|
關聯詞分析、索引典自動產生
緣由與目的:
- 長久以來,「字彙不匹配」(vocabulary mismatch),一直是資訊檢索系統
使用者檢索失敗的主要原因之一。
所謂「字彙不匹配」問題,就是使用者查詢時下達的詞彙與系統用以索引文件的
詞彙不相同的情況。
例如,不同的文件可能出現「筆記型電腦」、「筆記本電腦」或「筆記本型電腦」
等用詞不一致的情況,如果系統直接以原文件的詞彙建立索引
(建索引的目的是要加快查詢比對的速度),
當使用者下達「筆記本電腦」時,對於包含意義相同但詞彙字串不同的文件,
就有可能因為比對不正確,造成漏檢或失敗的情況。
- 圖書館學的理論中,早已注意到此種現象,並提出像「權威檔」與
「索引典」等工具來解決這個問題。
「權威檔」(authority file)中記錄了各種同義異形詞,使得索引或檢索時,
各種意義相同但形式不同的詞彙,可以對應起來,而被視為相同的詞彙處理。
如上述的「筆記型電腦」與「筆記本電腦」,或「行政院長」與「閣揆」,
或「老人癡呆症」與「老人失智症」等詞彙,都可透過權威檔的運用,
在索引與檢索時視為相同的詞彙。
-
而「索引典」(thesaurus)則進一步紀錄詞彙之間更多的關係,除同義詞外,
還有反義詞、廣義詞、狹義詞、相關詞等,用以擴展或縮小檢索詞彙的主題範圍。
例如「筆記型電腦」與「掌上型電腦」的概念很接近,都可視為「攜帶型電腦」
的狹義詞。相對的,「攜帶型電腦」可視為這兩個詞的廣義詞,
透過廣義詞的擴展,運用查詢詞「筆記型電腦」可找出包含「掌上型電腦」
的文件。
-
「索引典」列舉詞彙之間的關係,用於查詢詞的互相推薦,以擴大或縮小查詢範圍,
或提示相關概念的不同查詢用語,使檢索從原本的字串比對層次,
提升到以語意做比對的層次。
-
為了建構此種詞彙之間語意上的關係,往往需要人工分析與整理。
人工製作索引典的優點是正確性高,缺點則是成本大、建構速度慢、
維護不易、以及事先選用的詞彙可能與後續或其他新進的文件無關。
過去資訊檢索實驗的研究指出,一般目的(general-purposed)的索引典運用
在特定領域的文件檢索上,會出現無法提升檢索效能的情形。
-
索引典雖然捕捉了詞彙之間的語意落差,索引典涵蓋的詞彙主題,
卻可能與文件的主題有所落差,而達不到以索引典提升檢索成效的目的。
一個極端的例子,是將人文科學方面的索引典運用在工程科學文獻的檢索上,
其檢索效果當然難以彰顯。然而針對每一種文獻領域製作索引典,卻又耗時費力。
-
因此,根據文獻本身的主題,自動且即時產生索引典的方法,是值得研究的主題。
-
自動化的方法,大抵都倚賴相關的詞彙在文件中常常一起出現的線索,
來建構索引典。此種方式建構出來的索引典,可稱為「共同出現索引典」
(co-occurrence thesaurus),或簡稱「共現索引典」。
本系統即針對此主題,提出筆者自行研發的方法,以自動建構中文文獻的
共現索引典。
-
雖然依此方法自動建構出來的索引典,其詞彙之間的語意關聯不像人工建構的
那麼精確、有明顯的屬性意義。但這些自動找出的關聯卻常透露出大量文件內
隱含而不易被人偵知的知識。
-
所以,此方法亦可視為是一種「知識探勘」
(Knowledge discovery or text mining) 的方法。
成效:
-
由於過去的作法,大都是針對英文文件發展而來,直接運用於中文時,
會面臨中文斷詞與未知詞的問題。
因此,筆者特別提出一套中文關鍵詞彙自動擷取作法,以利後續「關聯詞彙」
的分析。此關鍵詞擷取方法,目前已獲得中華民國發明專利。
-
另外,筆者也提出一套效率極高的關聯詞分析方法,將原先需要超級電腦運算
的計算量,降低成只需個人電腦即可負擔的計算量。
其擷取出來的關聯詞,可視為非結構化文字資料探勘的結果,
運用於檢索系統當中,可作為查詢提示、文獻摘要、或知識地圖等進階功能。
-
最後,筆者就自動建構出來的索引典詞彙,評估其關聯程度。
-
從二萬三千多篇文件中建構出來的關聯詞,
以精確率與召回率的方式評估,其平均精確率達 0.5284 ;
若以相關比例評估,有 69% 的提示詞被判訂與查詢詞相關。
- 從 十五萬多 篇文件中建構出來的關聯詞,
以精確率與召回率的方式評估,其平均精確率達 0.5690 ;
若以相關比例評估,有 78% 的提示詞被判訂與查詢詞相關。
- 亦即,文件數量越多,關聯詞彙效果越好。
-
和過去的類似研究相較,雖然評估的資料不同,但其其成效已超越過去研究
報告出來的數據。顯示此自動方法不僅快速、
適用於中英文,而且自動建構出來的索引典,有目前所知最好的品質。
系統特色:
- 自動分析中、英文詞彙。
- 自動擷取新生、未知詞(詞庫中未包含的詞彙)。
- 可立即運用於各種領域文件。
- 自動分析詞彙間的關聯程度。
- 單篇文件即可分析關聯詞彙。
- 詞彙擷取、關聯分析速度極為快速。
- 支援 Word、Office、PDF、XML、HTML、TXT 等各種檔案格式。
- 將資訊檢索從字串比對程度,提升到語意比對的程度。
- 運用在查詢提示,可透露出埋藏在文件中各種知識的關聯,
對便利使用者探索、發掘文件中記載的知識,提供了宛如專家在旁指導的
檢索輔助。
範例:
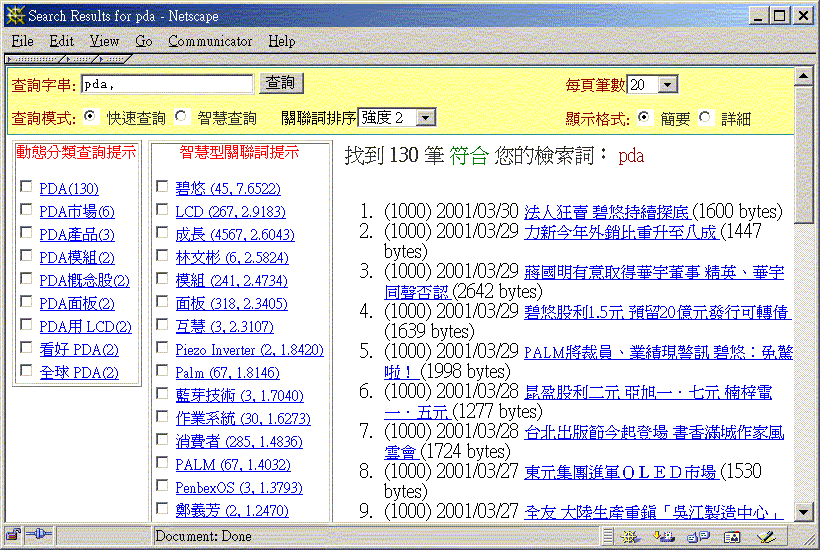
圖一:關鍵詞擷取與關聯詞彙分析運用於查詢提示的例子。
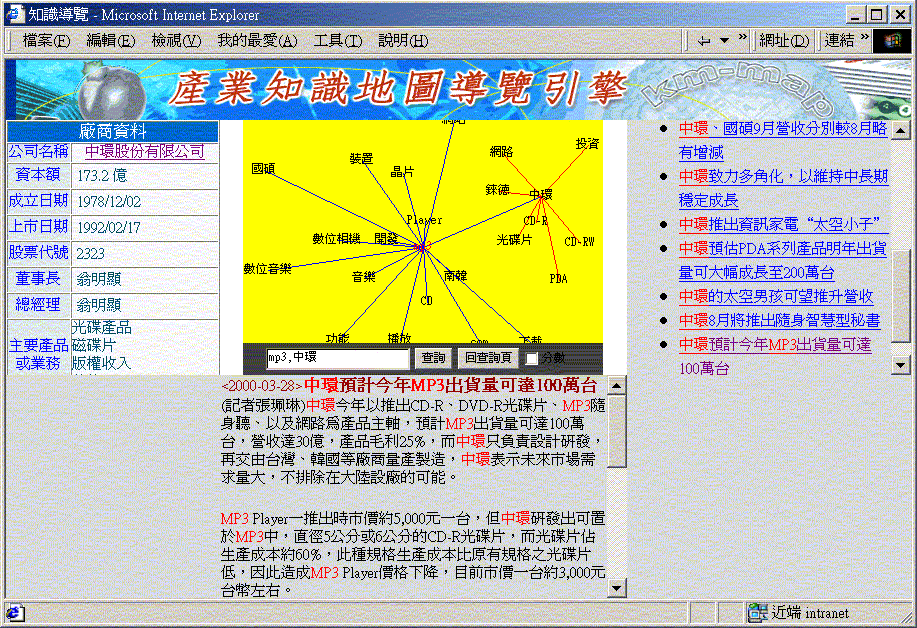
圖二:關聯詞彙運用於二維知識地圖的例子。
相關著作:
- Yuen-Hsien Tseng, "Automatic Thesaurus Generation for Chinese
Documents", Journal of the American Society for Information Science and
Technology, Vol. 53, No. 13, Nov. 2002, pp. 1130-1138.
- 曾元顯, "數位文件之資訊組織與主題分析自動化之技術與應用",
「台北市立圖書館館訊」, 2002 年 12 月, 第 20 卷, 第 2 期, 頁 23-35.
- 曾元顯, 林瑜一, "
模糊搜尋、相關詞提示與相關詞回饋在 OPAC 系統中的成效評估",
「中國圖書館學會會報 61 期」, 1998 年 12月, 第 61 期, 頁 103-125.
- 曾元顯, "共現索引典之自動建構、評估與應用",
台灣大學圖書資訊學系四十週年系慶研討會, 2001 年 11 月 16 日, 頁 87-105.
- Yuen-Hsien Tseng, "Fast Co-occurrence Thesaurus Construction for
Chinese News," Proceedings of the 2001 IEEE Systems, Man, and
Cybernetics Conference, 2001 IEEE International Workshop on Natural
Language processing and Knowledge Engineering (NLPKE 2001) in
conjunction with the IEEE International Conference on Systems, Man,
and Cybernetics SMC' 2001 Tucson, Arizona, USA, October 7-10, 2001,
pp.853-858.
相關計畫:
- 曾元顯, 「中文索引典之自動建構及其應用」,
國科會91學年度研究計畫報告, NSC 91-2413-H-030-012-。
Established on Jan. 1, 2000, last modified on April 15, 2004 by
Yuen-Hsien Tseng
<tseng@lins.fju.edu.tw>
|