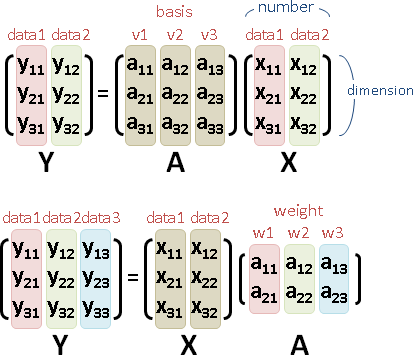
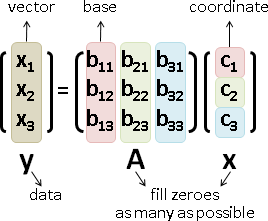
kernel method
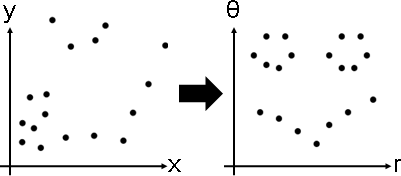
數據實施變換,讓數據變漂亮,方便分群、分類、擬合、對齊、嵌入、……。
但是如何挑選函數呢?一一試驗、碰碰運氣,別無他法。
x̕ = φ(x)
transformation: φ(x)
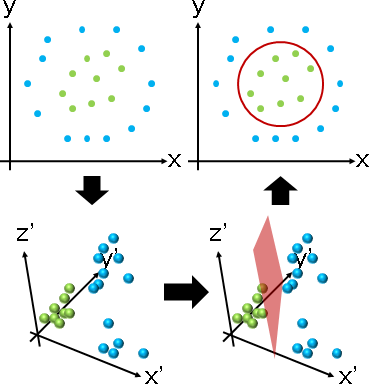
classifier center = (24,22) radius = 10, #(data) = 13 + 7 = 21
p = {{17,8},{21,8},{27,8},{33,10},{37,15},{39,22},{36,30},{30,35},{21,35},{12,32},{12,28},{7,22},{10,14},{18,15},{24,16},{28,18},{16,19},{18,24},{24,23},{31,25},{27,29}};
f[x_] := (x-24)*(x-24);
g[y_] := (y-22)*(y-22);
h[x_,y_] := Sqrt[2]*(x-24)*(y-22);
q = Transpose[{
f[ p[[All,1]] ],
g[ p[[All,2]] ],
Apply[h, p, {1}]
}];
ListPointPlot3D[{q[[1;;13]], q[[14;;21]]}, BoxRatios -> {1,1,1}, PlotStyle -> PointSize[Large]]
c = Classify[q -> {"A","A","A","A","A","A","A","A","A","A","A","A","A","B","B","B","B","B","B","B","B"}, "Decision", Method->"SupportVectorMachine"];
一筆數據的誤差,習慣採用距離平方。計算誤差時,數據套用變換函數、距離平方函數,兩個步驟,有點煩。
投機取巧的方式:變換函數、距離平方函數,合併成「數據變換之後的距離平方函數」,簡稱「核函數kernel」。
kernel: k(x,y) = ‖φ(x) - φ(y)‖²
距離平方,恰好由點積組成。於是也有人採用「數據變換之後的點積函數」,簡稱「核函數kernel」。
‖φ(x) - φ(y)‖² = (φ(x) ∙ φ(x)) + (φ(y) ∙ φ(y)) - 2 (φ(x) ∙ φ(y))
kernel: k(x,y) = φ(x) ∙ φ(y)
經典的核函數是radial basis function kernel、heat kernel。
優點:精簡計算步驟,降低時間複雜度。尤其是低維度變高維度的情況下,核函數可以繞過高維度,直接得到距離平方或者點積。
缺點:從核函數無法得知變換函數。不過不知道也沒關係,分群、分類、擬合、對齊、嵌入、……的結果看起來漂亮就好了。
RBF kernel: k(x,y) = exp(-‖x-y‖² / σ²) σ is variance
heat kernel: k(x,y) = exp(-‖x-y‖² / 4t) / (4πt)ⁿ⸍² t is time
先前所有主題,通通可以來個kernel。諸如kernel k-means、kernel SVM、kernel PCA、kernel NMF。學術界有陣子非常流行這種灌水文章,最後弄假成真,kernel變成了教科書的標準配備。
方程組的根、積分變換的座標軸、數據變換之後的距離平方函數,通通叫做kernel。它們之間毫無關聯。
kernel principal component analysis
PCA:
maximize vᵀXXᵀv subject to vᵀv = 1
maximize vᵀXXᵀv - λ(vᵀv - 1) Lagrange multiplier
solve XXᵀv = λv derivative = 0
數據預先實施變換的PCA:
maximize vᵀΦ(X)Φ(X)ᵀv st vᵀv = 1 transformation: Φ(X)
maximize vᵀΦ(X)Φ(X)ᵀv - λ(vᵀv - 1) Lagrange multiplier
solve Φ(X)Φ(X)ᵀv = λv derivative = 0
solve Φ(X)Φ(X)ᵀΦ(X)w = λΦ(X)w kernel trick: v = Φ(X)w
solve Φ(X)ᵀΦ(X)w = λw drop Φ(X)
solve K(X)w = λw kernel: K(X) = Φ(X)ᵀΦ(X)
數據實施變換之後,數據減去平均數的PCA:
maximize vᵀΦ̄(X)Φ̄(X)ᵀv st vᵀv = 1 centering: Φ̄(X) = Φ(X)C
maximize vᵀΦ̄(X)Φ̄(X)ᵀv - λ(vᵀv - 1) Lagrange multiplier
solve Φ̄(X)Φ̄(X)ᵀv = λv derivative = 0
solve Φ̄(X)Φ̄(X)ᵀΦ̄(X)w = λΦ̄(X)w kernel trick: v = Φ̄(X)w
solve Φ̄(X)ᵀΦ̄(X)w = λw drop Φ̄(X)
solve K̄(X)w = λw kernel: K̄(X) = Φ̄(X)ᵀΦ̄(X)
K̄(X)等於K(X)的橫條直條中心化。
{ Φ̄(X) = Φ(X)C
{ K(X) = Φ(X)ᵀΦ(X)
K̄(X) = Φ̄(X)ᵀΦ̄(X) = CᵀΦ(X)ᵀΦ(X)C = CᵀK(X)C
設計核函數K,精簡計算步驟。
變換函數、核函數不是線性函數,不能寫成矩陣乘法ΦX與KX,只能寫成函數求值Φ(X)與K(X)。Φ(X)與K(X)都是矩陣。
求得K̄(X)最大的特徵值暨特徵向量。w不必還原成v,意思到了就好,精簡計算步驟。