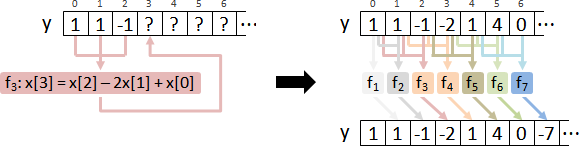引言
system representation / system realization
訊號學家自創一個同義詞彙realization。
硬要區分的話嘛:
representation是表示法本身。
realization是表示法轉換過程。
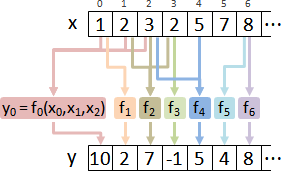
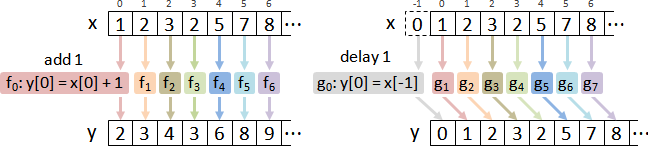
使用impulse response。
輸入是脈衝函數,輸出稱作脈衝響應。
LTI系統當中,脈衝響應恰是卷積核。
最後,卷積核進一步改寫成矩陣。
system realization原意是指找到系統模型、系統參數,以便建立系統。
由於訊號學家沒有考慮清楚,胡亂造詞、胡亂歸類。
system realization最終演變為完全不相干的意義:系統參數改寫成矩陣。
LTI system
state-space representation
線性函數(狹義版本)、線性遞迴函數,可以改寫成矩陣。
線性非時變系統的系統參數也可以改寫成矩陣,有兩種方式:
一、MIMO系統、線性非時變系統、一階。
改寫成矩陣,外觀仍是MIMO系統、一階。
將一個時刻的每種訊號併成向量。此向量是狀態。
經典應用是數值模擬的數值方案。
二、SISO系統、線性非時變系統、n階。
改寫成矩陣,外觀變成MIMO系統、一階。
將連續n個訊號數值併成向量。此向量是滑動視窗。
經典應用是遞迴數列的快速冪演算法。
此處使用二。
然而訊號學家卻將二稱作狀態空間表示法。成為歷史共業。
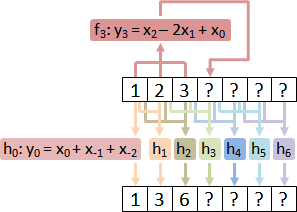
companion matrix realization
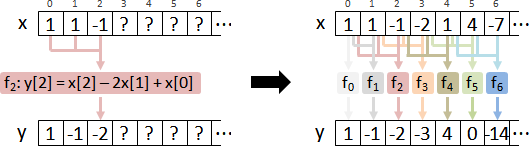
高階差分方程式,化作一階差分方程組。
高階微分方程式,化作一階微分方程組。
統計學與訊號學的差分方程式,
包括了輸入訊號和輸出訊號。
數學的差分方程式,
只有一個未知函數:對應到AR model。
恰有兩個未知函數:對應到ARMA model。
AR model:
x⃗[n+1] = A x⃗[n]
ARMA model:
x⃗[n+1] = A x⃗[n] + b
我思忖著通通改成b和y。【尚待確認】
AR(3) model:
x[n+3] + a₂ x[n+2] + a₁ x[n+1] + a₀ x[n] = 0
=> x[n+3] = - a₂ x[n+2] - a₁ x[n+1] - a₀ x[n]
=> x+⃡3 = - a₂(x+⃡2) - a₁(x+⃡1) - a₀x number -> sequence
⎧ (x )+⃡1 = x+⃡1 3rd-order equation
=> ⎨ (x+⃡1)+⃡1 = x+⃡2 -> 1st-order system
⎩ (x+⃡2)+⃡1 = - a₂(x+⃡2) - a₁(x+⃡1) - a₀x
⎧ x₀+⃡1 = x₁
=> ⎨ x₁+⃡1 = x₂ rename variables
⎩ x₂+⃡1 = -a₂x₂ - a₁x₁ - a₀x₀
⎡ x₀+⃡1 ⎤ ⎡ 0 1 0 ⎤ ⎡ x₀ ⎤ matrix representation
=> ⎢ x₁+⃡1 ⎥ = ⎢ 0 0 1 ⎥ ⎢ x₁ ⎥ (companion matrix)
⎣ x₂+⃡1 ⎦ ⎣ -a₀ -a₁ -a₂ ⎦ ⎣ x₂ ⎦
=> x⃗+⃡1 = A x⃗ rename variables
=> x⃗[n+1] = A x⃗[n] sequence -> number
AR(5) model:
⎡ x₀+⃡1 ⎤ ⎡ 0 1 0 0 0 ⎤ ⎡ x₀ ⎤
⎢ x₁+⃡1 ⎥ ⎢ 0 0 1 0 0 ⎥ ⎢ x₁ ⎥
⎢ x₂+⃡1 ⎥ = ⎢ 0 0 0 1 0 ⎥ ⎢ x₂ ⎥
⎢ x₃+⃡1 ⎥ ⎢ 0 0 0 0 1 ⎥ ⎢ x₃ ⎥
⎣ x₄+⃡1 ⎦ ⎣ -a₀ -a₁ -a₂ -a₃ -a₄ ⎦ ⎣ x₄ ⎦
3rd-order linear differential equation:
d³ d² d
——— x(t) + a₂ ——— x(t) + a₁ —— x(t) + a₀ x(t) = 0
dt³ dt² dt
=> x‴(t) + a₂ x″(x) + a₁ x′(x) + a₀ x(t) = 0
=> x‴(t) = - a₂ x″(t) - a₁ x′(t) - a₀ x(t)
⎧ (x )′ = x′ 3rd-order equation
=> ⎨ (x′)′ = x″ -> 1st-order system
⎩ (x″)′ = -a₂x″ - a₁x′ - a₀x
⎧ x₀′ = x₁
=> ⎨ x₁′ = x₂ rename variables
⎩ x₂′ = -a₂x₂ - a₁x₁ - a₀x₀
⎡ x₀′ ⎤ ⎡ 0 1 0 ⎤ ⎡ x₀ ⎤ matrix representation
=> ⎢ x₁′ ⎥ = ⎢ 0 0 1 ⎥ ⎢ x₁ ⎥ (companion matrix)
⎣ x₂′ ⎦ ⎣ -a₀ -a₁ -a₂ ⎦ ⎣ x₂ ⎦
=> x⃗′ = A x⃗ rename variables
similarity transformation
拿任意一種可逆矩陣T做相似變換。
decomposition A = TA'T⁻¹
=> similarity transformation A' = T⁻¹AT
對角化也是一種相似變換。變換矩陣是特徵向量。
minimal realization
數學稱作正則化canonicalization。
物理學稱作解耦合decoupling。
訊號學稱作最小實現minimal realization。
三者概念相同,只是著重的事情稍微有點差別。
總之一句話:矩陣對角化。
eigendecomposition A = EΛE⁻¹
=> diagonalization Λ = E⁻¹AE
變換矩陣A實施相似變換成為對角矩陣A' = Λ = E⁻¹AE。
對角線就是特徵值。將零集中在右下角。
最後去掉特徵值是零的多餘維度。
當A是同伴矩陣companion matrix。
特徵向量E恰是多項式內插矩陣Vandermonde matrix的轉置。
companion matrix:
⎡ 0 1 0 ⋯ 0 ⎤
⎢ 0 0 1 ⋯ 0 ⎥
A = ⎢ 0 0 0 ⋯ 0 ⎥
⎢ 0 0 0 ⋯ 1 ⎥
⎣ -a₀ -a₁ -a₂ ⋯ -aₙ₋₁ ⎦
eigenproblem:
Ax = λx
eigendecomposition:
A = EΛE⁻¹
eigenvalues:
λ₁, λ₂, ⋯, λₙ
eigenvectors:
⎡ λ₁⁰ λ₂⁰ ⋯ λₙ⁰ ⎤
⎢ λ₁¹ λ₂¹ ⋯ λₙ¹ ⎥ transpose of
E = ⎢ λ₁² λ₂² ⋯ λₙ² ⎥ Vandermonde matrix
⎢ : : : ⎥
⎣ λ₁ⁿ⁻¹ λ₂ⁿ⁻¹ ⋯ λₙⁿ⁻¹ ⎦
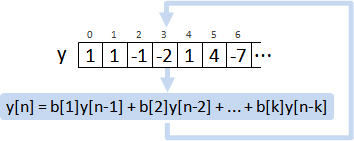
表格
AR model
╭────────────────────────────┬────────────────────────────╮
│ polynomial representation │ matrix representation │
╞════════════════════════════╧════════════════════════════╡
│ time domain │
│ impulse response representation │
╞════════════════════════════╤════════════════════════════╡
│ sequence │ companion matrix │
│ b = (b[0], b[1], b[2], ⋯) │ ⎡ 0 1 0 ⋯ ⎤│
│ │ ⎢ 0 0 1 ⋯ ⎥│
│ │ A = ⎢ 0 0 0 ⋯ ⎥│
│ │ ⎢ : : : ⎥│
│ │ ⎣ -b[0] -b[1] -b[2] ⋯ ⎦│
├────────────────────────────┤────────────────────────────┤
│ linear recurrence │ linear recurrence │
│ y[n] = b[1] y[n-1] │ y⃗[n] = A y⃗[n-1] │
│ + b[2] y[n-2] │ |
│ + ... │ │
├────────────────────────────┤────────────────────────────┤
│ expansion │ expansion │
│ y[n] = ....... │ y⃗[n] = Aⁿ y⃗[0] │
├────────────────────────────┤────────────────────────────┤
│ convolution │ Toeplitz matrix │
│ (y+⃡1) = b * y │ (y⃗+⃡1) = 𝐺 y⃗ │
│ │ │
│ │ ⎡ b[0] 0 0 ⋯ ⎤ │
│ │ ⎢ b[1] b[0] 0 ⋯ ⎥ │
│ │ 𝐺 = ⎢ b[2] b[1] b[0] ⋯ ⎥ │
│ │ ⎢ b[3] b[2] b[1] ⋯ ⎥ │
│ │ ⎣ : : : ⎦ │
├────────────────────────────┤────────────────────────────┤
│ solution │ solution │
│ f[n] = C₀ 𝑝₀ⁿ │ f[n] = C₀ Aⁿ │
│ + C₁ 𝑝₁ⁿ │ │
│ + ... │ │
╞════════════════════════════╧════════════════════════════╡
│ frequency domain │
│ transfer function representation │
╞════════════════════════════╤════════════════════════════╡
│ generating function │ matrix pencil │
│ F(z) = f[0] z │ zI-A │
│ + f[1] z⁻¹ │ │
│ + ... │ │
├────────────────────────────┤────────────────────────────┤
│ characteristic equation │ characteristic equation │
│ F(λ) = 0 │ det(λI-A) = 0 │
| | |
│ λⁿ = f[1] λⁿ⁻¹ │ │
│ + f[2] λⁿ⁻¹ │ │
│ + ... │ │
├────────────────────────────┤────────────────────────────┤
│ roots (poles) │ eigenvalues (poles) │
│ λ₁, λ₂, ... │ λ₁, λ₂, ... │
╰────────────────────────────┴────────────────────────────╯
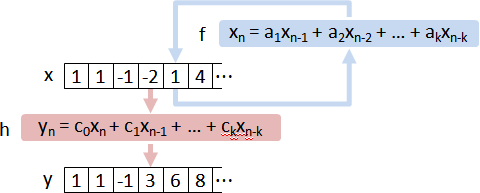
LTI state-space system
專著《Filtering and System Identification: A Least Squares Approach》。
state-space representation
⎰ x⃗[n+1] = A x⃗[n] + B u⃗[n]
⎱ y⃗[n] = C x⃗[n] + D u⃗[n]
LTI state-space system的四串系統參數也可以改寫成四個矩陣ABCD。【尚待確認】
但是教科書一律直接改寫成矩陣。完全見不到系統參數。
companion matrix realization
ARMA model可以進一步變成state-space model,湊出矩陣ABCD。
https://people.duke.edu/~hpgavin/SystemID/CourseNotes/LTI.pdf
similarity transformation
A' = T⁻¹AT
B' = T⁻¹B
C' = CT
D' = D
x' = T⁻¹x
u' = u
y' = y
eigensystem realization
eigensystem realization (Ho–Kálmán realization)
1. get (g[1], ⋯, g[n])
by impulse response
2. get 𝑂,𝐶
by compact SVD of Hankel((g[1], ⋯, g[n]))
3. get A,B,C,D
A: extract from Hankel((g[2], ⋯, g[k+1]))
B: first column of 𝐶
C: first row of 𝑂
D: orignal D (by similarity transformation)
https://math.stackexchange.com/questions/3275985/
https://par.nsf.gov/servlets/purl/10312038
reachability matrix / observability matrix
可到達性矩陣:x[n+1]遞迴函數,改寫成矩陣。
可觀察性矩陣:y[n]遞迴函數,改寫成矩陣。
藉由同伴矩陣,
訊號從數值x[n] y[n] z[n]推廣為向量u⃗[n] x⃗[n] y⃗[n]。
k是向量維度。k也是差分方程式的階數。
rank(A) = k,那麼A的直條的線性組合,得以形成每一種k維向量。
注意到,數列索引值n/數列長度n、向量維度k,兩者意義不同。
簡單起見,這個小節的u x y不添加向量符號、也不使用粗體字。
expansion of x (polynomial representation):
⎧ x[1] = A x[0] + B u[0]
⎨ x[2] = A² x[0] + AB u[0] + B u[1]
⎪ :
⎩ x[k] = Aᵏ x[0] + Aᵏ⁻¹B u[0] + ⋯ + AB u[k-2] + B u[k-1]
formula of x (matrix representation):
⎡ u[0] ⎤
x[k] = Aᵏ x[0] + [ Aᵏ⁻¹B ⋯ A²B AB B ] ⎢ : ⎥
⎣ u[k-1] ⎦
Ɔ
reachability matrix (controllability matrix):
𝐶 = [ A⁰B ⋯ Aᵏ⁻¹B ]
reachability:
any y can be generated by x[0] and u
<=> any x[k] can be generated by x[0] and u[0⋯k-1]
<=> rank(𝐶) = k
expansion of y (polynomial representation):
⎧ y[0] = C x[0] + D u[0]
⎨ y[1] = CA x[0] + CB u[0] + D u[1]
⎪ :
⎩ y[k-1] = CAᵏ⁻¹ x[0] + CAᵏ⁻²B u[0] + ... + CAB u[k-1] + D u[k-1]
expansion of y (matrix representation):
⎡ y[0] ⎤ ⎡ C ⎤ ⎡ D 0 ⋯ ⎤ ⎡ u[0] ⎤
⎢ : ⎥ = ⎢ CA ⎥ x[0] + ⎢ CB D ⋯ ⎥ ⎢ : ⎥
⎢ : ⎥ ⎢ : ⎥ ⎢ CAB CB ⋯ ⎥ ⎢ : ⎥
⎣ y[k-1] ⎦ ⎣ CAᵏ⁻¹ ⎦ ⎣ : : ⎦ ⎣ u[k-1] ⎦
𝑂 𝐺
observability matrix:
⎡ CA⁰ ⎤
𝑂 = ⎢ : ⎥
⎣ CAᵏ⁻¹ ⎦
observability:
unique x can be reconstructed by y and u
<=> unique x[0] can be reconstructed by y[0⋯k-1] and u[0⋯k-1]
<=> rank(𝑂) = k
Krylov subspace:湊足k種連續次方,得以構成k維空間。
一、可到達性矩陣、可觀察性矩陣至少需要列出0次方到k-1次方。
二、訊號長度至少是k個數字,得以檢查可到達性、可觀察性。
Markov parameters
卷積核(脈衝響應)改寫成矩陣。然後省略g[0]。
Markov parameters:
(CA⁰B, CA¹B, ...)
theorem:
Hankel((g[1], ⋯, g[k])) = Hankel((CA⁰B, ⋯, CAᵏ⁻¹B)) = 𝑂𝐶
⎡ g[1] g[2] ⋯ g[k] ⎤ ⎡ CA⁰B CA¹B ⋯ CAᵏ⁻¹B ⎤
⎢ g[2] g[3] ⋯ g[k+1] ⎥ ⎢ CA¹B CA²B ⋯ CAᵏB ⎥
⎢ : : : ⎥ = ⎢ : : : ⎥ = 𝑂𝐶
⎢ : : : ⎥ ⎢ : : : ⎥
⎣ g[k] g[k+1] ⋯ g[2k-1] ⎦ ⎣ CAᵏ⁻¹B CAᵏB ⋯ CA²ᵏ⁻²B ⎦
Toeplitz matrix = constant diagonal matrix
Hankel matrix = constant skew-diagonal matrix
可到達性矩陣故意被左右顛倒,就是為了產生常反對角矩陣。
如果我沒搞錯,這與卷積互相呼應。
卷積的其中一個數列也是需要左右顛倒。
Hankel singular values
Hankel((g[1], ⋯, g[n]))
做共軛分解conjugate decomposition,得到𝑂與𝐶。
從中間剖開一人分一半。
共軛分解採用compact SVD,順便降維,以便形成minimal realization。
去掉奇異值是零的多餘維度。
方便起見,新維度還是標記成k,新矩陣則追加下標k。
A = UΣVᵀ = U√Σ√ΣVᵀ compact singular value decomposition
Aₖ = Uₖ√Σₖ√ΣₖVₖᵀ minimal realization (rank k)
𝑂 = Uₖ√Σₖ
𝐶 = √ΣₖVₖᵀ
A = BᵀB。
對稱半正定矩陣A,分解成矩陣內積。
沒有正式學術名稱。
少數文獻稱作共軛分解conjugate decomposition。
概念宛如將一個平方值,分解成共軛複數相乘。
分解方式有無限多種。其中有兩種知名方式:
一、Cholesky decomposition,分解成上三角矩陣。
A = LLᵀ and B = Lᵀ
二、eigendecomposition。特徵分解。
A = EΛE⁻¹ = EΛEᵀ = E√Λ√ΛEᵀ and B = √ΛEᵀ
對稱半正定矩陣的情況下,特徵分解EVD等同奇異值分解SVD!
不是對稱半正定矩陣的情況下,只好改用SVD。
Hankel((g[1], ⋯, g[k]))是對稱矩陣,但是通常不是半正定矩陣。
system matrices
算A:移位一個時刻,湊出A。然後𝑂和𝐶移項即得。
⎡ g[2] g[3] ⋯ g[k+1] ⎤ ⎡ CA¹B CA²B ⋯ CAᵏB ⎤
⎢ g[3] g[4] ⋯ g[k+2] ⎥ ⎢ CA²B CA²B ⋯ CAᵏ⁺¹B ⎥
⎢ : : : ⎥ = ⎢ : : : ⎥ = 𝑂A𝐶
⎢ : : : ⎥ ⎢ : : : ⎥
⎣ g[k+1] g[k+2] ⋯ g[2k] ⎦ ⎣ CAᵏB CAᵏ⁺¹B ⋯ CA²ᵏ⁻¹B ⎦
let Hₖ = Hankel((g[1], ⋯, g[k]))
Aₖ = 𝑂ₖ⁺(Hₖ+⃡1)𝐶ₖ⁺
算B:𝐶ₖ第零個直條就是Bₖ。
算C:𝑂ₖ第零個橫條就是Cₖ。
算D:原本的D降維。【尚待確認】
balanced realization
balanced realization
四個矩陣ABCD的方程組,對角化比較複雜。
四個矩陣不能一起對角化。
只能以𝐶為主、或者以𝑂為主。
有人發現取平方(矩陣內積和外積)再開根號,𝐶和𝑂就可以一起對角化。
宛如SVD的背後原理。SVD即是EVD取平方(矩陣內積和外積)再開根號。
1. get P,Q by Lyapunov equation
AP + PAᵀ + BBᵀ = 0
AᵀQ + QA + CᵀC = 0
2. get 𝑂 by Cholesky decomposion
Q = 𝑂ᵀ𝑂
3. get U,Σ by eigendecomposition
𝑂P𝑂ᵀ = 𝑂𝐶𝐶ᵀ𝑂ᵀ= HHᵀ = UΣ²Uᵀ
4. get T by conjugate decomposition
T = 𝑂⁻¹U√Σ
T⁻¹ = √ΣUᵀ𝑂
其實步驟1和2是多餘的。
H = Hankel((g[1], ⋯, g[k]))
使用矩陣內積HᵀH、矩陣外積HHᵀ,即可完成平衡實現。
步驟1和2主要是為了介紹Lyapunov equation。
https://ocw.mit.edu/courses/6-241j-dynamic-systems-and-control-spring-2011/7f6754029d6945bd3bdc745080890bf8_MIT6_241JS11_chap26.pdf
image
線性代數當中,
image:一個矩陣,嘗試各種輸入向量,所能得到的各種輸出向量。輸出向量的集合。
theorem:
image(AAᵀ) = image(A)
直觀解讀:
一、Aᵀx是輸入向量x實施變換,獲得一部分的輸入向量。比原本少。
再經過A變換,獲得一部分的輸出向量。比原本少。
因此image(AAᵀ) ⊆ image(A)。
二、Aᵀ是垂直投影。Aᵀ消滅的維度,A消滅的維度,基本相等。
換句話說,rank(Aᵀ) = rank(A)。
即便額外套用Aᵀ,剩下的維度還是一樣多。
因此image(AAᵀ) = image(A)。
嚴謹證明,分成三個階段:
(1) AᵀAx = 0 <=> Ax = 0
(2) kernel(AᵀA) = kernel(A)
(3) image(AᵀA) = image(Aᵀ)
(1)(⟹) 等號兩邊同乘xᵀ
AᵀAx = 0
=> xᵀAᵀAx = 0
=> ‖Ax‖² = 0
=> Ax = 0
(1)(⟸) 等號兩邊同乘Aᵀ。
Ax = 0
=> AᵀAx = 0
(2) 因為兩個方程式等價,所以兩個解集合也等價。
(3) 線性代數基本定理:kernel(A) = image(Aᵀ)⟂
kernel(AᵀA) = kernel(A)
=> image((AᵀA)ᵀ)⟂ = image(Aᵀ)⟂
=> image(AᵀA)⟂ = image(Aᵀ)⟂
=> image(AᵀA) = image(Aᵀ)
https://math.stackexchange.com/questions/2411508
reachability
圖論當中,
reachable:從一個起點可以到達一個終點。
connected:從各種起點可以到達各種終點。
訊號學當中,
reachable set:從各種起點所能到達的各種終點。終點的集合。
使用矩陣來描述相鄰關係,
訊號學的reachable set=線性代數的image。
先備知識請見本站文件「adjacency matrix」。
圖論當中,A是圖。Aᵀ是反向圖(顛倒所有邊)。
套用Aᵀ:順走1步。
套用A:逆走1步。
套用AAᵀ:先順走1步、再逆走1步(矩陣乘法由右往左讀)。
考慮所有可能的起點,以及所有可以到達的終點。
套用A、套用AAᵀ,所有可以到達的終點一樣多。
套用R = (A⁰+A¹+⋯+Aᵏ):
逆走0步到k步,所到之處通通聯集。
套用RRᵀ = (A⁰+A¹+⋯+Aᵏ)(A⁰+A¹+⋯+Aᵏ)ᵀ:
先順走再逆走(矩陣乘法由右往左讀)。
展開式子,變成兩兩相乘,得到各種情況。例如順1逆2。
套用P = A⁰(A⁰)ᵀ+A¹(A¹)ᵀ+⋯+Aᵏ(Aᵏ)ᵀ:
順0逆0、順1逆1、……、順k逆k,所到之處通通聯集。
考慮所有可能的起點,以及所有可以到達的終點。
套用R、套用P,所有可以到達的終點一樣多。
reachability Gramian
Gram matrix MᵀM
k-step Aᵏ⁻¹B
outer product (Aᵏ⁻¹B)(Aᵏ⁻¹B)ᵀ = Aᵏ⁻¹BBᵀ(Aᵏ⁻¹)ᵀ
image image(Aᵏ⁻¹B) = image((Aᵏ⁻¹B)(Aᵏ⁻¹B)ᵀ)
k-reachability matrix 𝐶ₖ = [ A⁰B ⋯ Aᵏ⁻¹B ]
k-reachability Gramian matrix [ A⁰BBᵀ(A⁰)ᵀ ⋯ Aᵏ⁻¹BBᵀ(Aᵏ⁻¹)ᵀ ]
k-reachability R[k] = sum Aᵏ⁻¹B
k=0⋯∞
k-reachability Gramian P[k] = sum Aᵏ⁻¹BBᵀ(Aᵏ⁻¹)ᵀ = sum 𝐶ₖ 𝐶ₖᵀ
k=0⋯∞ k=0⋯∞
k-reachable set image(R[k]) = image(P[k])
https://control.asu.edu/Classes/MAE507/507Lecture06.pdf
https://control.asu.edu/Classes/MAE507/507Lecture17.pdf
Lyapunov equation
k-reachability Gramian P[k+1] = A P[k] Aᵀ + BBᵀ
Lyapunov stability image(P[k+1]) = image(P[k]) when k→∞
Lyapunov equation M = AMAᵀ + BBᵀ
where M = P[k] and k→∞
Lyapunov theorem Lyapunov stability <=> Lyapunov equation
Hankel singular value
reachability Gramian P = 𝐶𝐶ᵀ => AP + PAᵀ + BBᵀ = 0
observability Gramian Q = 𝑂ᵀ𝑂 => AᵀQ + QA + CᵀC = 0
Hankel singular value Σ = sqrt(eigenvalue(PQ))
balanced realization P' = Q' = Σ
similarity transformation
P' = T⁻¹P(Tᵀ)⁻¹
Q' = TᵀQT
延伸閱讀:dual system
rank / nullity
矩陣尺寸是n,而實際維度不足n。
套用此矩陣、實施變換,有些維度完全消失。
例如投影矩陣,有些維度完整保留,有些維度完全消失。
消失的維度,特徵值是零,特徵向量未定義。
(數學家規定必須湊滿n個特徵值。但是不必湊滿n個特徵向量。)
stability / instability
繼續深入。
實際維度是k,其中包含了縮小、不變、放大。
矩陣尺寸是n,其中包含了消失、縮小、不變、放大。
特徵值,其中包含了等於0,絕對值小於1、絕對值等於1、絕對值大於1。
不斷套用此矩陣、不斷實施變換,
有些維度完全消失、趨近消失、保持不變、變成正負無限大。
消失、縮小、不變,最終形成穩態。
放大,最終不會形成穩態。
reachability / controllability / stabilizability
可到達性:已知初始狀態x[0],
總是存在控制訊號u,可以得到每一種當前狀態x[n]。
(可以得到每一種狀態數列x。畢竟已知系統公式。)
可控制性:已知初始狀態x[0]、當前狀態x[n]。
總是存在控制訊號u,可以得到當前狀態x[n]。
(可以得到狀態數列x、輸出數列y。畢竟已知系統公式。)
可穩定性:已知初始狀態x[0],
總是存在控制訊號u,使得每種輸出訊號y到達穩態。
(即便不滿足可控制性。例如ABCD矩陣全是零。)
一般來說,可到達性=>可控制性。
有反矩陣,可到達性<=>可控制性。
現實當中,有可能不可到達、但是可控制。
舉例來說,一部分特徵值是零,
輸入訊號剛好落在這些特徵向量構成的子空間,糊里糊塗得到零。
你也只能得到零,無法得到其他東西。
observability / constructability / detectability
可觀察性:已知輸出訊號y、控制訊號u,
可以得到唯一一種初始狀態x[0]。
(可以得到唯一一種狀態數列x。畢竟已知系統公式。)
可建設性:已知輸出訊號y、控制訊號u、當前狀態x[n]。
可以成立。
可偵測性:已知輸出訊號y、控制訊號u,
可以讓輸出訊號y到達穩態。
(即便不滿足可觀察性。例如不知道狀態但知道會穩定。)
一般來說,可觀察性=>可建設性。
有反矩陣,可觀察性<=>可建設性。
現實當中,有可能不可觀察、但是可建設。
homogeneous solution多解的部分剛好可逆。
output controllablility
output controllable if and only if the output controllability
Gramian is positive definite.
https://arxiv.org/pdf/2306.08523
dual system
四個矩陣ABCD通通轉置,仍然是LTI state-space system。
四個矩陣ABCD通通轉置,reachability與observability恰好對調。
原理是線性代數基本定理:kernel(A) = image(Aᵀ)⟂
就這樣。
controllable canonical form / observable canonical form
以矩陣A為主角,
實施companion matrix realization,
得到controllable canonical form。
四個矩陣ABCD通通轉置,得到另外一種canonical form。
即是dual system。
http://www.dii.unimo.it/~zanasi/didattica/Teoria_dei_Sistemi/Luc_TDS_ING_2016_Reachability_and_Controllability.pdf
http://www.dii.unimo.it/~zanasi/didattica/Teoria_dei_Sistemi/Luc_TDS_ING_2016_Observability_and_Constructability.pdf
表格
專著《Linear Optimal Control: H₂ and H∞ Methods》。
LTI state-space system
╭────────────────────────────┬────────────────────────────╮
│ polynomial representation │ matrix representation │
╞════════════════════════════╧════════════════════════════╡
│ time domain │
│ impulse response representation │
╞════════════════════════════╤════════════════════════════╡
│ sequence │ companion matrix │
│ a,b,c,d │ A,B,C,D │
│ a = (a[0], a[1], ...) │ │
│ b = (b[0], b[1], ...) │ │
│ c = (c[0], c[1], ...) │ │
│ d = (d[0], d[1], ...) │ │
├────────────────────────────┤────────────────────────────┤
│ linear recurrence │ linear recurrence │
│ ⎧ x[n+1] = a[0] x[n] + ⋯ │ ⎰ x⃗[n+1] = A x⃗[n] + B u⃗[n] │
│ ⎨ + b[0] u[n] + ⋯ │ ⎱ y⃗[n] = C x⃗[n] + D u⃗[n] │
│ ⎪ y[n] = c[0] x[n] + ⋯ │ │
│ ⎩ + d[0] u[n] + ⋯ │ │
├────────────────────────────┤────────────────────────────┤
│ expansion │ expansion │
│ x[n+1] = ...... | x[n+1] = Aⁿ⁺¹ x[0] + Ɔ u⃗[n]|
│ y[n] = ...... │ y⃗[n] = 𝑂 x[0] + 𝐺 u⃗[n] │
├────────────────────────────┤────────────────────────────┤
│ convolution │ Hankel matrix │
│ ⎰ x+⃡1 = a ∗ x + b ∗ u │ 𝑂𝐶 │
│ ⎱ y = c ∗ x + d ∗ u │ │
├────────────────────────────┤────────────────────────────┤
│ impulse response │ Markov parameters │
│ g[n] = ...... │ g[n] = CAⁿ⁻¹B + D δ[n] │
│ │ = ⎰ D , if n = 0 │
│ │ ⎱ CAⁿ⁻¹B , if n > 0 │
├────────────────────────────┤────────────────────────────┤
│ solution │ solution │
│ y[n] = ...... │ y[n] = C Aⁿ x[0] │
│ │ + sum CAⁿ⁻¹⁻ⁱB u[i] │
│ │ i=0⋯n-1 │
│ │ + D u[0] │
╞════════════════════════════╧════════════════════════════╡
│ frequency domain │
│ transfer function representation │
╞════════════════════════════╤════════════════════════════╡
│ generating function │ resolvent │
│ A(z) = a[0]z + a[1]z⁻¹ + ⋯ │ G(z) = C(zI-A)⁻¹B + D │
│ B(z) = b[0]z + b[1]z⁻¹ + ⋯ │ adj(zI-A) │
│ C(z) = c[0]z + c[1]z⁻¹ + ⋯ │ = C ————————— B + D │
│ D(z) = d[0]z + d[1]z⁻¹ + ⋯ │ det(zI-A) │
├────────────────────────────┤────────────────────────────┤
│ BIBO stability │ BIBO stability │
│ A(λ) = 0 │ det(λI-A) = 0 │
├────────────────────────────┤────────────────────────────┤
│ roots (poles) │ eigenvalues (poles) │
│ λ₁, λ₂, ... │ λ₁, λ₂, ... │
╰────────────────────────────┴────────────────────────────╯