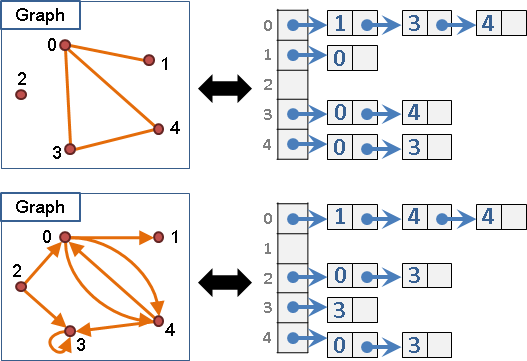
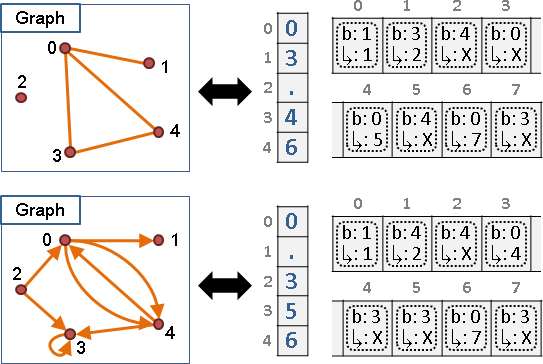
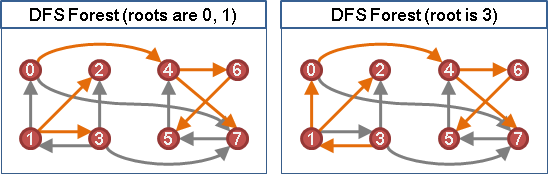
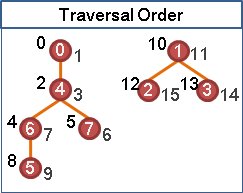
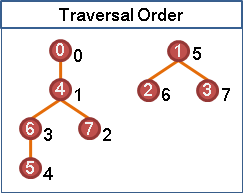
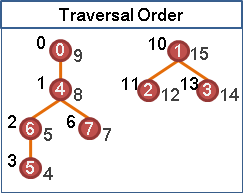
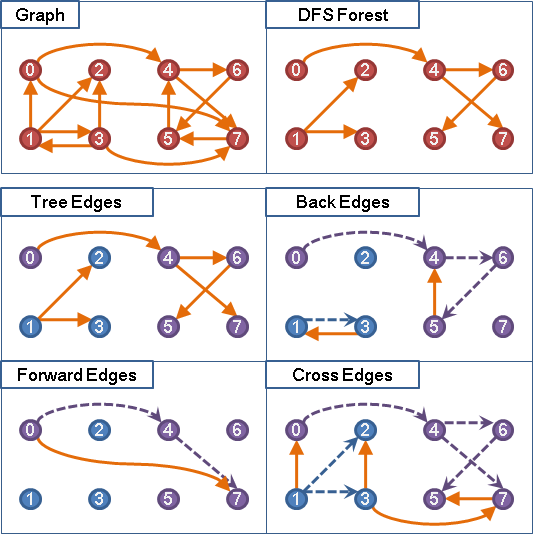
graph
graph
graph中文翻做「圖」。此處談及的「圖」並不是指圖片或者圖形。「圖」是一種用來記錄關聯、關係的東西。
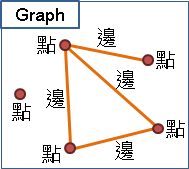
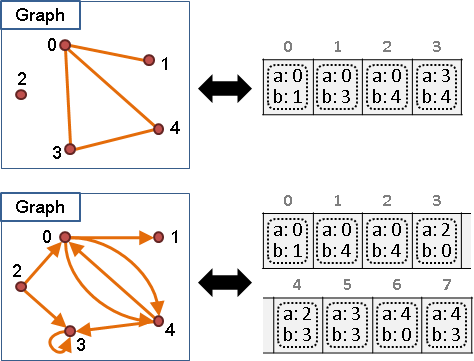
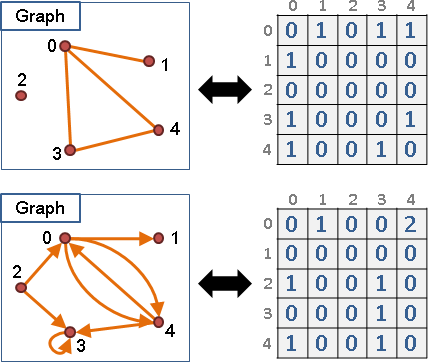
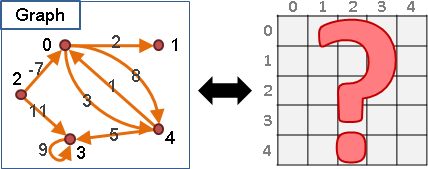
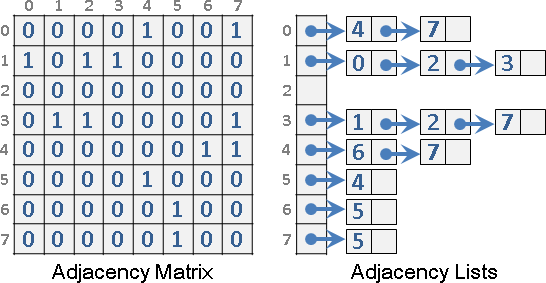
一張圖由數個點(vertex)以及數條邊(edge)所構成。點與點之間,得以邊相連接,表示這兩點有關聯、關係。
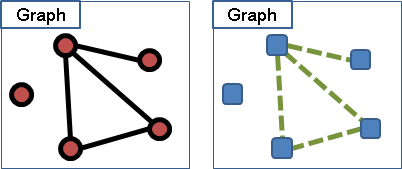
點的大小形狀和線的粗細長短是無所謂的,我們只在乎它們如何連接。只要連接的關係對了,要怎麼畫都行,簡約、雅觀、平易近人即可!
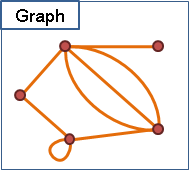
兩點之間也可以有很多條邊,甚至有自己連到自己的邊。兩點之間有很多條邊,代表這兩點有很多項關聯。一個點有自己連到自己的邊,表示自己和自己有項關聯。
isomorphism / isomorphic
isomorphism中文譯作「同構」,isomorphic中文譯作「同構的」。如果兩張圖的連接方式一模一樣時,則稱作「同構」。
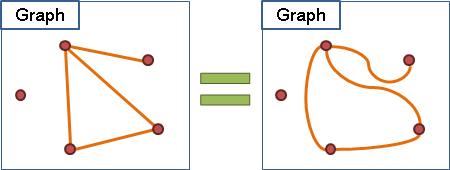
圖上的邊可以是直的,也可以是彎彎曲曲的,也可以是交錯的。不論邊的形狀如何,都不會改變點與點之間的關聯、關係,終究都會是同構的圖。
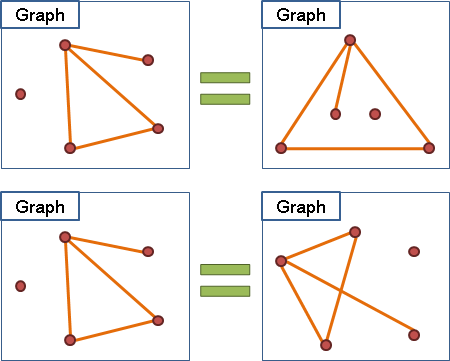
圖上的點可以任意移動位置。不論點的位置如何,都不會改變點與點之間的關聯、關係,終究都會是同構的圖。
同構的圖擁有相同的資訊,所以不管選擇哪一張圖都是可以的,只要清楚易懂就可以了!
directed graph(digraph)

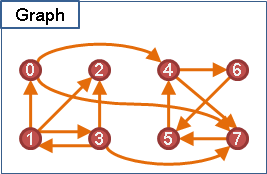
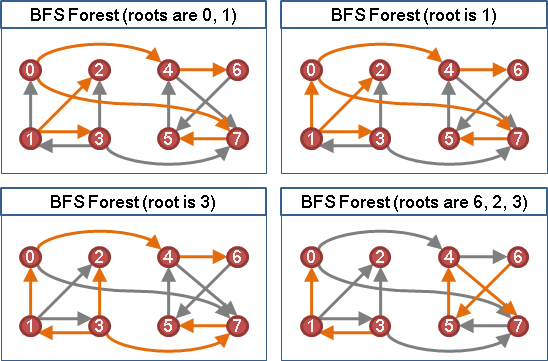
邊甚至可以擁有方向性,用來表示兩點間的關係是單向的,並非雙向的。無向邊代表雙向關係,有向邊代表單向關係。
一張圖若都是沒有方向性的邊,稱作「無向圖」;一張圖若都是有方向性的邊,則稱作「有向圖」。如果圖上有一些邊是單向的,有一些邊是雙向的,那我就不知道那該叫做什麼圖了。
替點和邊加上權重
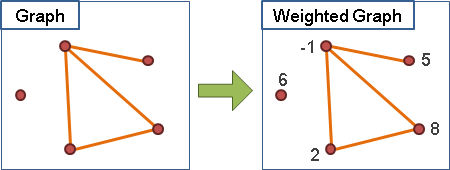
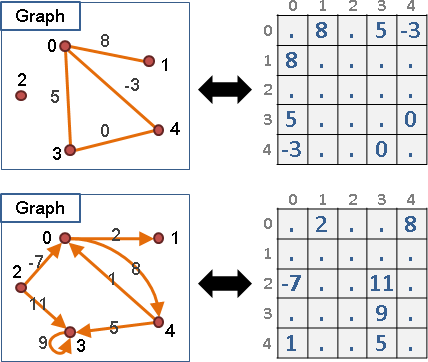
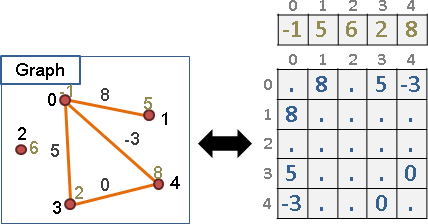
圖上的點可以擁有權重,可做其他用途。
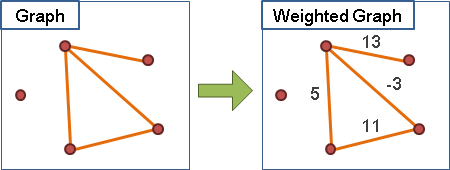
圖上的邊可以擁有權重,可做其他用途。
替點和邊取名字、代號
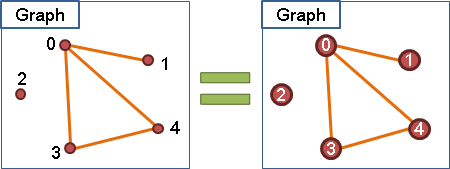
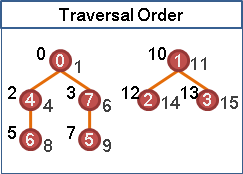
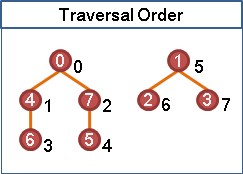
點和邊上面可以取名字、代號,方便辨認。名字、代號可以寫在點和邊的旁邊,也可以寫在點的裡面、邊的上面,只要能表達清楚就好。
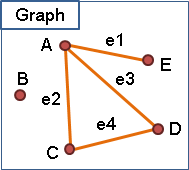
名字可以隨便取,簡單明瞭就好。書上通常是用英文字母及數字居多。