regression
regression
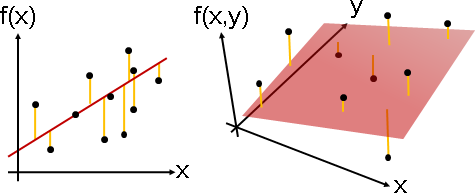
「迴歸」就是找一個函數,盡量符合手邊的一堆函數點。此函數稱作「迴歸函數」。
方便起見,以下用座標表示函數點。

error(loss)
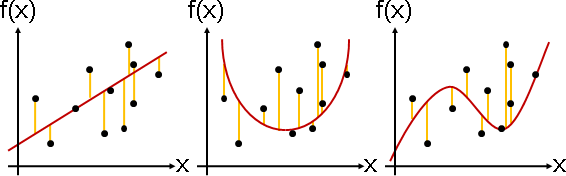
強硬地用函數符合函數點,就會有「誤差」。
單一函數點的誤差,有許多種衡量方式,一般是用函數點與函數的差的平方(平方誤差),其他還有函數點與函數的差的絕對值(絕對值誤差)。
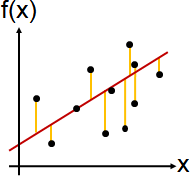
regression化作optimization
人腦考慮的「最符合」,放到了電腦就被設定成「誤差總和最小」。把誤差總和寫成一個函數,迴歸問題就變成了最佳化問題!
運用最佳化演算法,求得誤差最小值,求得迴歸函數的係數。
迴歸函數
f(x) = ax² + bx + c
N個函數點
(x₀,y₀) ... (xɴ₋₁,yɴ₋₁)
每個函數點的平方誤差
(y₀ - f(x₀))² ... (yɴ₋₁ - f(xɴ₋₁))²
所有函數點的平方誤差總和
e(a,b,c) = (y₀ - f(x₀))² + ... + (yɴ₋₁ - f(xɴ₋₁))²
= ∑ (yᵢ - f(xᵢ))²
= ∑ (yᵢ - ŷᵢ)²
= ∑ ‖yᵢ - ŷᵢ‖²
令誤差總和最小
min e(a,b,c)
a,b,c
選定一個最佳化演算法,求出e(a,b,c)的最小值,求出此時a b c的數值,
就得到迴歸函數f(x)。
迴歸函數
f(x) = ax² + bx + c
N個函數點
(2,3) ... (7,8)
每個函數點的平方誤差
(3 - f(2))² = (3 - (a⋅2² + b⋅2 + c))²
= 9 - 24a - 12b - 6c + 16ab + 4bc + 8ac +
16a² + 4b² + c²
:
:
(8 - f(7))² = (8 - (a⋅7² + b⋅7 + c))²
= 64 - 784a - 112b - 16c + 686ab + 14bc + 98ac +
2401a² + 49b² + c²
所有函數點的誤差總和
e(a,b,c) = (3 - f(2))² + ... + (8 - f(7))²
= (3 - (a⋅2² + b⋅2 + c))² + ... + (8 - (a⋅7² + b⋅7 + c))²
= ......
令誤差總和最小
min e(a,b,c) = ......
a,b,c
squared error / absolute error
平方誤差後盾雄厚,絕對值誤差樸實無華。大家採用平方誤差。
因為平方誤差非常實用,所以許多人將「採用平方誤差、令誤差總和最小」直接稱作「最小平方法least squares method」。
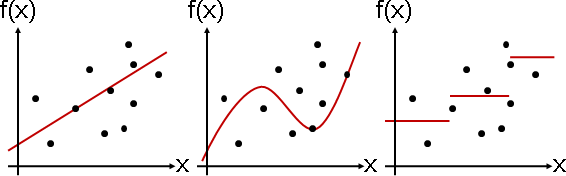
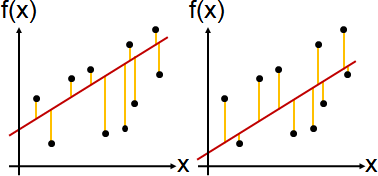
一、平方誤差通常有唯一解。絕對值誤差通常有無限多解。
絕對值誤差當中,當迴歸函數上下函數點不一樣多,那麼迴歸函數將朝向函數點較少的一側移動,降低絕對值誤差。當迴歸函數上下函數點一樣多,那麼迴歸函數可以上下移動,絕對值誤差保持相同。
絕對值誤差當中,答案總是均分函數點,答案可能不唯一。這種符合方式太過樸素、缺乏內涵。答案其實就是中位數。
二、平方誤差支援微積分,容易推導數學公式。
微積分經典定理:「極值位於一次微分等於零的地方」。藉由一次微分,得以判別誤差函數最小值,甚至得以推導公式。
平方誤差函數,處處皆可一次微分。絕對值誤差函數,至少有一處無法一次微分,只能改用次微分,事情變得相當複雜。
三、平方誤差支援線性代數,擁有強悍數學性質。
線性代數經典定理:「平方誤差盡量小=垂直投影」。藉由垂直投影,得以推導公式,讓這種符合方式擁有了具體形象。
當誤差函數既是平方誤差函數、又是線性函數,那麼可以使用線性代數。絕對值誤差函數則無法使用線性代數。