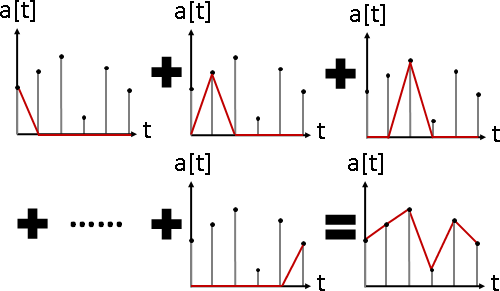
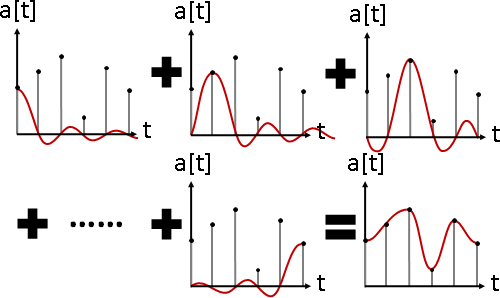
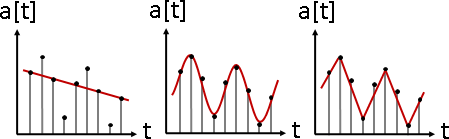
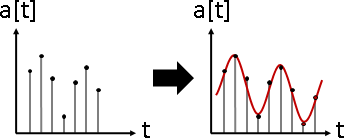
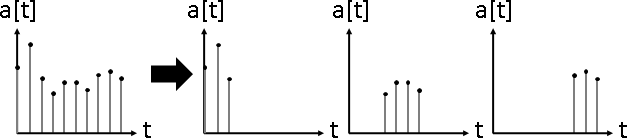
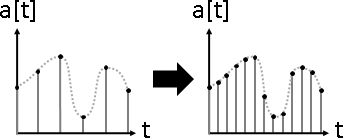signal overlapping(signal composition)
訊號疊加。數據軸加法。大量訊號疊合在一起。
signal separation(signal decomposition)
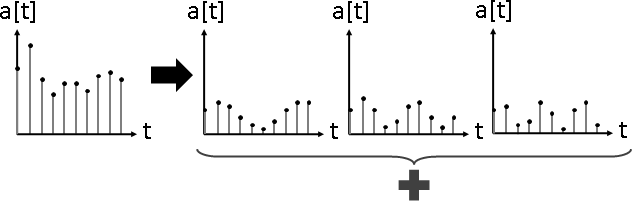
訊號分隔。數據軸分割。大量訊號疊合在一起,分隔每道訊號。
trend中線, seasional週期, cyclic峰谷, noise雜訊
yₙ = tₙ + sₙ + cₙ + nₙ
https://www.abs.gov.au/websitedbs/d3310114.nsf/4a256353001af3ed4b2562bb00121564/5fc845406def2c3dca256ce100188f8e
https://cran.r-project.org/web/packages/deseats/readme/README.html
演算法(Henderson moving average)
Spencer
https://robjhyndman.com/papers/movingaverage.pdf
https://mathworld.wolfram.com/Spencers15-PointMovingAverage.html
演算法(Whittaker–Henderson filter)
regularization,追加平滑程度。
min { sum wₙ (yₙ - tₙ)² + λ sum (dⁿ/dxⁿ tₙ)² }
t n n
演算法(Hodrick–Prescott filter)
平滑程度改成二階差分。擁有公式解。
N N-1
min { sum (yₙ - tₙ)² + λ sum ((tₙ₊₁ - tₙ) - (tₙ - tₙ₋₁))² }
t n=1 n=2
公式解矩陣
https://en.wikipedia.org/wiki/Hodrick–Prescott_filter
https://en.wikipedia.org/wiki/Smoothing_spline
Why you should never use the Hodrick–Prescott filter
https://www.nber.org/system/files/working_papers/w23429/w23429.pdf
An Exploration of Trend-Cycle Decomposition Methodologies in Simulated Data
https://papers.ssrn.com/abstract=3539317
演算法(smoothing spline)
迴歸函數換成spline。
N N-1
min { sum (yₙ - fₙ)² + λ sum (d²/dx² fₙ)² }
f n=1 n=2
where f is spline