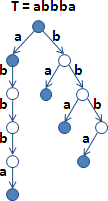
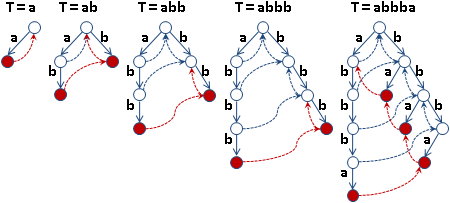
longest common prefix
一堆字串的「最長共同前綴」只有一個,有可能是空字串。
演算法很簡單:字串們一齊從頭開始比對字元。
s1: aabbccc
s2: aabbbccc
s3: aabaccc
s1 s2 s3 的 LCP 就是 aab。
兩個後綴的LCP
string:
abbbababba
suffixes:
s0: abbbababba
s1: bbbababba
s2: bbababba
......
s8: ba
s9: a
LCP(s1, s2) = bb
LCP(s0, s9) = a
兩個後綴的LCP,
就是排序全部後綴之後,兩個後綴之間的所有後綴的LCP。
0 1 2 3 4 5 6 7 8 9
+---------------------+
sa | 9 4 6 0 8 3 5 7 2 1 |
+---------------------+
a a a a b b b b b b
b b b a a a b b b
a b b b b a a b
b a b a b b a
b a b a a b
a b b b a
a a b b
b a b
b a
a
LCP(7th, 9th) = LCP(7th, 8th, 9th) = LCP(s7, s2, s1) = bb
LCP(4th, 8th) = LCP(4th, ..., 8th) = LCP(s8, s3, s5, s7, s2) = b
開頭相近的後綴,排在一起;開頭不相近的後綴,被開頭相近的後綴隔開。
排序全部後綴之後,兩個後綴之間的所有後綴的LCP,
就是兩兩相鄰後綴的LCP們的LCP。
LCP(7th, 9th) = LCP( LCP(7th, 8th), LCP(8th, 9th) ) = bb
LCP(4th, 8th) = LCP( LCP(4th, 5th), ..., LCP(7th, 8th) ) = b
以相鄰後綴的LCP,推導出任意後綴的LCP。
兩兩相鄰後綴的LCP,表達成數值:
longest common prefix array
直接記錄LCP字串,浪費大量記憶體空間,因而改為記錄LCP長度。輔以原字串、後綴陣列,便可得到LCP字串。
排序全部後綴之後,每一個後綴與前一個後綴的LCP長度,儲存於陣列,得到LCP array。
0 1 2 3 4 5 6 7 8 9
+---------------------+
sa | 9 4 6 0 8 3 5 7 2 1 |
+---------------------+
lcpa | 0 1 2 3 0 2 3 1 3 2 |
+---------------------+
a a a a b b b b b b
b b b a a a b b b
a b b b b a a b
b a b a b b a
b a b a a b
a b b b a
a a b b
b a b
b a
a
LCP_length(7th, 9th) = min(lcpa[7+1], ..., lcpa[9]) = 2
LCP_length(4th, 8th) = min(lcpa[4+1], ..., lcpa[8]) = 1
兩個後綴的LCP,藉由LCP array,變成了查詢區間最小值。請參考「偽線段樹」。
UVa 12338
演算法
依序計算兩兩相鄰後綴的LCP,依序填寫LCP array。時間複雜度O(T²)。
演算法
運用小技巧,建立LCP array僅需時O(T)。
一個字串的後綴,開頭去掉一個字元,仍是後綴。
兩個相鄰後綴,開頭各去掉一個字元,得到兩個新後綴。雖然不見得相鄰,但是大小關係依然相同。LCP則少了一個開頭字元。
2 3 7 9
---------------------
a a b b
b b b b
b b a b
a b a
a b
b a
a b
b b
b a
a
abba < abbbababba => bba < bbbababba
LCP(abba, abbbababba) = a + LCP(bba, bbbababba)
LCP_length(abba, abbbababba) = 1 + LCP_length(bba, bbbababba)
兩個新後綴的LCP長度,小於等於第二個新後綴、與其前方相鄰後綴的LCP長度。
LCP_length(2th, 3th) - 1 = LCP_length(7th, 9th) ≤ LCP_length(7th, 8th)
LCP_length(3-1th, 3th) - 1 ≤ LCP_length(8-1th, 8th)
從最長的後綴(原字串)開始,逐次去掉開頭字元,跳著填寫LCP array。
3th: abbbababba 9th: bbbababba 8th: bbababba
LCP(3-1th, 3th) --> LCP(9-1th, 9th) --> LCP(8-1th, 8th) --> ...
每次LCP減少一個開頭字元之後,新後綴與其相鄰後綴的LCP只會一樣長、更長。不必每次從頭開始比對字元。
一、依序掃描原字串的每個後綴。每次都會少掉一個開頭字元:
甲、求得該後綴在後綴陣列裡的位置。
乙、再找出上一個相鄰後綴。
丙、逐一比對字元,求出LCP長度,儲存於LCP array。
丁、下次就可以從LCP長度減一開始比對字元。小心不能減至負值。
字串搜尋
一、T的suffix array。O(T+A)。
二、T的LCP array。O(T)。
三、LCP array的偽線段樹。建立O(T)、搜尋O(logT)。
用來快速求得LCP(i,j)。
四、二元搜尋。
令二元搜尋的三個指標是L M R。二元搜尋的過程是:逐字比對P與M,判斷P < M或者P > M,讓M' = L或者M' = R。時間複雜度O(PlogT)。
M與L R經常有共同前綴。P與M比大小,可以從LCP(L,R)開始比對,節省一點時間。然而時間複雜度仍是O(PlogT)。
P與L R經常有共同前綴。P與M比大小之前,可以預先計算LCP(M,L)、LCP(M,R),如果小於LCP(P,L)、LCP(P,R),就毋需比對。看誰長得像,直接得到M'。時間複雜度降為O(P+logT)。
預先建立LCP array與「偽線段樹」,從LCP array查詢區間最小值,得以迅速求得LCP。
一、P與M的共同前綴,往後不必再比對,O(P)。二、查詢區間最小值,區間逐次減半,O(logT + logT/2 + logT/4 + ... ) = O(logT)。三、總時間複雜度O(P+logT)。
【待補程式碼】
ICPC 4657