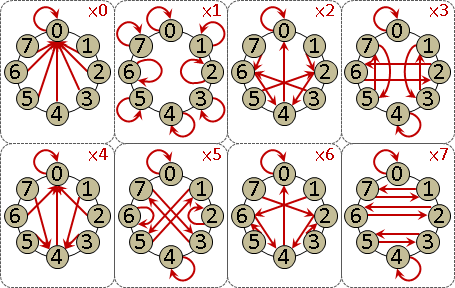
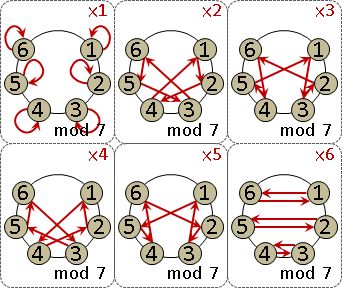
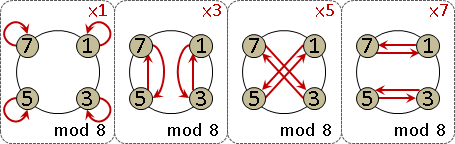
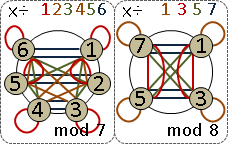
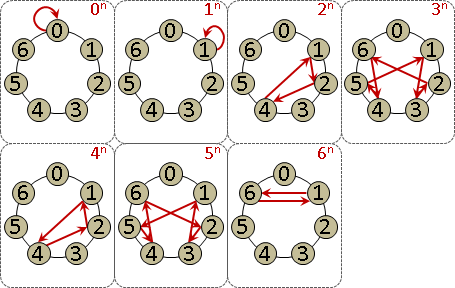
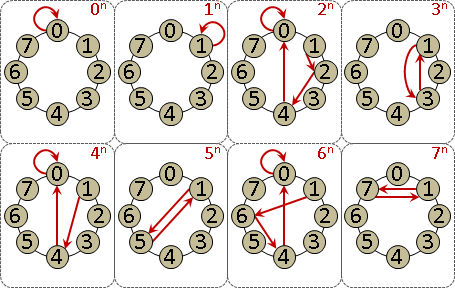
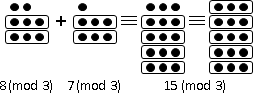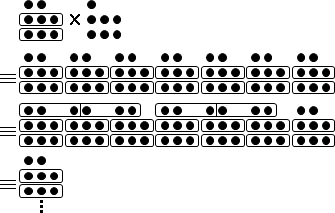monic linear congruences x ≡ rᵢ (mod mᵢ) , mᵢ are coprime
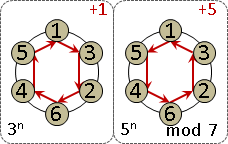
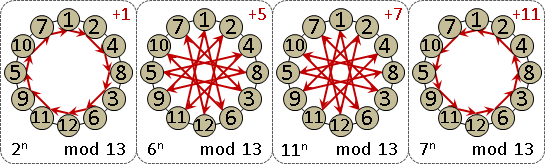
南北朝數學著作《孫子算經》有一道題目:今有物不知其數,三三數之賸二,五五數之賸三,七七數之賸二,問物幾何?
用現代數學術語來說,這個問題就是餘數系統的一元一次方程組,而且係數皆是一,而且模數兩兩互質。
⎧ x ≡ 2 (mod 3)
⎨ x ≡ 3 (mod 5)
⎩ x ≡ 2 (mod 7)
正確答案是105數之賸23。
x ≡ 23 (mod 105)
演算法是「Garner's algorithm」、「Qin's algorithm」。
演算法(窮舉法)
窮舉法:列出「三三數之賸二」的數字,然後是「五五數之賸三」與「七七數之賸二」。三個列表都出現的數字,就是正確答案。
⎧ x ≡ 2 (mod 3) ⇔ x = ..., 8, 5, 2, -1, -4, ...
⎨ x ≡ 3 (mod 5) ⇔ x = ..., 13, 8, 3, -2, -7, ...
⎩ x ≡ 2 (mod 7) ⇔ x = ..., 16, 9, 2, -5, -12, ...
試誤法:一一列出各種答案,試著除以三、五、七。
不幸的是,答案有無限多個,試誤法無法找到所有答案。然而試誤法讓我們發現答案具有規律。
演算法(Garner's algorithm)
遞推法:逐式代入求解。
⎧ x ≡ 2 (mod 3)
⎨ x ≡ 3 (mod 5)
⎩ x ≡ 2 (mod 7)
最初 x ≡ 2 (mod 3)
⇒ x = 3t + 2
代入 x ≡ 3 (mod 5)
⇒ 3t + 2 ≡ 3 (mod 5) ⇒ 3t ≡ 1 (mod 5) ⇒ t ≡ 2 (mod 5)
⇒ t = 5s + 2
代回 x = 3t + 2
⇒ x = 3(5s + 2) + 8 = 15s + 8
代入 x ≡ 2 (mod 7)
⇒ 15s + 8 ≡ 2 (mod 7) ⇒ 15s ≡ 1 (mod 7) ⇒ s ≡ 1 (mod 7)
⇒ s = 7u + 1
代回 x = 15s + 8
⇒ x = 15(7u + 1) + 8 = 105u + 23
換句話說:每次只算兩道式子,重複N-1次。
一、一元一次方程組,係數皆是一,模數 m₁ m₂ 互質。
⎰ x ≡ r₁ (mod m₁)
⎱ x ≡ r₂ (mod m₂)
二、令一式成立。處理 x 模 m₁。
x ≡ r₁ + k m₁ (mod m₁)
三、令二式也成立。處理 x 模 m₂。
x ≡ r₁ + k m₁ ≡ r₂ (mod m₂)
k m₁ ≡ r₂ - r₁ (mod m₂)
k ≡ (r₂ - r₁) m₁ (mod m₂)
四、得到答案。《linear interpolation》
⎰ x ≡ r₁ + k m₁ (mod m₁) where k ≡ (r₂ - r₁) m₁ (mod m₂)
⎱ x ≡ r₁ + k m₁ (mod m₂)
五、模數統一設定成最小公倍數,恰是 m₁m₂。
x ≡ r₁ + k m₁ (mod m₁m₂) where k ≡ (r₂ - r₁) m₁ (mod m₂)
演算法(Qin's algorithm)(Gauss's algorithm)
公式解:宋朝數學著作《數書九章》發明的「大衍總數術」。
一、一元一次方程組,係數皆是一,模數 m₁ 到 mɴ 兩兩互質。
⎧ x ≡ r₁ (mod m₁)
⎨ ⋮
⎩ x ≡ rɴ (mod mɴ)
二、令 M = m₁ × m₂ × ... × mɴ
M₁ = M ÷ m₁
⋮
Mɴ = M ÷ mɴ
Mᵢ 原本包含所有模數,但是刻意消去了 mᵢ。
造成 Mᵢ 只對其中一個模數 mᵢ 有反應(無法整除)(互質):
Mᵢ % mⱼ ≠ 0 when i = j
Mᵢ % mⱼ = 0 when i ≠ j
三、令 M₁ = M₁的倒數,模數為 m₁
⋮
Mɴ = Mɴ的倒數,模數為 mɴ
讓 (Mᵢ × Mᵢ) 只對其中一個模數 mᵢ 有反應,得到結果是 1:
(Mᵢ × Mᵢ) % mⱼ = 1 when i = j
(Mᵢ × Mᵢ) % mⱼ = 0 when i ≠ j
再讓 (rᵢ × Mᵢ × Mᵢ) 只對其中一個模數 mᵢ 有反應,得到結果是 rᵢ。
(rᵢ × Mᵢ × Mᵢ) % mⱼ = rᵢ when i = j
(rᵢ × Mᵢ × Mᵢ) % mⱼ = 0 when i ≠ j
四、N道式子通通加起來,以滿足方程組。《Lagrange interpolation》
x ≡ (r₁ × M₁ × M₁) (mod m₁) + ... + (rɴ × Mɴ × Mɴ) (mod mɴ)
五、模數統一設定成最小公倍數,恰是 M。
x ≡ (r₁ × M₁ × M₁) + ... + (rɴ × Mɴ × Mɴ) (mod M)
monic linear congruences x ≡ rᵢ (mod mᵢ)
一道方程式拆解成多道方程式,原模數等於新模數的最小公倍數,答案不變。
⎧ x ≡ 4 (mod 9)
x ≡ 4 (mod 360) —→ ⎨ x ≡ 4 (mod 10)
⎩ x ≡ 4 (mod 24)
where 360 = lcm(9, 10, 24)
一道方程式,實施分割,讓模數互質:
原模數做質因數分解,新模數是質因數次方。
⎧ x ≡ 4 (mod 2³)
x ≡ 4 (mod 360) —→ ⎨ x ≡ 4 (mod 3²)
⎩ x ≡ 4 (mod 5¹)
where 360 = 2³ × 3² × 5¹ = lcm(2³, 3², 5¹)
多道方程式,實施合併,讓模數互質:
一、模數相同,餘數不同,顯然無解。
二、模數都是同一個質數p的各種次方,餘數可以重新視作p進位。位數一致:合併對應位數。位數不一致:無解。
原模數是質數p的各種次方,新模數是質數p的最高次方。
⎧ x ≡ 2 (mod 2²)✔ 10₍₂₎
⎧ x ≡ 2 (mod 4) ⎪ x ≡ 6 (mod 3¹)
⎨ x ≡ 6 (mod 48) —→ ⎨ x ≡ 6 (mod 2⁴)✔110₍₂₎
⎩ x ≡ 4 (mod 360) ⎪ x ≡ 4 (mod 2³)✔100₍₂₎
⎪ x ≡ 4 (mod 3²) ↑
⎩ x ≡ 4 (mod 5¹) no solution
⎧ x ≡ 1 (mod 2²)✔ 1₍₂₎
⎧ x ≡ 1 (mod 4) ⎪ x ≡ 7 (mod 3¹) ⎧ x ≡ 7 (mod 2⁴)
⎨ x ≡ 7 (mod 48) —→ ⎨ x ≡ 7 (mod 2⁴)✔111₍₂₎ —→ ⎨ x ≡ 1 (mod 3²)
⎩ x ≡ 1 (mod 360) ⎪ x ≡ 1 (mod 2³)✔ 1₍₂₎ ⎩ x ≡ 1 (mod 5¹)
⎪ x ≡ 1 (mod 3²)
⎩ x ≡ 1 (mod 5¹)
方程組變成了上個小節的格式。
luogu P4777
linear congruences aᵢx ≡ bᵢ (mod mᵢ)
一道方程式,係數和模數剛好互質,運用倒數、消去係數。
一道方程式,係數和模數沒有互質,不斷約分、直到互質。
⎧ 1x ≡ 2 (mod 3) ⎧ x ≡ 1×2 (mod 3) ⎧ x ≡ 2 (mod 3)
⎨ 3x ≡ 3 (mod 5) —→ ⎨ x ≡ 3×3 (mod 5) —→ ⎨ x ≡ 6 (mod 5)
⎩ 5x ≡ 2 (mod 7) ⎩ x ≡ 5×2 (mod 7) ⎩ x ≡ 6 (mod 7)
方程組變成了上個小節的格式。
Chinese remainder theorem
模數之於中國餘數定理,猶如質數之於算術基本定理。
凡是餘數r,都可以藉由一元一次方程組、係數為一、模數互質,成為一個獨一無二的餘數組(r₁, r₂, ...)。
但是前提是特定的模數m、模數組(m₁, m₂, ...):
條件一、模數組乘積必須等於模數m = m₁m₂...。
條件二、模數組必須兩兩互質mᵢ⊥mⱼ。
一種方式是m做質因數分解,mᵢ是每一項質因數次方。
一元一次方程組、係數為一、模數互質
⎧ r ≡ r₁ (mod m₁)
⎨ r ≡ r₂ (mod m₂) where mᵢ⊥mⱼ
⎩ : : : :
中國餘數定理:一維餘數與多維餘數的一對一轉換
r (mod m₁m₂...) ←—→ (r₁ (mod m₁), r₂ (mod m₂), ...)
這樣比較好讀
(m₁, m₂, ...)
r ←—————————————→ (r₁, r₂, ...)
一元一次方程組、係數為一、模數互質
⎧ 10 ≡ 1 (mod 3)
⎨ 10 ≡ 0 (mod 5)
⎩ 10 ≡ 3 (mod 7)
中國餘數定理:一維餘數與多維餘數的一對一轉換
10 (mod 3×5×7) ←—→ (1 (mod 3), 0 (mod 5), 3 (mod 7))
這樣比較好讀
(3,5,7)
10 ←———————→ (1,0,3)
已知一組模數,分別計算餘數。O(N)
r —————————————————————————————————→ (r₁, r₂, ...)
←—————————————————————————————————
解方程組。O(Nlog(m))
根據中國餘數定理,一維餘數的運算,等同多維餘數的運算。
分解前 模數 105 | 分解後 模數 (3, 5, 7)
5 | (2, 0, 5)
9 | (0, 4, 2)
-----------------+------------------------------------------
5 + 9 ≡ 14 | (2+0, 0+4, 5+2) ≡ (2, 4, 7)
5 - 9 ≡ -4 ≡ 101 | (2-0, 0-4, 5-2) ≡ (2, -4, 3) ≡ (2, 1, 3)
5 × 9 ≡ 45 | (2×0, 0×4, 5×2) ≡ (0, 0, 10)
5 ÷ 9 ≡ undefine | (2÷0, 0÷4, 5÷2) ≡ undefine
5 ÷ 8 ≡ 40 | (2÷2, 0÷3, 5÷1) ≡ (1, 0, 5)
5 ^ 2 ≡ 25 | (2^2, 0^2, 5^2) ≡ (4, 0, 25) ≡ (1, 0, 4)
UVa 756 700 11754
整數系統與餘數系統互相轉換
介紹一個重要的計算技巧:一段整數的計算流程,改為套上各種模數並且分別計算答案,最後運用中國餘數定理還原正確答案──先換到餘數系統,再還原為整數系統。
(999 + 25) × 333 ÷ 256 = ?
採用互質的模數3、5、11,聯立
⎧ (999 + 25) × 333 ÷ 256 ≡ (0 + 1) × 0 ÷ 1 ≡ 0 (mod 3)
⎨ (999 + 25) × 333 ÷ 256 ≡ (-1 + 0) × 3 ÷ 1 ≡ 2 (mod 5)
⎩ (999 + 25) × 333 ÷ 256 ≡ (9 + 3) × 3 × 4 ≡ 1 × 1 ≡ 1 (mod 11)
再運用中國餘數定理
=> (999 + 25) × 333 ÷ 256 ≡ 12 (mod 165)
999+25是4位數,333是3位數,256是3位數,推測正確答案是4位數:
12 + 165 × 6 = 1002
1002 + 165 = 1167
1167 + 165 = 1332
......
一、當數字很大、式子很長時,此技巧就能發揮功效!
二、模數們最好兩兩互質,方便套用中國餘數定理。
三、此技巧得到的答案一定是整數;也就是說,當正確答案是整數,才能使用此技巧。比如說,式子之中有除法,導致正確答案是分數,此時就不能使用此技巧。
四、式子之中若有除法,則令模數是質數,餘數除法保證有唯一解。承第二點,也就是說,模數們最好都是質數。
五、選定的模數們,其乘積足夠大,大於正確答案時,那麼最後求得的餘數,即是正確答案,不必再推測。
例如求「Hilbert matrix」的反矩陣。Hilbert matrix由單位分數組成,其反矩陣恰好都是整數。先將問題轉換成餘數系統,選擇多個模數並且各別以高斯消去法求得反矩陣,最後再用中國餘數定理轉換回整數系統。