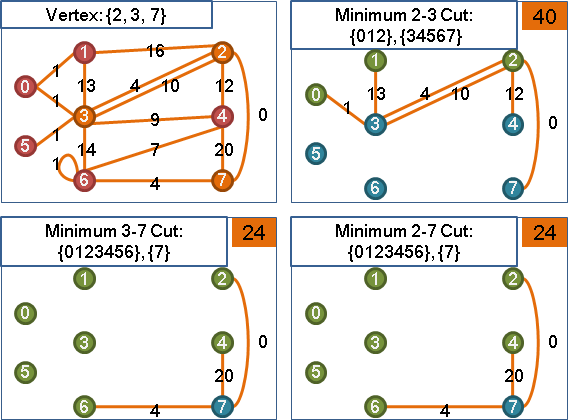
用途
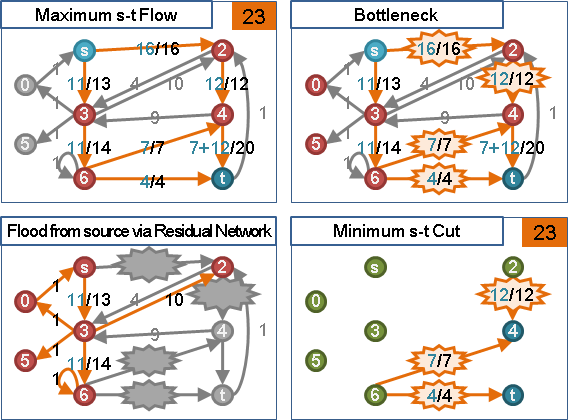
無向圖,無法指定源點與匯點,求出任意一個最小源匯割。
限制:無負邊。
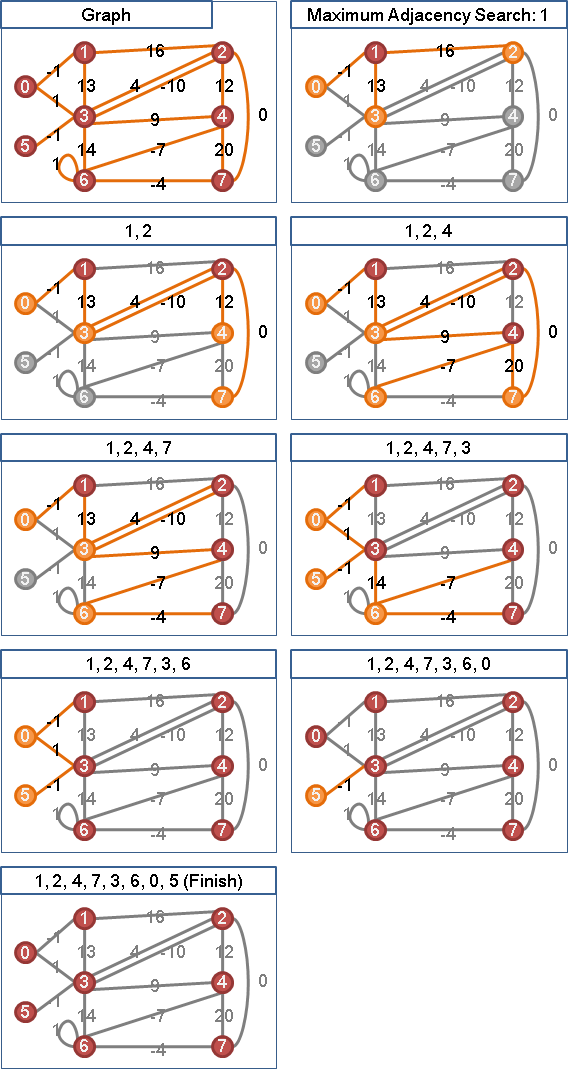
maximum adjacency search
「maximum cardinality search」引入權重。每回合找到一個點,連往已拜訪點的權重總和最多。若不只一點,則任選一點。
時間複雜度O(V²)。運用binary heap壓至O(V+ElogV)。運用Fibonacci heap壓至O(E+VlogV)。
當圖上無負邊,
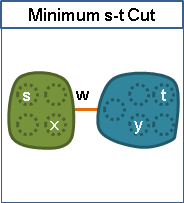
maximum adjacency search最後兩點形成minimum s-t cut
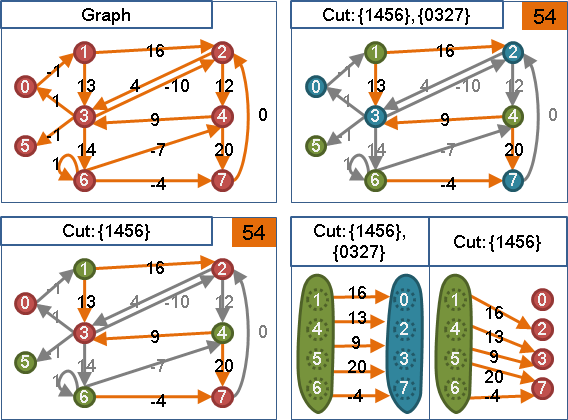
令maximum adjacency search的遍歷順序是v₁…vₙ,最後兩點是vₙ₋₁與vₙ。
當圖上無負邊,{v₁…vₙ₋₁}與{vₙ}是一個最小vₙ₋₁vₙ割。
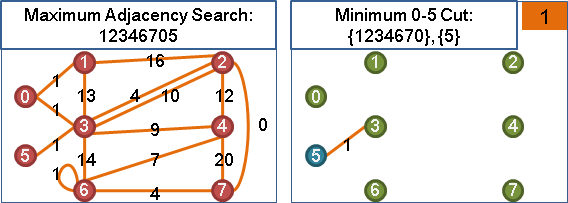
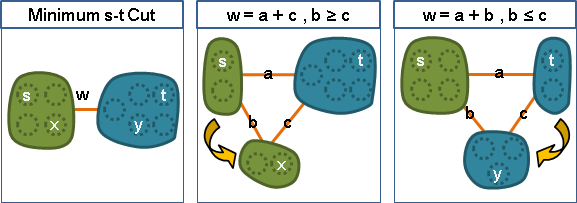
一、欲證cut(v₁⋯vₙ₋₁, vₙ)是最小vₙ₋₁vₙ割。
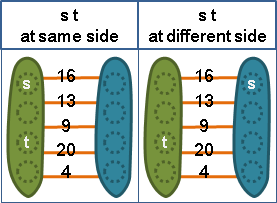
二、觀察vₙ₋₂與vₙ₋₁與vₙ這三點,根據共側性質,
最小vₙ₋₂vₙ₋₁割、最小vₙ₋₂vₙ割、最小vₙ₋₁vₙ割,
其中權重比較小的那兩個割,權重相等。
三、嘗試找到最小vₙ₋₂vₙ₋₁割、最小vₙ₋₂vₙ割,
並且證明cut(v₁⋯vₙ₋₁, vₙ)的權重同時小於等於這兩個割,
那麼根據共側性質,cut(v₁⋯vₙ₋₁, vₙ)就一定是最小vₙ₋₁vₙ割。
四、以下用數學歸納法證明,但是以反方向講解。
basis step:
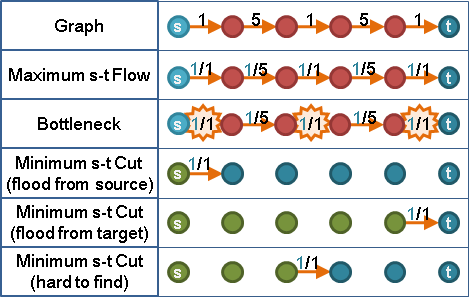
圖上只有兩點一邊時,顯然是一個最小st割。
inductive step:
一、從圖上移除邊vₙ₋₁vₙ,
不影響vₙ₋₁vₙ割的位置,刪除也無妨。
二、最小vₙ₋₂vₙ₋₁割的部分:
甲、從圖上移除vₙ(以及連著的邊)。
重新實施maximum adjacency search,順序仍舊相同,vₙ₋₂與vₙ₋₁成為最後兩點。
遞迴求解,證得cut(v₁⋯vₙ₋₂, vₙ₋₁)是一個最小vₙ₋₂vₙ₋₁割。
乙、因為vₙ₋₁與vₙ兩點之間沒有邊,
把vₙ(以及連著的邊)加回到cut(v₁⋯vₙ₋₂, vₙ₋₁)的vₙ₋₂側,
得到cut(v₁⋯vₙ₋₂ + vₙ, vₙ₋₁)是原圖的一個最小vₙ₋₂vₙ₋₁割。
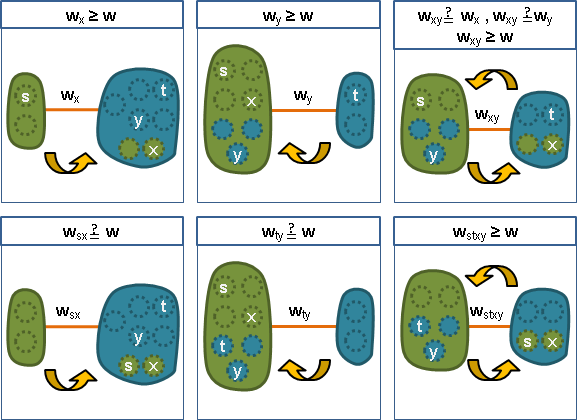
丙、由maximum adjacency search倒數第二步的選擇,可知
cut(v₁⋯vₙ₋₂, vₙ₋₁) ≥ cut(v₁⋯vₙ₋₂, vₙ)
又因為vₙ₋₁與vₙ兩點之間沒有邊,
cut(v₁⋯vₙ₋₂ + vₙ, vₙ₋₁) ≥ cut(v₁⋯vₙ₋₂ + vₙ₋₁, vₙ)
顯然地,
cut(v₁⋯vₙ₋₂ + vₙ, vₙ₋₁) ≥ cut(v₁⋯vₙ₋₁, vₙ)
也就是說,cut(v₁⋯vₙ₋₁, vₙ)的權重小於等於最小vₙ₋₂vₙ₋₁割。
三、最小vₙ₋₂vₙ割的部分:
甲、從圖上移除vₙ₋₁(以及連著的邊)。
重新實施maximum adjacency search,順序仍舊相同,vₙ₋₂與vₙ成為最後兩點。
遞迴求解,證得cut(v₁⋯vₙ₋₂, vₙ)是一個最小vₙ₋₂vₙ割。
乙、因為vₙ₋₁與vₙ兩點之間沒有邊,
把vₙ₋₁(以及連著的邊)加回到cut(v₁⋯vₙ₋₂, vₙ)的vₙ₋₂側,
得到cut(v₁⋯vₙ₋₂ + vₙ₋₁, vₙ)是原圖的一個最小vₙ₋₂vₙ割。
丙、顯然地,
cut(v₁⋯vₙ₋₂ + vₙ₋₁, vₙ) = cut(v₁⋯vₙ₋₁, vₙ)
也就是說,cut(v₁⋯vₙ₋₁, vₙ)的權重小於等於最小vₙ₋₂vₙ割。
四、由二丙、三丙,得證。
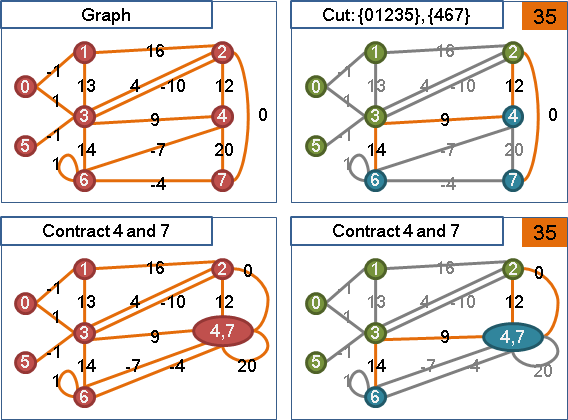
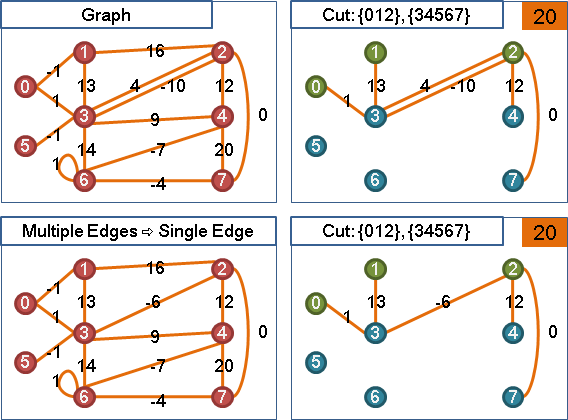
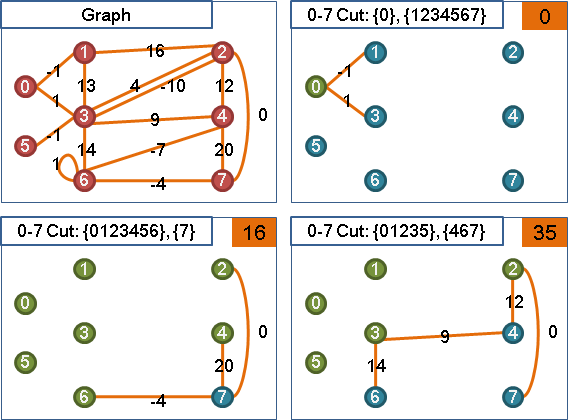
minimum cut
收縮源點與匯點,重做maximum adjacency search,總共計算V-1次源匯最小割,其中最小者就是最小割。
這個演算法後來被Stoer和Wagner重新提起。也許是因為他們倆的論文內容更加簡單明瞭,於是演算法名稱就變成他們倆了。