audio
audio
感受「聲音sound」是人類的本能。音樂、說話、風吹草動蟲鳴鳥叫等等聲響,都是「聲音sound」。
與科技裝置有關係的聲音,則稱作「聲音audio」。電視播放的聲音、電話通話的聲音等等,都是「聲音audio」。
sample
聲音源自振動。耳膜感受空氣振動,在腦中產生聲覺。
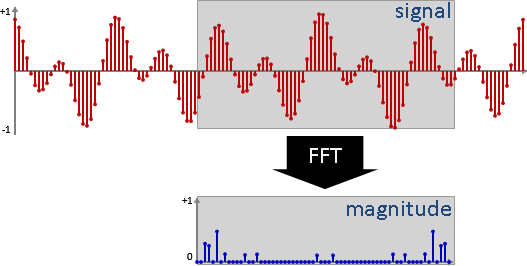
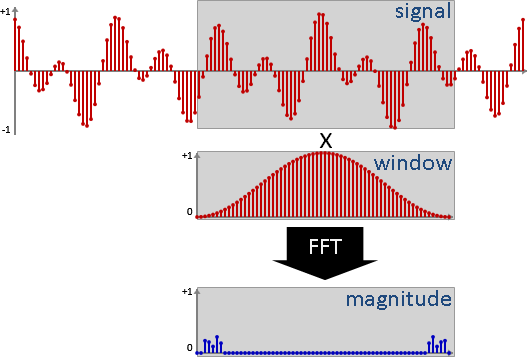
要讓電腦處理聲音,必須預先讓聲音變成數字,也就是讓聲音經過「取樣sampling」與「量化quantization」兩個步驟。取樣把時間變成離散,量化把振幅變成離散。
先取樣(得到數列),再量化(四捨五入),最後得到一串整數數列。每個數字稱作「樣本sample」或「訊號signal」。
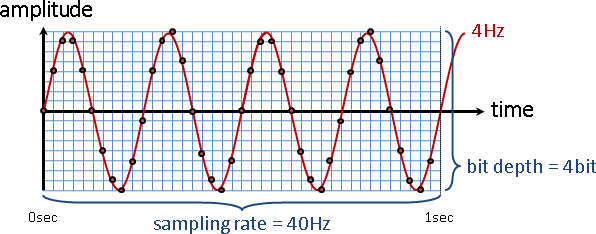
「取樣sampling」與「量化quantization」的關鍵參數:
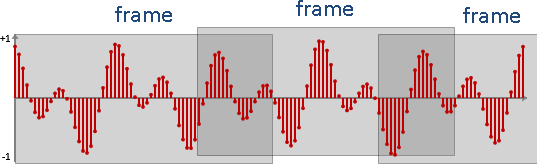
duration持續時間:聲音總共多少秒。數值越高,訊號越多。
sampling rate取樣頻率:一秒鐘有多少個訊號。數值越高,音質越好。電腦的聲音檔案,通常採用48000Hz或44100Hz。手機與電話的聲音傳輸,公定為8000Hz。
bit depth位元深度:一個訊號用多少個位元記錄。數值越高,音質越好。電腦的聲音檔案,通常採用16-bit或24-bit。16-bit的每個訊號是[-32768,+32767]的整數,符合C語言的short變數。
channel聲道:同時播放的聲音訊號總共幾條。每一條聲音訊號都是一樣長。舉例來說,民眾所熟悉的雙聲道,其實就是同時播出兩條不同的聲音訊號。
取樣頻率、持續時間、聲道,相乘之後就是訊號數量。再乘以位元深度,就是容量大小。再除以8,可將單位換成byte。
順帶一提,不管是聲音或者是其他信息,只要是經過取樣與量化得到的資料,總稱PCM data。「脈衝編碼調變pulse-code modulation, PCM」源自訊號學,所以名稱才會如此不直覺。
audio的資料結構
在電腦當中,聲音是很多串整數數列,資料結構是陣列。
各種聲音資料的取樣頻率和時間長度不盡相同。統合方式:動態陣列、可變長度陣列。
各種聲音資料的位元深度不盡相同。統合方式:採用32-bit浮點數,讀檔後將訊號數值縮放成[-1,+1],才進行聲音處理;存檔前調回原本範圍。
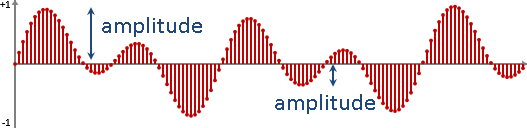
amplitude
聲音訊號的數值,代表空氣振動的幅度。基準訂為0,範圍訂為±32767(當位元深度是16-bit)。也有人使用其他設定。
振幅高,聽起來大聲。振幅低,聽起來小聲。
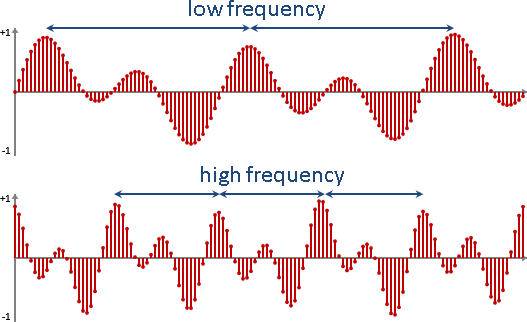
frequency
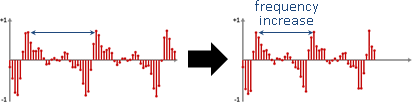
人類擅於感受的不是振動的幅度,而是振動的頻率。
頻率高,聽起來尖銳。頻率低,聽起來低沉。
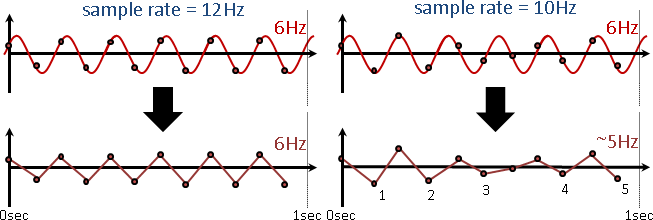
順便介紹「取樣定理」:x Hz的波,取樣頻率至少要是2x Hz,才能明確分辨上下次數,頻率保持相同(而振幅總是失真)。
也就是說,取樣頻率48000Hz,頂多只能記錄24000Hz以下的聲音。但是別擔心,人類聽覺範圍是20Hz至20000Hz。
使用C/C++處理聲音
C與C++本身沒有處理聲音的函式庫。
你可以土法煉鋼,選擇一種聲音檔案格式,例如WAV、MP3、AAC、FLAC,研讀其規格書,設計程式讀取聲音擷取訊號。
你也可以拍手煉成,直接使用現成的函式庫,例如AudioFile、LAME,呼叫函式讀取聲音擷取訊號。
使用C/C++與作業系統處理聲音
只有「聲音播放器」和「聲音特效」,沒有「聲音訊號處理」。
你可以土法煉鋼,選擇一種作業系統,安裝其開發工具,使用其應用程式介面,播放聲音訊號、製造聲音特效。例如Windows API的XAudio2、Linux kernel的Advanced Linux Sound Architecture、MacOS使用的OpenAL與Audio Units、Android NDK的OpenSL ES。
你也可以拍手煉成,直接使用功能齊全的工具,例如VST、RTAS。
使用C#/Java/Qt處理聲音
讀取聲音,例如C#是援引Windows API、Java的AudioInputStream、Qt的QAudioInput與QAudioOutput。這些語言的處理機制都不一樣,自己看著辦吧。
播放聲音,例如C#的SoundPlayer、Java的AudioClip、Qt的QSound。這些語言的處理機制大同小異,函式名稱既統一又直覺,例如play、pause、volume、loop。
處理聲音。函式庫發展不完善,你必須自行編寫程式碼。
結果就是,學生和教師傾向使用MATLAB或Python。
使用Python處理聲音
Python本身擁有讀取聲音的函式庫wave。
Python本身沒有播放聲音的函式庫,必須另行安裝。例如播放聲音playsound、即時播放聲音PyAudio。
Python本身沒有處理聲音的函式庫,必須另行安裝。例如分析聲音pyAudioAnalysis、處理音樂librosa。
使用HTML與JavaScript處理聲音:聲音播放器
以HTML建立<audio>,就能播放聲音。
以JavsScript動態建立<audio>,也能播放聲音。
先以HTML建立<audio>。再以JavaScript擷取<audio>,指定聲音檔案名稱。這種混搭風格,也能播放聲音。
重視網頁排版的情況下,適合使用混搭風格。
讓使用者自行選擇聲音檔案(甚至影片檔案)。
使用HTML與JavaScript處理聲音:聲音訊號
<audio>只是一個播放器。我們無法直接從<audio>得到訊號,必須額外使用AudioContext。
一、程式員事先指定檔案。寫作風格是新潮的promise串聯。
fetch()下載檔案 Response.arrayBuffer()取得檔案全文 AudioContext.decodeAudioData()擷取聲音訊號
二、使用者自行選擇檔案。寫作風格是古典的callback套娃。
<input>選擇檔案 FileReader.readAsArrayBuffer()取得檔案全文 AudioContext.decodeAudioData()擷取聲音訊號
三、儲存檔案。因為缺少AudioContext.encodeAudioData(),所以必須自己寫一個。我使用現成的riffwave.js,儲存成WAV。
RIFFWAVE.Make()生成檔案全文 其中RIFFWAVE.wav是檔案全文 其中RIFFWAVE.dataURI是超連結、附帶檔案全文 MouseEventst.initEvent()自動點擊超連結
瀏覽器為了安全起見,預設禁止讀取本機檔案。如果你想用本機檔案做實驗,你必須修改瀏覽器設定。做好實驗記得改回來。
Firefox 網址列輸入 about:config security.fileuri.strict_origin_policy 的值改為 false Chrome 命令列輸入 chrome.exe --allow-file-access-from-file
或者正常做法是建立本機網頁伺服器。
使用HTML與JavaScript處理聲音:聲音工具組
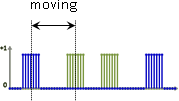
方才介紹批次處理:一口氣取得所有訊號。現在介紹串流處理:不斷獲得一段訊號。
AudioContext的構造是圖論的有向無環圖。從起點一路串聯到終點,形成流程圖。
節點可以是聲音訊號(起點)。
MediaElementAudioSourceNode 播放器<audio> MediaStreamAudioSourceNode 網路串流 OscillatorNode 波形產生器 AudioBufferSourceNode 自訂訊號
節點可以是聲音效果(中繼點)。
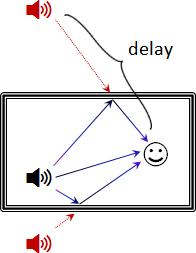
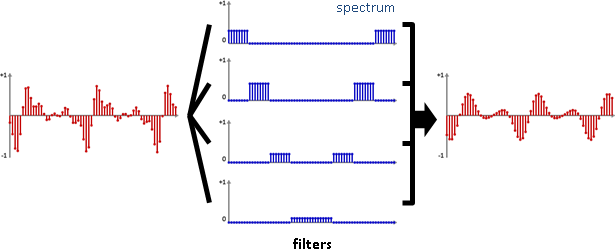
GainNode 音量 ConvolverNode 迴響 PannerNode 指向 BiquadFilterNode 濾波器 AudioWorkletNode 自訂效果
節點可以是聲音效果的參數(起點)。
ConstantSourceNode 常數 AudioScheduledSourceNode 開關
節點可以是聲音輸出裝置(終點)。
AudioDestinationNode 喇叭 AnalyserNode 頻譜 MediaStreamDestinationNode 錄音(存檔)
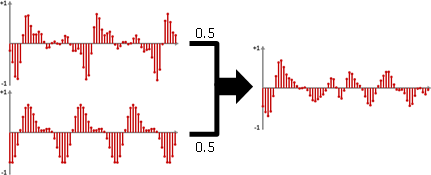
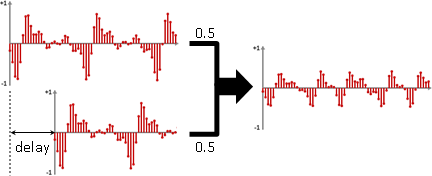
一旦開始播放起點之聲音訊號,就會自動套用中繼點之聲音效果。(至於合成效果,是將多個節點接往相同節點。)
起點是<audio>。
起點是波形產生器。
起點是自訂訊號。利用createBuffer()建立一串聲音訊號。利用createBufferSource()建立起點。
中繼點是音量。
中繼點是濾波器。
中繼點是自訂效果。過程非常麻煩,必須另外建立一個JavaScript檔案,利用AudioWorklet載入JavaScript檔案。
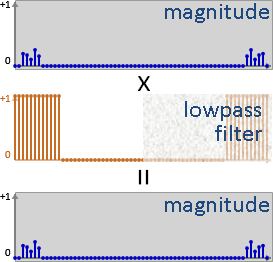
終點是頻譜。
終點是錄音。利用MediaRecorder,將一段一段的訊號,連成一整串訊號,便於存檔。
使用現成工具處理聲音