set
set

set是指數學名詞「集合」。在這裡我們只考慮元素為整數的集合。集合有幾點特性:
一、空集合。
二、集合中的元素不會重複。
set
set
set是指數學名詞「集合」。在這裡我們只考慮元素為整數的集合。集合有幾點特性:
一、空集合。
二、集合中的元素不會重複。
set資料結構: 循序儲存
array

要表達一個集合,可以直觀的用一條一維的int陣列:將集合裡的所有元素,依序放入陣列中。再用一個變數,記錄元素總數。
如果熟悉C++標準函式庫,那麼使用vector更方便!
然而,以這種資料結構,做聯集、交集、差集之類的運算,相當麻煩,速度慢。時間複雜度是O(AB),A和B是元素數量。
可以直接使用C++標準函式庫的set_union()、set_intersection()。
UVa 496 12069
list

原理就和array完全一樣。array是一個一個數字連著放,list則是一個一個數字連成串。
set資料結構: 索引儲存
array
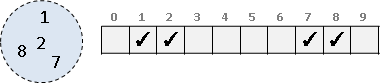
另外一種表達集合的方法,是用一條一維的bool陣列:集合裡若有x這個元素,就讓array[x]這個位置為true,否則為false。
它的壞處就是數值有界限、受陣列大小影響。然而,以這種資料結構,做聯集、交集、差集之類的運算,相當輕鬆,速度快。時間複雜度是O(R),R是陣列大小。
UVa 608 665 10227 12650
bit array(bit vector)(bitset)

還可以進一步以bit代替bool變數。bit只有0和1兩種值,類似於bool變數,兩者都可以用來表示一個元素存不存在。利用bit們來表達集合,可以節省儲存空間,也可以節省運算時間。
一個int變數,記憶體大小是32 bit,可以充作32個數字的集合。想要更多bit,那就建立一條陣列吧!
可以直接使用C++標準函式庫的bitset。
UVa 11218
set資料結構: hash table
hash function【這不是資料結構】
int hash(一筆資料) {return 一個數值;}
一筆資料重新表示成一個數值。該數值稱作雜湊值。

資料庫的觀點:資料進行索引,以利管理。密碼學的觀點:資料進行編碼,以求隱蔽。
理想情況是相同資料有著相同雜湊值、相異資料有著相異雜湊值,如此就能直接使用雜湊值來分辨資料。
可以直接使C++標準函式庫的hash()。
hashing【這不是資料結構】
array[ hash(一筆資料) ] = 一筆資料;
繁中「雜湊」,簡中「散列」。一筆資料套用hash function得到雜湊值,作為陣列索引值,用陣列儲存資料。設計hash function時,必須確保雜湊值不會超出陣列邊界。

無論是相同資料、相異資料,只要有著相同雜湊值,就會儲存到陣列的同一個格子。此時有三種應對方案:
一、每個陣列元素皆改為list,串接資料。
二、放到下一格;如果下一格已經使用,就再往下一格。
三、新資料直接覆蓋舊資料。
此處以一為主。插入的時間複雜度是O(1)。刪除、搜尋的最佳時間複雜度是O(1),相異資料有著相異雜湊值;最差時間複雜度是O(N),相異資料有著相同雜湊值。
hash table
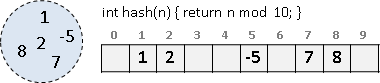
當元素的數值範圍很大,甚至元素不是整數,此時可以利用hash function得到一個索引值,而不會超出陣列邊界。
數值範圍小,索引儲存是首選,省時間費空間;數值範圍大,循序儲存是首選,省空間費時間。hash table兩者兼具,介於中間。
可以直接使用C++標準函式庫的unordered_set、unordered_multiset。
cuckoo filter

建立多個hash function。當陣列格子已有資料,就換hash function、換雜湊值。
有興趣的讀者,可以自行上網搜尋資料。
Bloom filter
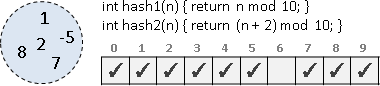
套用多個hash function,同時儲存於多個欄位,分散風險。只要發現對應欄位幾乎都是1,就推定元素存在於集合當中。缺點是可能製造原本不存在的元素。
如果懶得設計hash function,可以用兩個湊出多個:hashᵢ(n) = hash₁(n) + i ⋅ hash₂(n)。關鍵字Kirsch–Mitzenmacher。
有興趣的讀者,可以自行上網搜尋資料。
set資料結構: 樹狀儲存
binary search tree
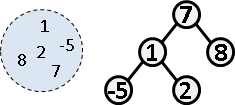
只要是可以儲存大量數字的資料結構,都可以用來儲存一個集合。因此二元搜尋樹當然也能勝任這項任務!
詳細內容請見本站文件「binary search tree」。
可以直接使用C++標準函式庫的set,不過它沒有聯集、交集、差集等功能,必須自己另外設計程式碼。也許你內心有點芥蒂;沒錯,C++標準函式庫的set,的確是名不符實的set。
disjoint sets
disjoint sets
「互斥集」。一堆集合們,擁有的元素都不相同。也就是說,這些集合們之間沒有交集。
A = {1, 3, 7, 8}
B = {4, 5}
C = {2}
A、B、C構成disjoint sets。
D = {1, 2, 3}
A、B、C、D不是disjoint sets。
舉例來說,有十個學生,要製作分組報告,分成四組,這四組就是disjoint sets。
甲君、乙君、丙君、丁君、戊君、己君、庚君、辛君、壬君、癸君 共十人,分成了四組: 第一組:甲君、丙君、辛君、壬君 第二組:乙君 第三組:丁君、戊君、己君 第四組:庚君、癸君 這四組構成disjoint sets。
聯集、交集、差集,運算結果非常明顯。
merge、split、find
資料結構通常擁有「合併、分裂、尋找」三個功能。
互斥集的情況下,大家通常只使用合併、尋找。
也因此英文俗稱「merge–find set」,中文俗稱「并查集」。中文俗稱源自「合并merge、并集union」和「查找find」。
合併merge:兩個集合合併成一個集合。(此處等同聯集union) 分裂split:一個集合分裂成兩個集合。 尋找find:一個元素位在哪個集合。
disjoint sets資料結構: 循序儲存
disjoint-sets list
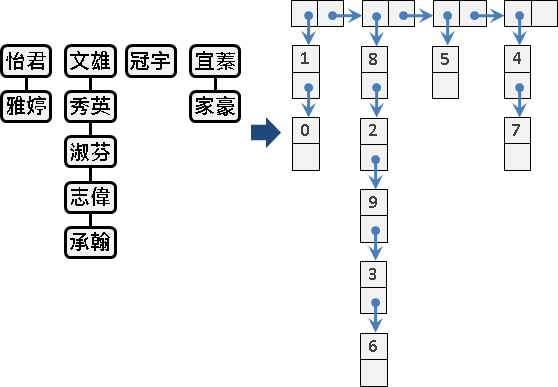
disjoint sets資料結構: 索引儲存
disjoint-sets array

讓一條int陣列的第x格代表第x人,格子裡填上這個人所屬的團體編號。若兩個人在同一團體,他們的格子裡就會有相同的團體編號。這是很直觀的方式。
初始化

一開始大家還沒開始分團的時候,其實可以想做是:每個人都不同團,每個人都是自己一人一團。有個方便的初始值設定方法,就是將第x格的值設成x,這樣每個人就都是不同團體的了。
find: 找出一個人在哪一團?

直接看團體編號。
equivalent relation: 兩個人是否同團?
直接看團體編號。
merge: 兩個人想合併自己所屬團體
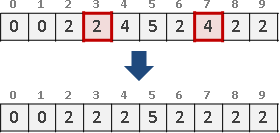
現在有兩團想要合併成一團,交涉的人分別是x和y。x y想要合併成一團,只要把所有與x y同團的人,都填上同一個團體編號就行了。取x 和y其中一團的團體編號,當作新的團體編號,如此一來就不需要額外的編號了。
number of sets: 全部總共幾個團體?
兩團合併成一團後,團體數就會減少一團。只需修改一下merge的程式碼。
cardinality of a set: 一個團體總共幾個人?
一個一個數是差勁的方法:
比較好的方法是:另外建立一條陣列去記錄每個團體的人數吧!陣列第x格填入團體編號為x的人數。要找出一個團體的人數,就直接從陣列裡面找。
以團體的觀點來看:兩團合併成一團後,團體人數就會改變。以人的觀點來看:當一個人所屬的團體被改變時,就調整人數。所以只要修改一下merge的程式碼就可以了。
根據團體的人數多寡來做merge
合併團體時,將小的團體併入大的團體,可以節省一點點設定團體和增減人數所需的時間。
singleton set: 團體是否合併過?
自己一個人一組,沒有merge過。
時間複雜度
merge是O(N),find、equivalence、cardinality、singleton是O(1)。
如果有N個人,全部的人都merge過一遍,每次merge要花O(N)時間,總共花O(N²)時間。
空間複雜度
如果有N個人,需要一條N格的陣列,O(N)。
disjoint sets資料結構: 樹狀儲存
disjoint-sets forest
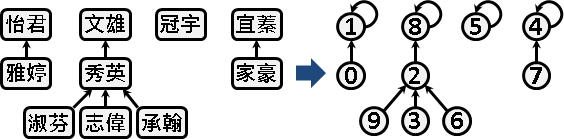
原理正是圖論的「有向森林」。
讓一條int陣列的第x格代表第x人──不過,格子裡改成填上x的老大是誰:
彷彿是老鼠會,以萬流歸宗的方式,來代表這個人是團體的大頭目。團體的所有成員,他們往上追溯之後,都是同一個頭目。一個團體中,只會有一個頭目,由他來支配團體、作為團體的代表。
各位可能會有一個疑問:一個團體之中,每個人都有一個頭目,那麼頭目的老大是誰呢?可以姑且設定成自己。
一個團體就像是一棵分支很複雜的有根樹。這些團體構成了一叢森林,故名disjoint-sets forest。
初始化

一開始大家還沒開始分團的時候,可以想成是:每個人都不同團,每個人都是自己一人一團,自己當頭目。將第x格的值設成x,這樣每個人都是不同團體的頭目了。
find: 找出一個人在哪一團?

接下來談談頭目吧。頭目在一個團體之中扮演舉足輕重的角色,一個團體只會有一個頭目,所以可以用頭目作為一個團體的代表。
find的時候,可以把途中遇到的所有人,將其老大重設為頭目。如此一來下次find的時候就會變快了。
另外還有一種作法,把兩個迴圈減少為一個迴圈。把途中遇到的所有人,將其老大重設為老大的老大,而不是重設為頭目。
equivalent relation: 兩個人是否同團?
同一個團體中的成員,他們的頭目都是同一個人。要看兩個人是不是同一團,看看他們的頭目是不是同一人就行了。
merge: 兩個人想合併自己所屬團體
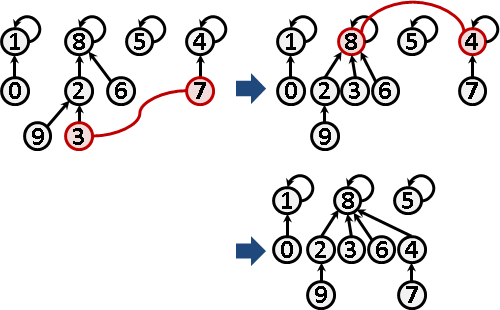
合併x y兩個團體,重新選出一個頭目。最簡單的方式是:讓x的頭目帶著他旗下所有小弟,投靠y團體的隨便一個人,如此一來兩個團體就擁有共同的頭目了,也依然保持著老鼠會的架構。
merge的時候,直接投靠對方的頭目,可以讓樹的深度增加最少。如此一來下次find的時候就會變快了。
實作小叮嚀:merge要確保投靠的人是頭目,投靠後頭目只有一個。另外也要避免同團體的人互相設定彼此是頭目,否則find會無限循環。
number of sets: 全部總共幾個團體?
兩團合併成一團後,團體數就會減少一團。只需修改一下merge的程式碼。
cardinality of a set: 一個團體總共幾個人?
先前提到頭目可以支配、代表一個團體,所以把焦點放在頭目上吧。另外建立一個陣列去記錄每個頭目帶領的人數,size[頭目] = 頭目帶領的人數。
兩團合併成一團後,團體人數就會改變。新頭目吸收人數;舊頭目則不再是頭目,毋須理會他帶領的人數。只需修改一下merge的程式碼。
根據團體的人數多寡來做merge
merge的時候,讓小的團體併入大的團體,可以讓樹的深度增加最少。如此一來下次find的時候就會變快了。
singleton set: 團體是否合併過?
自己一個人一組,沒有merge過。
empty set: 空集合
之前我們都未處理空集合。現在我們要改良資料結構,讓它可以處理空集合,而效率仍然保持一樣。
將陣列的第0格當作是一個空集合,不代表任何人。總人數如果有10人,那麼就要建立11格的陣列。第0格是空集合,第1格到第10格,分別代表著10個人。
現在既然有了空集合,便可將頭目的老大設定為空集合,更具義理。也就是說,初始化時要將陣列的初始值都改成0。
多了空集合,就要另外考慮和空集合做聯集。不管什麼集合,只要和空集合做聯集,集合都不會改變。凡是遇到空集合,就不必做聯集了。
其他部分大致不變,不再贅述。
時間複雜度
merge、find、equivalence、cardinality、singleton皆是O(logN)。值得一提的是,均攤時間皆是O(α(N)),其中α(N)是Ackermann function f(N,N)的反函數。
空間複雜度
如果有N個人,就需要一條N格的陣列,O(N)。
UVa 793 879 10158 10505 10583 10608 10685 11987 ICPC 4359