等於0即相符,等於1即不相符。
0和1顛倒設定也沒關係,a b c的計算結果多了負號而已。
N 2 ∑ [gᵢ - u(axᵢ+byᵢ+c)] i=1 gᵢ : correct result of data i (0 or 1) u(axᵢ+byᵢ+c): classified result of data i (0 or 1) u : unit step function (0 or 1)
最佳化演算法採用gradient descent:朝梯度方向走。首先推導梯度,也就是分別對a b c三個變數進行偏微分:
∂ N 2
—— ∑ [gᵢ - u(axᵢ+byᵢ+c)] = ∑ [gᵢ - u(axᵢ+byᵢ+c)] ⋅ -2xᵢ
∂a i=1
= ∑ errorᵢ ⋅ -2xᵢ
∂ N 2
—— ∑ [gᵢ - u(axᵢ+byᵢ+c)] = ∑ [gᵢ - u(axᵢ+byᵢ+c)] ⋅ -2yᵢ
∂b i=1
= ∑ errorᵢ ⋅ -2yᵢ
∂ N 2
—— ∑ [gᵢ - u(axᵢ+byᵢ+c)] = ∑ [gᵢ - u(axᵢ+byᵢ+c)] ⋅ -2
∂c i=1
= ∑ errorᵢ ⋅ -2
【尚待確認:δ(x)跑哪去了?】
一開始a b c設定成任意值。a b c往梯度方向移動,朝最小值前進:
⎡ a₀ ⎤ ⎡ 0 ⎤
⎢ b₀ ⎥ = ⎢ 0 ⎥ 一開始a b c設定成任意值,例如設定成0。
⎣ c₀ ⎦ ⎣ 0 ⎦
⎡ aₜ₊₁ ⎤ ⎡ aₜ ⎤ ⎡ ∑ errorᵢ ⋅ -2xᵢ ⎤
⎢ bₜ₊₁ ⎥ = ⎢ bₜ ⎥ - ⎢ ∑ errorᵢ ⋅ -2yᵢ ⎥ ⋅ step
⎣ cₜ₊₁ ⎦ ⎣ cₜ ⎦ ⎣ ∑ errorᵢ ⋅ -2 ⎦
⎡ aₜ ] ⎡ ∑ errorᵢ ⋅ xᵢ ⎤
= ⎢ bₜ ] + ⎢ ∑ errorᵢ ⋅ yᵢ ⎥ ⋅ 2 ⋅ step
⎣ cₜ ] ⎣ ∑ errorᵢ ⎦
通常會把2併入步伐大小step。或者一開始設定誤差函數多乘一個1/2,來把2消掉。
公式非常簡潔!這就是為什麼使用這種誤差設定方式、使用gradient descent的原因。這是前人努力試驗出來的最簡潔的方式。
當數據可分為兩半,則誤差呈單峰函數,gradient descent不會卡在局部極值。【尚待確認】
換句話說,當數據可分為兩半,而且步伐大小適中(太小導致攤在山腰、太大導致越過山頂),則此演算法一定可以找到正確的分界線。當數據不可分為兩半,則此演算法毫無用武之地。
「一筆數據代入直線方程式」這件事,通常畫成理工味道十足的圖。這個東西有個古怪名稱叫做perceptron:
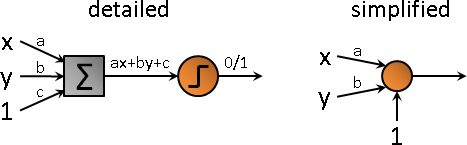
所有輸入乘上權重、相加起來,經過unit step function,最後輸出0或1(也有人輸出-1或+1)。
UVa 11289 ICPC 3581
演算法(support vector machine)
考慮分界線到數據的距離。分界線位於正中央,兩類數據相隔越遠越好。準確來說,分界線到兩類數據的最短距離均等、最短距離越大越好。
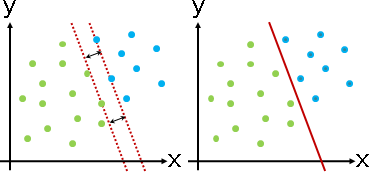
舉例來說,二維的情況下,兩類數據各自求凸包,分界線是凸包之間最近點對的中垂線,或者分界線平行於凸包上某一條邊。
但是當維度太高的時候,難以計算凸包、中垂超平面。只好採用數值分析的套路。
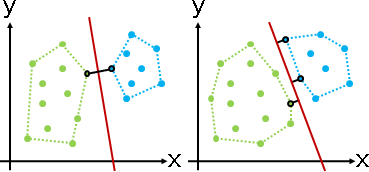
分界線是一條直線ax+by+c=0。一筆數據(x₁,y₁)到分界線的距離,就是將(x₁,y₁)代入點與直線距離公式,計算(ax₁+by₁+c) / sqrt(a²+b²)。距離有正負號,大於零就是在正側,小於零就是在反側,等於零就是在分界線上。
間距線是兩條直線ax+by+c=1和ax+by+c=-1(截距縮放為1)。間距線到分界線的距離,就是將間距線上任意一點代入點與直線距離公式。如此便得到半個間距。
每一筆數據到分界線的距離,必須大於等於半個間距。每一筆數據也必須選對邊。
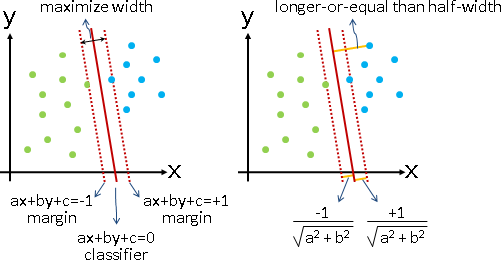
數據可能無法順利分成兩半。約束最佳化改成了多目標最佳化,允許漏網之魚。regularization:間距盡量大、大於半個間距的數據數量盡量多。
為了方便判斷距離,數據標記為-1和+1(本應是0和1)。為了避免除以零,改為最小化間距的倒數(本應是負數)。為了方便最佳化,再取平方變成凸函數。
s
classifer: px+qy+r=0 margin: px+qy+r=±s half-width: ———————————
sqrt(p²+q²)
let a = p/s, b = q/s, c = r/s, remove variable s.
1
classifer: ax+by+c=0 margin: ax+by+c=±1 half-width: ———————————
sqrt(a²+b²)
1 axᵢ+byᵢ+c 1
max ——————————— subject to ——————————— ⋅ gᵢ ≥ ——————————— for all i
sqrt(a²+b²) sqrt(a²+b²) sqrt(a²+b²)
1
max ——————————— subject to (axᵢ+byᵢ+c)⋅gᵢ ≥ 1 for all i 約束最佳化
sqrt(a²+b²)
min α⋅(a²+b²) + ∑ max(0, 1 - (axᵢ+byᵢ+c)⋅gᵢ) (α ≥ 0) 多目標最佳化
此式子的最佳化演算法是sequential minimal optimization,請讀者自行查詢。
inlier / outlier
真實世界的數據並非完美,常有例外。
無彈性的定義:全部數據分為inlier和outlier;inlier是分對的數據,outlier 是分錯的數據。
有彈性的定義:全部數據分為inlier和outlier;inlier是距離分界線太近的數據、以及分對的數據,outlier是距離分界線太遠又分錯的數據。
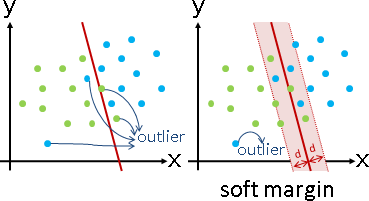
順帶一提,當數據無法分兩半,常見的手法是:無視彈性範圍內的數據,並且限制其數量上限。可以透過regularization處理。
演算法(AdaBoost)(adaptive boosting)
實施分類演算法,分錯的數據,複製並增加其數量,再繼續實施分類演算法。這使得誤差大幅增加,使得分界線大幅靠近分錯的數據,進而迅速減少分錯的數據。
增加倍率:分對的數量除以分錯的數量。數量不必是整數。
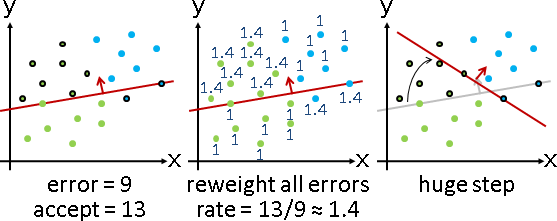
AdaBoost好處多多。分類過程中,分界線的移動步伐變大了,提早找到正確分界線。分類結束後,每筆數據的數量,可以看成是出錯程度,可依此判斷outlier。分類結束後,如果數據無法正確分兩半,就以各回合的分界線的平均,推定是最理想的分界線。
AdaBoost儘管缺乏理論根據,儘管名字怪異,卻非常實用。
演算法(gradient boosting)
實施分類演算法,得到分界線。然後不斷微調分界線。
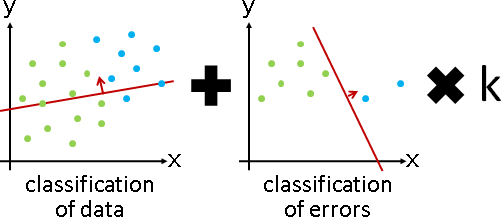
挑出分錯的數據,另外實施分類演算法,得到微調用的分界線。當前分界線,加上微調用的分界線,完成一次微調。重複這些步驟,直到分錯的數據足夠少,或者是誤差總和足夠小。
微調用的分界線,可以乘上倍率。注意到倍率太大就不是微調了,而倍率太小就失去調整效果了。
概念宛如gradient descent,故取名gradient。概念宛如adaptive boosting,故取名boosting。
其他問題
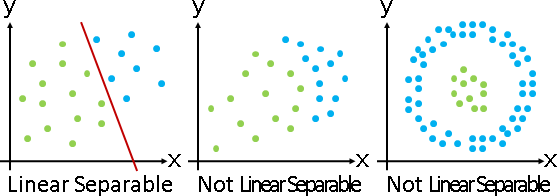
linear separability:一條分界線,能夠分對所有數據嗎?
P問題。演算法是一次規劃。
當維度是常數,還是P問題,演算法是試誤法(窮舉點對作為分界線)、凸包交集。
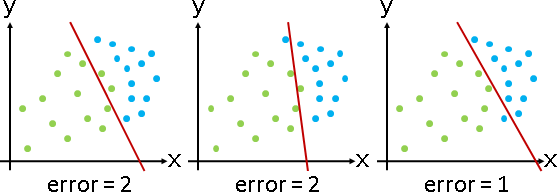
0/1 loss minimization:一條分界線,令分錯的數據盡量少。
NP-complete問題。只好用regularization得到近似解。
當維度是常數,變成P問題,演算法是試誤法(窮舉點對作為分界線)。
當數據可以分兩半,變成P問題,演算法是一次規劃、perceptron。
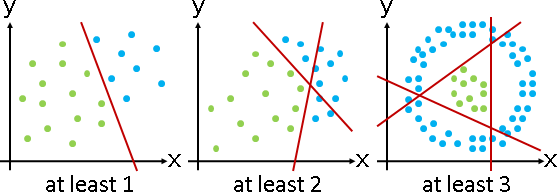
Vapnik–Chervonenkis dimension:最少需要幾條分界線?
介於P與NP-complete之間。我不知道演算法。
當維度是常數,還是一樣難。
hierarchical classification
hierarchical classification
數據往往無法順利地一分為二,數據往往有兩種以上類別,先前的演算法往往毫無用武之地。
解法是階層架構、樹狀圖,稱作「決策樹decision tree」。
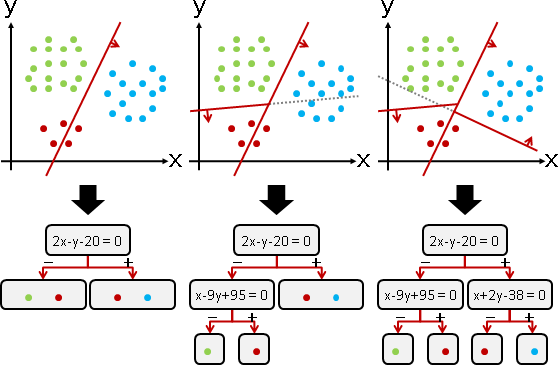
另一種解法是一連串測試,稱作「蕨fern」。奇葩的名稱。蕨是決策樹的簡易版本:同一層節點,共用同一條分界線。
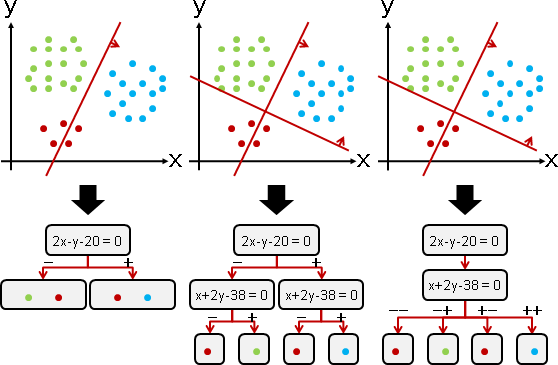
演算法(decision tree)(classification tree)
援引「k-dimensional tree」的精神,用於分類。
貪心法。選擇分類效果最好的分界線,將數據分兩份。兩份數據分頭遞迴下去,直到不同類別的數據都被分開為止。
每次選擇分界線時,窮舉各種分界線走向(窮舉每個維度),窮舉各種分界線位置(窮舉每筆數據),從中找到分類效果最好者。
分界線兩側的數據,分頭計算混亂程度。兩個混亂程度,求加權平均數(權重是數據數量),作為分類效果。數值越低,效果越好。
混亂程度有兩種評估方式:一、Gini impurity:各個類別的數據比例,兩兩相乘(不乘自身),總和越小越好;二、information gain:各個類別的數據比例,求熵,總和越小越好。
兩種方式都沒有科學根據。通常使用第一種,比較好算。
不採用清澈程度、卻採用混亂程度,這般迂迴曲折,是因為清澈程度不好揣摩、而混亂程度容易具體實現。
Gini impurity: ∑ [ p(Ci) p(Cj) ] = 1 - ∑ [ p(Ci) p(Ci) ]
i≠j i
information gain: - ∑ [ p(Ci) log₂ p(Ci) ]
i
Ci :第i種類別的數據集合。
p(Ci):第i種類別的數據數量,除以所有類別的數據總數量。也就是比例。
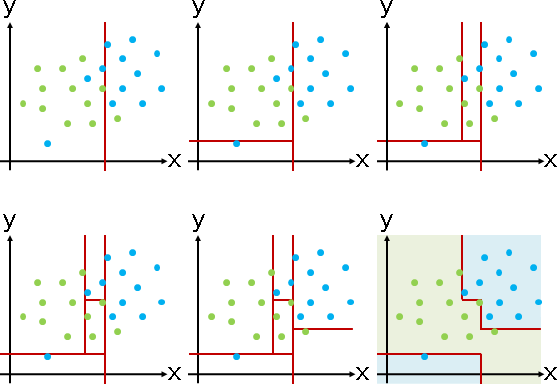
因為是貪心法,所以分界線配置往往不是最精簡的、分界線數量往往不是最少的。
時間複雜度O(DNNN)。運用「掃描線」則是O(DNNlogN)。當運氣很好,數據的數量每次都剛好對半分,則是O(DNlog²N)。
一、窮舉D個維度、窮舉N筆數據,找到分界線。 二、針對一條分界線,判斷每筆數據位於哪一側,需時O(N)。 三、兩側數據,分頭計算C種類別之間的混亂程度,需時O(C)。C通常視作常數。 四、分界線數量最少0條(數據只有唯一一種類別)。 分界線數量最多N-1條(每次都分出一筆數據)。 分界線數量就是節點數量。
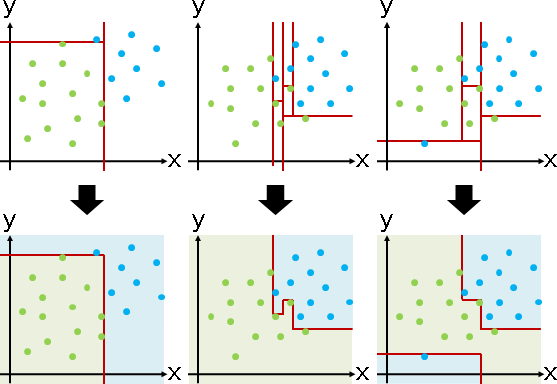
預先設置一些分界線,每次找分界線時,就考慮這些分界線。如此一來,分界線就不必是鉛直線、水平線,分界線可以是任意圖形。甚至多條分界線可以合成一種分界線。
當數據有兩種以上類別,先運用linear classification,兩兩之間求分界線;再運用hierarchical classification,選取適當的分界線,建立階層架構。
演算法(random forest)
選擇分界線時,改為隨機窮舉一小部分,可以省時。
接著,製造大量的樹,刪除相似的樹。多數決。就這樣子。
隨機的副作用是分不乾淨。不過為了避免overfitting,也就沒必要分乾淨。而多數決不但抑制了副作用,同時也改良了分界線。
實務上效果最好的分類演算法。
演算法(random ferns)
樹改成蕨。可以省時。可以省程式碼。
fitting
玉不琢,不成器;人不學,不知道。《禮記》
fitting
「擬合」就是用一種幾何元件,盡量符合手邊的一堆數據。
幾何元件習慣寫成方程式,因而稱作「擬合方程式」。
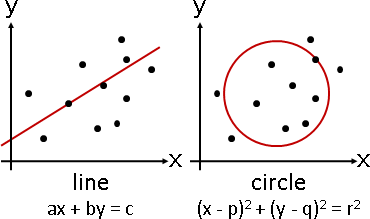
幾何元件可以是直線、平面、曲線、曲面、……。
甚至可以自創造型,但是必須考慮如何統計誤差。

error(loss)
強硬地用方程式符合數據,就會有「誤差」。
一筆數據的誤差,一般採用數據與擬合方程式的最短距離平方(平方誤差)。所有數據的誤差,就是最短距離平方總和。
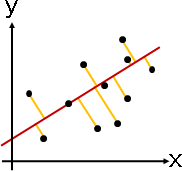
最佳化
運用最佳化演算法,求得誤差最小值,求得擬合方程式的係數。
擬合方程式 L: ax + by + c = 0
數據 (2,3) ... (7,8)
代數符號 (x₁,y₁) ... (xɴ,yɴ)
點與直線的距離公式
|ax + by + c|
d(x,y) = —————————————
√a² + b²
每筆數據的平方誤差
(a⋅2 + b⋅3 + c)² (a⋅7 + b⋅8 + c)²
———————————————— ... ————————————————
a² + b² a² + b²
代數符號
d(x₁,y₁)² ... d(xɴ,yɴ)²
所有數據的誤差總和
(a⋅2 + b⋅3 + c)² (a⋅7 + b⋅8 + c)²
———————————————— + ... + ————————————————
a² + b² a² + b²
代數符號
e(a,b,c) = d(x₁,y₁)² + ... + d(xɴ,yɴ)² = ∑ d(xᵢ,yᵢ)²
令e(a,b,c)越小越好。
選定一個最佳化演算法,求出e(a,b,c)的最小值,求出此時abc的數值,
就得到擬合方程式f(x)。
延伸閱讀:方程式的寫法
方程式有兩種寫法:隱方程式implicit equation、顯方程式explicit equation。進階寫法:參數方程式parametric equation。
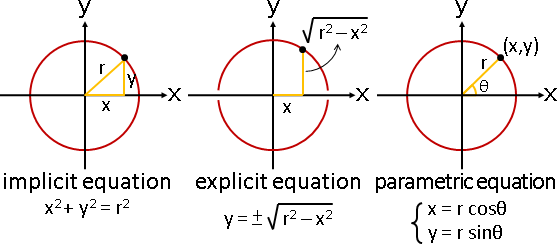
擬合時,通常使用顯方程式,方便推導最短距離公式。無法推導最短距離公式的時候,可以改用參數方程式,三分法求極值。
延伸閱讀:迴歸與擬合
迴歸:用(顯)函數符合函數點,誤差是截距平方。
擬合:用(隱)方程式符合數據,誤差是最短距離平方。
擬合方程式無須滿足函數定義,造型隨意,例如鉛直線、線段。
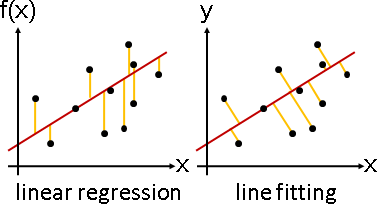
polynomial fitting
line fitting / plane fitting
「直線擬合」與「平面擬合」。擬合方程式是直線、平面。
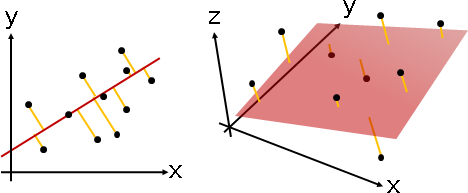
性質特殊,不需要最佳化演算法,直接推導公式解。
每筆數據,套用「點與直線的距離公式」求得最短距離,累計最短距離的平方和。
直線 ax + by + c = 0 二維數據 (x₁,y₁) ... (xɴ,yɴ) 每筆數據與直線的最短距離平方總和,越小越好。 minimize ∑ (axᵢ + byᵢ + c)² / (a² + b²) 不失一般性,令 a² + b² = 1。 minimize ∑ (axᵢ + byᵢ + c)² subject to a² + b² = 1
先解常數項。
先解常數項c。極值位於一次微分等於零的地方。
solve ∑ 2 (axᵢ + byᵢ + c) = 0
答案是X座標平均數、Y座標平均數,兩者分別乘上係數,相加,變號。
∑ axᵢ + ∑ byᵢ
c = - ————————————— = - ax̄ - bȳ
N
其中
∑xᵢ x₁+...+xɴ ∑yᵢ y₁+...+yɴ
x̄ = ——— = ————————— , ȳ = ——— = —————————
N N N N
再解係數。
再解係數a b。c代入原式。 minimize ∑ (axᵢ + byᵢ - ax̄ - bȳ)² subject to a² + b² = 1 等價於每筆數據預先減去平均數。 minimize ∑ (a(xᵢ - x̄) + b(yᵢ - ȳ))² subject to a² + b² = 1 minimize ∑ (ax̃ᵢ + bỹᵢ)² subject to a² + b² = 1 改寫成矩陣格式。x̃ᵢ ỹᵢ併成矩陣X̃,a b併成向量w。 minimize ‖X̃ᵀw‖² subject to ‖w‖² = 1 根據本站文件「homogeneous linear equations」, 答案是X̃X̃ᵀ的最小的特徵值的特徵向量! X̃X̃ᵀ w = λ w X̃X̃ᵀ稱作維度的共變異矩陣。 X̃X̃ᵀ又剛好是每筆數據的二次動差矩陣的總和。
係數:數據預先減去平均數。維度的共變異矩陣,最小的特徵值的特徵向量。
常數項:數據平均數,各個座標分別乘上係數,相加,變號。
另外提供二維數據的公式解。
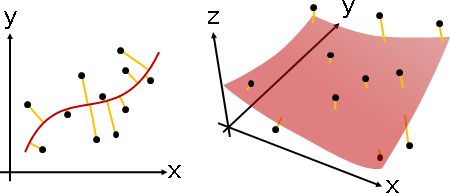
curve fitting / surface fitting
「曲線擬合」與「曲面擬合」。擬合方程式是曲線、曲面。
Plot3D[x*x + y*y + x*y + x - y, {x, -2, 2}, {y, -2, 2}, PlotRange -> {-15, 15}, Boxed -> False, Axes -> False, Mesh-> None, ColorFunction -> (ColorData["CherryTones"][Rescale[#3, {-3, 3}]] &) ]
古代有一種做法叫做principal curve。我沒有研究。
inlier / outlier
真實世界的數據並非完美,常有例外。
無彈性的定義:全部數據分為inlier和outlier;inlier是位在擬合方程式上面的數據,outlier是不在擬合方程式上面的數據。
有彈性的定義:全部數據分為inlier和outlier;inlier是距離擬合方程式夠近的數據,outlier是距離擬合方程式太遠的數據。

outlier導致擬合方程式易位。感覺類似:有人成績特別低,大幅拉低平均,無法正確反映大家的成績。

我們必須預先剔除outlier,再進行擬合。
演算法(RANSAC)(random sample consensus)
區分inlier和outlier的演算法非常簡單。
一、設定彈性寬度D。 二、隨機挑出K筆數據,只用這K筆數據擬合,得到擬合方程式。 K可以自由設定,不必很大。 如果擬合方程式是直線,1筆不夠形成直線,可以設定成2筆。 如果擬合方程式是複雜曲線,就多幾筆。 三、根據此擬合方程式,計算共有多少個inlier和outlier。 四、重複上述步驟T次。 從中找到inlier最多、outlier最少的情況,推定為正解。 T可以自由設定。
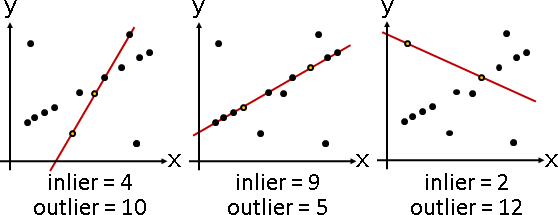
inlier通常較多、outlier通常較少。隨機挑出數據,容易挑到inlier,容易形成inlier的擬合方程式──此即RANSAC的精髓。
RANSAC儘管缺乏理論根據,儘管名字怪異,卻非常實用。
RANSAC只可用於區分inlier和outlier,不可用於求得擬合方程式(除非彈性寬度是零)。RANSAC只挑出少數數據,誤差總和不對,擬合方程式不對。正確的流程是:實施RANSAC,刪除outlier,保留inlier,重新實施擬合,更加符合數據!
演算法(Theil–Sen estimator)
《Optimal slope selection via expanders》
找到所有兩點連線的斜率的中位數。點線對偶,所有直線的所有交點的X座標中位數。時間複雜度O(NlogN)。
hierarchical regression
hierarchical regression
迴歸比擬合更常見,因此這裡介紹迴歸演算法。
演算法(regression tree)
決策樹,末梢各自迴歸。
混亂程度的評估方式:一、兩堆數據的函數值,奇異值總和越小越好;二、兩堆數據各自迴歸,誤差平均數越小越好。
不斷分割節點,直到誤差總和足夠小,或者節點數量足夠多。
演算法(gradient boosting regression tree)
首先製造一棵迴歸樹。計算每筆數據的誤差,以誤差製造一棵新的迴歸樹。
當前所有迴歸樹的迴歸結果總和(或者加權平均數),作為迴歸結果,進一步得到新的誤差。
不斷以誤差製造迴歸樹,直到誤差總和足夠小,或者迴歸樹數量足夠多。
優缺點宛如random forest。
演算法(XGBoost)
各式各樣的細部改良。
實務上效果最好的迴歸演算法。
model selection
model selection
「模型選擇」。選擇擬合方程式、誤差函數、演算法。追加約束條件、追加最佳化目標。諸如此類。
困境:現實世界當中,我們對數據一知半解、甚至一無所知,我們無法預知哪種選擇較佳。
解法:一一試驗、碰碰運氣,別無他法。
optimization
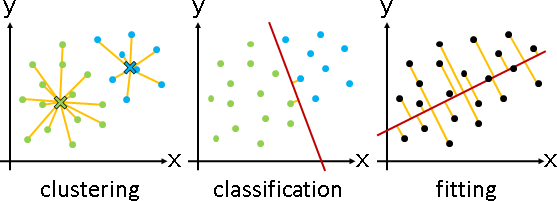
以最佳化的觀點來看,分群分類擬合,差別僅只於誤差函數:
clustering:最大距離盡量小 classification:最小距離盡量大 fitting:距離平方和盡量小
三者都是針對距離進行最佳化。函數輸入是一個點集合(所有數據)、幾個數值(擬合方程式的參數)。函數輸出是一個數值(誤差總和)。
更換一下誤差函數,同一個最佳化演算法可以解決所有問題。
quadratic optimization
誤差函數習慣設計成二次函數:
可微函數:處處有著唯一的梯度。可以使用梯度下降法。 凸函數:有著唯一的極值。可以分析時間複雜度。 二次函數:同時是可微函數與凸函數。可以推導梯度公式、甚至是極值位置公式。
距離平方總和適合作為誤差函數,容易最佳化。
點到點距離、點到直線距離,都是凸函數。平方之後,則是二次函數。二次函數相加,仍是二次函數。距離平方總和是二次函數。
model training
model training
「模型訓練」。收集數據,實施擬合、分群、分類、……。
困境:現實世界當中,數據多到爆炸,梯度下降法得跑一輩子。
解法:逐次讀取新數據,即時微調擬合結果,做多少算多少。
演算法(stochastic hill climbing)
以登山法求得擬合方程式的係數。
一筆數據:
多筆數據,最佳化演算法衍生兩種版本:
offline(batch):實施一次最佳化演算法,每一步都要處理所有數據。 online(stochastic):實施多次最佳化演算法,一次處理一筆數據(或者一批數據)。
offline版本是正確做法。online版本不太正確,但是可以節省存取時間,是I/O-efficient algorithm的經典範例。實務上大家使用online版本!
機器學習領域當中,這兩個版本又稱作batch和stochastic。batch原意是一口氣讀取大量輸入。stochastic原意是隨機過程。
演算法(stochastic gradient descent)
當誤差函數可以對各個係數偏微分,那麼可以使用梯度下降法。
一筆數據,得到一個誤差函數;所有數據,得到誤差函數總和。
offline針對誤差函數總和。online一次只看一個誤差函數,整個過程宛如四處找坑跳。當數據通通貼近擬合方程式,那麼每個坑通通貼近極值位置,隨便跳都中。收集巨量數據,中獎機會更穩定。
model validation
model validation
「模型驗證」。擬合之後,累計所有數據的誤差總和。誤差總和越小,表示數據越穩健,也表示演算法越有效。
困境:現實世界當中,數據往往不精準,導致擬合結果不精準,導致誤差總和不精準。數據越多,誤差總和越不精準。
解法:先取部分數據做擬合(訓練),再取部分數據算誤差(測試),讓誤差總和的bias和variance減少,讓誤差總和更精準。
上述行為重複數次,求得誤差總和的平均數和變異數,當作數據的穩健程度,也當作演算法的有效程度。
robust / effective
「穩健」。正常情況多、異常情況少。另解:能夠容忍異常。
「有效」。答對次數多、答錯次數少。
穩健的數據:數據浮動範圍不大、甚至正確無誤。 穩健的演算法:計算過程或者計算結果,浮動範圍不大、甚至正確無誤。 有效的數據:數據涵蓋大多數案例、甚至全部案例。【目前沒有人這樣說】 有效的演算法:數據大多數擬合、甚至全部擬合。
有人將訓練誤差和測試誤差的差距,當作是穩健程度。
有人將測試誤差的多寡,當作是有效程度。
驗證方式
驗證方式 |訓練 |測試 ----------------+------+------ resubstitution |全部 |隨機重複挑選 bootstrapping |隨機重複挑選|全部 hold-out |其中一部分 |剩下的部分 cross-validation|其餘等份 |其中一等份
主流方法是k-fold cross-validation:分成k等份,進行k次cross-validation。