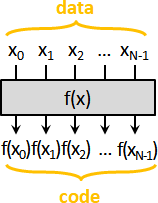
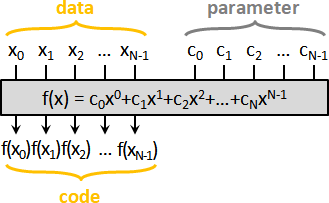
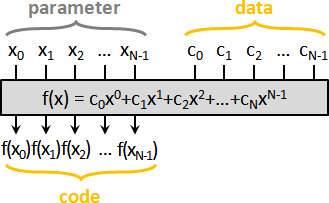
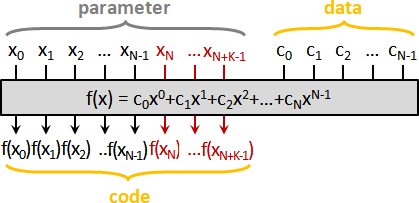
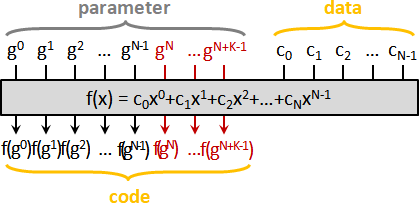
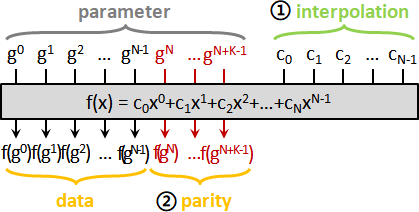
error detection
error detection
「錯誤偵測」。判斷資料是否損毀變異。
channel
天有不測風雲,人有旦夕禍福。
電腦世界當中,資料通常是經過傳輸而損毀。於是數學家想像有一個「通道」,宛如函數,一筆資料經過通道得到一筆資料,可能不變,可能出錯。
數學家引入機率的概念、引入遞增法化整為零的概念,令每一個位元有固定機率出錯。現實生活有著千奇百怪的出錯原因;數學家便設計了各式各樣的通道,儘量符合現實情況。
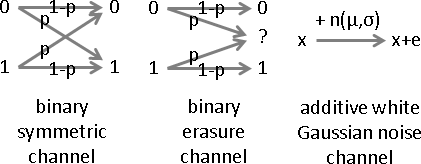
以下文章不談通道,讓事情單純一點!
encode / decode
不像壓縮和加密特別訂立新名詞,偵測和更正直接沿用舊名詞。
「編碼」是資料變碼。「解碼」是碼變資料。碼經過「通道」將有一定機率損毀變異。
「編碼」是補強資料。「解碼」是復原資料。
encode
0010001 -------> 001000100100010010001
↓ channel
0010001 <------- 001100110100010010000
decode
(detect/correct)