string資料結構: array
array
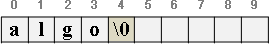
字串的字元依序填入陣列,最後用一個特殊符號標記字串結尾。
要不然也可以記錄最後一個字元的索引值、指標,這樣就不用加特殊符號。要不然也可以記錄字串長度,數值比前者多一。
缺點是插入字元、插入字串很慢,後方字元必須通通往後挪。
可以直接使用C++標準函式庫的string。
UVa 10252
string
string
「字串」。一連串字元。
例如aaabbbccc、48Dfua@~!0H、m、How are you?。
字串的長度,就是字元數目。有個特例是空字串:一個字元都沒有的字串,長度為零的字串。通常標記成Ø。
character
「字元」。字串的基本單元。
例如字串How are you?的字元依序為:H、o、w、 、a、r、e、 、y、o、u、?。第一個字元是H,第四個字元是空白符號 ,最後一個字元是問號?。
例如字串「你好嗎?」的第二個字元是「好」,第四個字元是全形問號「?」。
ASCII table規定了電腦中基本的128種字元,包括大寫小寫英文字母、標點符號、阿拉伯數字、數學運算符號、雜七雜八的符號。
substring
「子字串」。字串當中的一段字串。
例如algo的子字串一共是Ø, a, l, g, o, al, lg, go, alg, lgo, algo。
prefix
「前綴」。字串開頭的一段字串。
例如algo的前綴一共是Ø, a, al, alg, algo。
suffix
「後綴」。字串尾端的一段字串。
例如algo的後綴一共是Ø, o, go, lgo, algo。
sequence
「序列」或「數列」。一連串字元。
例如aaabbbccc、48Dfua@~!0H、m、How are you?。
字元在電腦當中其實是數字。字串在電腦當中其實是數列。
字串與數列唯一的差異在於:字串的字元是有限多種,數列的數字是無限多種。屏除這項差異,字串與數列完全相同。
字串學當中,習慣譯作「序列」而不是「數列」。序列可以是一串字元或者一串數字,而數列只能讓人聯想到一串數字。
subsequence
「子序列」。字串當中由左到右挑取字元所構成的字串。
例如algo的子序列一共是Ø, a, l, g, o, al, ag, ao, lg, lo, go, alg, alo, ago, lgo, algo。
UVa 10340
string資料結構: array
array
字串的字元依序填入陣列,最後用一個特殊符號標記字串結尾。
要不然也可以記錄最後一個字元的索引值、指標,這樣就不用加特殊符號。要不然也可以記錄字串長度,數值比前者多一。
缺點是插入字元、插入字串很慢,後方字元必須通通往後挪。
可以直接使用C++標準函式庫的string。
UVa 10252
string資料結構: rope
大量string資料結構: array
dictionary
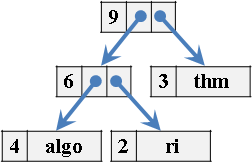
儲存大量字串的資料結構,大家通稱為dictionary。就好比擁有即時排序功能的資料結構,大家通稱為priority queue。
這些泛稱是用來凸顯資料結構的功能。有了這樣的泛稱,當遇到的問題隱含著字典的概念,就能直覺聯想到dictionary資料結構,而不會被array、BST這種不直覺的名稱困住了思考。
array

各種經典的資料結構,皆可儲存大量字串,例如陣列。
hash table
使用字串雜湊函數,將字串化作索引值,存入hash table。
經典的字串雜湊函數有djb2、sdbm、murmur3。
可以直接使用C++標準函式庫的hash()。我不確定是murmur哪一版。
大量string資料結構: binary search tree
binary search tree
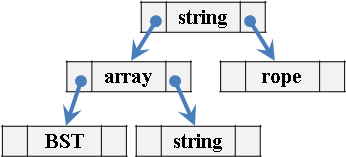
二元搜尋樹,一個節點儲存一個字串。
UVa 148 156 245 642 630 10295 10282 10686 10896 429 10150
ternary search tree
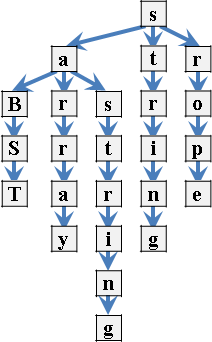
三元搜尋樹,一個節點儲存一個字元。左小孩是更小與相同的字串,右小孩是更大的字串,中小孩是原字串的後續字元。三元搜尋樹與二元搜尋樹等價。
大量string資料結構: trie
trie【翻譯成「櫥」似乎不錯】
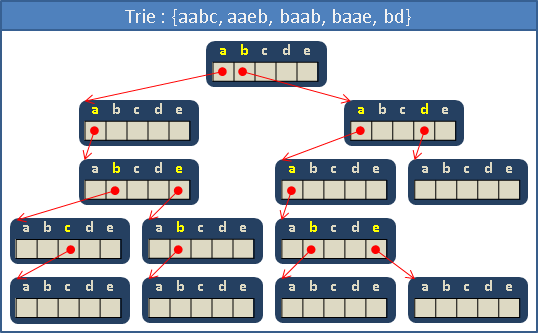
trie是一棵特別的樹,一條由根往葉的路徑是一個字串。節點含有陣列,以陣列索引的方式進行紀錄,每一層的節點分別對應字串的每一個字元。
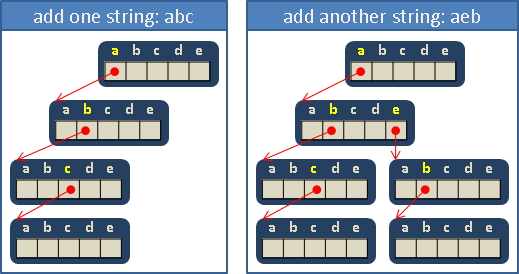
舉個簡單的例子。假設字元只有abcde五種。
儲存字串abc:由樹根往下走,每一層的節點依序對應字串的每一個字元。多出來的樹葉,用來標記字串結尾,可以想成是'\0'。
再儲存字串aeb:開頭相同的部分,歸併在一起。
這種儲存字串的方式,類似於編排字典的方式,減低了檢索單字的困難度。trie可以想作是多層次的索引表。
相信各位對trie的儲存方式已經駕輕就熟了。優點是速度飛快,缺點是耗費記憶體。最後提供trie的常見圖示方式。

UVa 902 10226 10391 10745
設計trie的節點
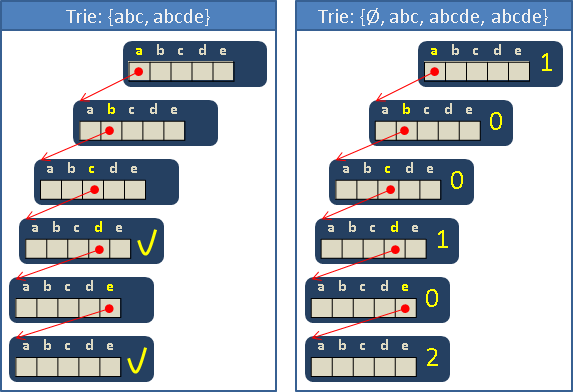
ASCII一共有128種字元,一個節點只需要一條128格陣列。
如果遇到abc和abcde這種一個字串是另一個字串的前綴的例子,就無法判斷字串結尾。此時必須用一個變數判斷字串結尾。如此一來也可以儲存空字串了。
如果字串可以重複出現,就用一個變數累計出現次數。
初始化。大功告成。
增加一個字串
時間複雜度O(S),S是字串長度。
尋找一個字串(判斷字串存不存在)
時間複雜度O(S),S是字串長度。
依照順序印出所有字串
DFS走訪每個節點。時間複雜度等同於trie的節點數量。
釋放記憶體空間
寫了new而不寫delete是大逆不道的事情!一定要記得寫!
double-array trie
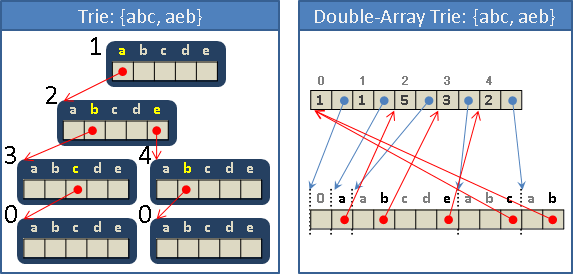
所有節點合併成一條極長陣列,另外用一條陣列記錄節點大小、節點位置。
優點是刪除了trie的陣列末端空格,缺點是必須動態配置節點大小、節點位置。省空間、費時間。
動態配置節點,大可不必自己實作,可以直接使用malloc/free、new/delete。
compressed trie
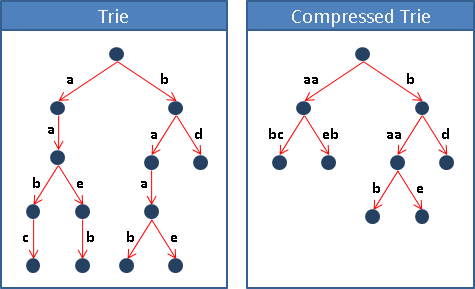
去掉沒有分岔、呈一直線的節點。
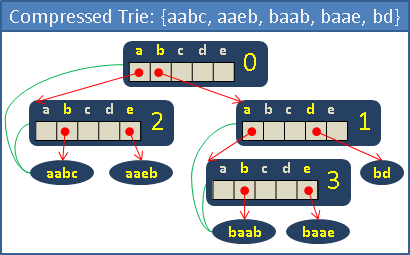
去掉節點之後,字串資訊不完整,必須做點處理:
一、每個節點增加一個數字,記錄當前是第幾個字元。也就是開始分岔的字元。
二、在樹葉裡儲存完整字串。每個節點增加一個指標,記錄當前節點要參考哪一個樹葉的字串。
三、或者,在節點裡儲存片段字串,代價是必須動態配置字串空間大小。省空間、費時間。
大量string資料結構: automaton
automaton
自動機主要用於字串驗證(string verification)。依序讀取字串的各個字元,同時在自動機上移動;一旦字串讀取完畢、正好抵達自動機終點,那麼字串驗證成功。
自動機亦可用於字串搜尋(string searching)。許多字串搜尋演算法,都可以順勢建構自動機。
自動機的特色是:仰賴一個lookup table,只需要反覆查表,就能完成字串驗證、字串搜尋,而不需要特別的演算法。
以圖論的觀點來看,先前章節都是用樹來儲存字串,此處則是用圖來儲存字串。然而圖的結構太過複雜,導致自動機難以建構,也無法直接插入字串、刪除字串、枚舉字串,只能搜尋字串。
列出字串很慢,驗證字串很快,自動機有著NP-complete、one-way function的味道。
UVa 251 738 804 ICPC 4358
DAWG
online compact DAWG
string operation
string operation
程式語言的標準函式庫,已經囊括所有常見的字串操作函式,建議讀者仔細研究。
UVa 483 492
以下額外整理了一些稀奇古怪的字串操作。通常只會出現在求職面試的益智測驗,平常極少用到。
rotate
循環移位n個元素,只使用swap、不使用額外空間。時間複雜度O(N)。
Lyndon word是指所有旋轉結果當中,字典順序最小者。時間複雜度O(N)。
UVa 719 ICPC 2755
要判斷兩個字串旋轉後是否相等,時間複雜度O(N)。
要判斷兩個字串旋轉後是否相等,也可以運用字串比對:判斷aa是否出現b,時間複雜度O(N)。
interleave
字串A之中,由左到右參差穿插字串B,判斷是否可以形成字串C。
A和B的全部字元就是C的全部字元。A和B都會是C的子序列。
A = abc B = xyz C = axbycz, xaybzc, abxycz, abcxyz, xyzabc, ...... C != cbaxyz, abyxcz, ......
當A和B沒有共同的字元,得以採用greedy method,時間複雜度O(A+B)。
當A和B有共同的字元,只能採用dynamic programming,分割問題的方式等同longest common subsequence,時間複雜度O(AB)。程式碼就不提供了。
cover
從字串A找出最短的子字串,包含字串B每一種字元。時間複雜度O(N)。
http://www.cs.ucr.edu/~stelo/cpm/cpm10/23.pdf http://www.cas.mcmaster.ca/~bill/best/algorithms/02AllCovers.pdf http://stackoverflow.com/questions/2459653 input string 1: "this is a test string" input string 2: "tist" output string: "t stri" how can I approach towards finding smallest substring of string 1 that contains all the characters from string 2? O(N) histogram
concatenate
給定一個長字串與一堆短字串。現在要將短字串銜接成長字串,短字串得重複使用。判斷是否只有唯一一種銜接方式。
Sardinas–Patterson algorithm。