NP-complete
示意圖
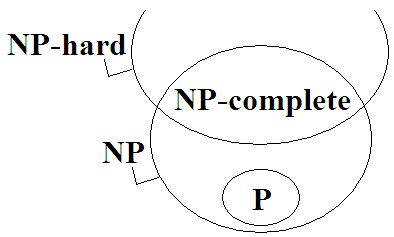
更豐富的示意圖
P問題
用多項式時間演算法能夠計算答案的問題。
「找出一群數字當中最大的數字」是P問題。
P的全名是polynomial time,定義源自於「自動機理論」,頗複雜,此處省略之。通常以「P」表示所有P問題構成的集合。
NP問題
用指數時間演算法能夠計算答案的問題,同時,用多項式時間演算法能夠驗證答案的問題。
由於P問題也可以改用指數時間演算法計算答案、當然可以用多項式時間驗證答案,故P問題都屬於NP問題。
「找出一張圖的一條Hamilton path」是NP問題。 計算答案: 窮舉所有可能的路線,一條一條驗證。 是指數時間演算法。 驗證答案: 給定一條可能的路線,就照著路線走,看看能不能走到每一點。 是多項式時間演算法。
「找出一張圖成本最小的那條Hamilton path」不是NP問題。 計算答案: 窮舉所有可能的路線,一條一條驗證。 是指數時間演算法。 驗證答案: 就算給定一條可能的路線, 還是必須窮舉所有路線,一條一條驗證,才知道哪條路線成本最少。 是指數時間演算法。
值得一提的是,每一個NP問題,都可以設計出多項式時間演算法,轉換成另一個NP問題。換句話說,所有NP問題都可以用多項式時間演算法彼此轉換。
NP的全名是non-deterministic polynomial time,定義源自於「自動機理論」,頗複雜,此處省略之。通常以「NP」表示所有NP問題構成的集合。
NP-complete問題
所有NP問題當中,最具代表性、層次最高、最難的問題。
NP-complete問題的各種特例,涵蓋了所有NP問題。只要有辦法解決NP-complete問題,就有辦法解決NP問題。
各個NP-complete問題都等價、都一樣難,可以用多項式時間演算法彼此轉換。現今已經找出上百個NP-complete問題了。
complete的意義為:能夠代表整個集合的子集合。舉例來說,它就像是一個線性空間(linear space)的基底(basis)。
「判斷一張圖是否存在Hamilton path」已被證明是NP-complete問題。
NP-hard問題
用多項式時間演算法轉換NP問題所得到的問題,同時,必須是跟NP-complete問題一樣難、還要難的問題。
NP-hard問題可能是:甲、NP-complete問題(是NP問題),乙、超出NP問題的複雜度,是更難的問題。
「找出一張圖成本最小的Hamilton path」是NP-hard問題。 由「找出一張圖的一條Hamilton path」這個NP問題, 用多項式時間把每條邊加上成本而得。 而且「找出一張圖成本最小的Hamilton path」至少比NP-complete問題還難。
介於P與NP-complete之間的問題
為什麼學校老師要教NP-complete?
台灣的演算法課程,都是直接抄舊書,特別強調NP-complete,特別強調問題之間的轉換。不過職場上幾乎不會用到這些知識。學術上要解決P = NP問題,也不會用到這些知識。
現在比較新的教學資料,都是直接介紹多項式時間和指數時間的差異,而不是去介紹P、NP、NP-complete、NP-hard到底誰包含誰。