CATAR is a software toolkit for users who would like to analyze a set of documents
(semi- or un-structured free-text data),
especially those publication records from Web of Science (WoS),
full-text technical patent documents (in HTML) from USPTO,
or any texts worth of analysis (Web pages, interview records, etc.),
for the purpose of strategic reading, planning, or research.
The content analysis that CATAR provides can be used to:
summarize the background of a research field (or industrial domain);
obtain an overview of the research topics and technical development;
get breakdown analysis of various actors (authors, institutes, countries);
CATAR was developed in Perl
language on MS Windows with MS Excel for data tabulation and MS Access as
its databases. So, you should have MS Windows and MS Office on your computer. Note:
After 2017/10/14, the CATAR version for Windows 10 uses
SQLite as its database.
For USPTO documents, MS Access is still used because many queries for patent analyses
are constructed in MS Access query commands, such that once the USPTO patent documents
are downloaded, around 20 overview graphs are ready for review.
In additional to MS Excel, Open Office
could be used to open the XLS files produced by CATAR.
For SQLite database, SQLite Browser
can be used to open the SQLite databases.
Below are the steps to prepare your computer to run CATAR:
(1) Download and Install Perl:
Firstly, download the latest Perl interpreter, e.g., Strawberry Perl at
http://strawberryperl.com/
for your computer.
Note: the 32 bits version is used to analyze USPTO patents.
Then install the downloaded Perl interpreter into your computer by following the installation steps
and choose the default settings.
Note: CATAR is free to use only to those individuals in education and
non-profit organizations (or institutes).
(3) Decompress CATAR to a target folder:
Decompress the downloaded CATAR file to the folder C:\CATAR.
After decompression, you should find the following sub-folders under C:\CATAR\
src : the folder where perl source codes of CATAR is located.
Source_Data : the folder to store your data for CATAR to analyze
(see later examples).
Result : the folder to hold the resulting files produced by CATAR;
doc : the folder that CATAR stores intermediate data during analysis;
So do not store your own data here (could be deleted by CATAR).
(4) Install Perl Modules (Packages):
Make sure your computer is connecting to the Internet.
If you get CATAR from https://github.com/SamTseng/CATAR,
then double click
C:\CATAR\src\install.bat to
execute package installation.
If there is no error report, you have installed CATAR successfully.
You can proceed to the next section: "3. Data Preparation"
If the above .bat did not work, mannually do this step with the following actions:
Open MS DOS (search cmd.exe in your computer and execute cmd.exe),
and then execute the following commands:
cpanm install Encode::Detect::Detector
cpanm install Statistics::Regression
cpanm install Math::MatrixReal
cpanm install Win32::ODBC
Install SAMtool:
Decompress
C:\CATAR\src\Perl_Module\SAMtool.rar
to C:\Strawberry\perl\site\lib
so that you see many Perl files under
C:\Strawberry\perl\site\lib\SAMtool\
CATAR is ready for the paper records downloaded from
Web of Knowledge
(i.e., WoK.
Note: WoS is a database in the WoK platform. So hereafter,
WoS and WoK are used interchangeably).
It means that CATAR knows how to read those downloaded files and
do the analysis right away without any further file conversion.
To know the desired record format needed by CATAR, please have a look at the
example files under Source_Data\sam\data.
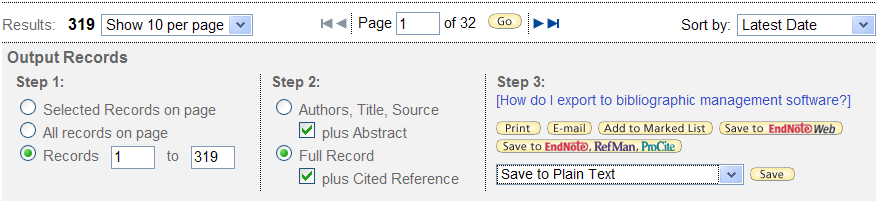
The following figure shows the options to save records from WoK
(Note: Since 2014, WoK has changed its interface.
So the screen shots below may not be the same interface you are using now.
But the download process remains similar).
Please check WoS_Record_Download.ppt
for instructions to download a set of records from WoS.
When downloading data from WoK, choose these options for correct content
and format.
CATAR is also ready for the patent files downloaded from
USPTO.
Just supply a list of patent numbers (patent IDs), and CATAR will
download them from USPTO (
PatFT and
AppFT only)
and analyze them for you. For details, please refer to:
https://github.com/SamTseng/CATAR.
For other types of documents you would like to analyze, please copy
the file at:
src\Paper_org.db to a new file of your own,
and insert your documents into table TPaper
in that new file. (You will need some skills about SQL commands.)
In fact, CATAR starts various analyses from this table in this new file.
You could check the example in the sub-folder: Source_Data\movie\movie.db.
general trends of the topics (or domains) represented by the documents;
most productive authors, institutes, or countries;
most cited references, authors, or journals;
Breakdown analysis based on
bibliographic coupling (BC);
(This is possible only when the CR (Cited Reference) field is available.)
Breakdown analysis based on co-word (CW, co-occurrence words) analysis.
The last two (breakdown analyses) identify the sub-topics revealed
in the document set and provide cross-tabulation analyses for each
sub-topic and actor
(such as most productive authors or institutes in a certain sub-topic).
The simplest way to use CATAR is to download the WoK data and save them in
an example folder and then run the command batch file corresponding to the
example folder.
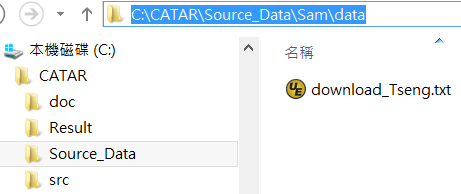
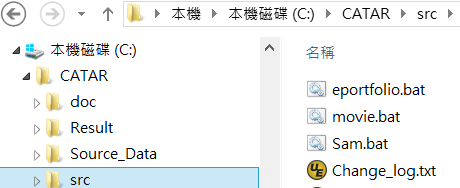
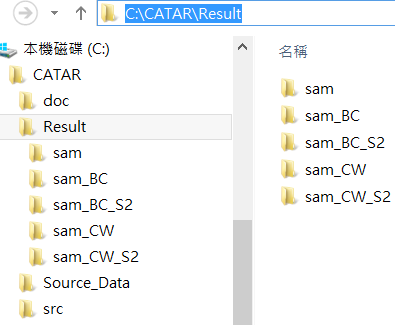
See the figures in the following for example. The left figure
shows the example folder where the downloaded data were saved. The middle
figure shows where the corresponding command batch file resides. Just double
click the batch file and CATAR will run all the three analyses from the start to
the end. The right figure shows the resulting folders after
all the analyses have been done.
To do individual analysis (or to know the meaning of CATAR commands in the
example batch files), the following examples explain the commands to run CATAR
under the MS-DOS
command console. To know them better, some familiarity with the concepts of
DOS commands, folders (directories), and file paths is preferable.
Now use the publication records in Source_Data\Sam\data as an example,
the overview analysis can be done with the command under DOS:
C:\CATAR\src>perl -s automc.pl -OOA Sam ..\Source_Data\Sam\data
The result is in Result\Sam\_Sam_by_field.xls.
In addition, the content in the record files was converted and saved
in Source_Data\Sam\Sam.db
for use by breakdown analysis.
For the breakdown analysis based on bibliographic coupling (BC), run the command:
C:\CATAR\src>perl -s automc.pl -OBC Sam ..\Source_Data\Sam\Sam.db
CATAR will prompt you with some questions during the analysis.
Accept the default answer if you do not know how to respond.
The result would be in the sub-folders starting with Sam_BC under the
Result\ folder.
To do the co-word analysis (CW), run the command:
C:\CATAR\src>perl -s automc.pl -OCW Sam ..\Source_Data\Sam\Sam.db
Also you will be prompted with some questions during the analysis.
Accept the default answer if you do not know how to respond.
The result would be in the sub-folders starting with Sam_CW under the
Result\ folder.
In summary, if the record set you want to analyze is called
SE and you place the WoK record files under
Source_data\SE\data\,
then the above three commands would become:
C:\CATAR\src>perl -s automc.pl -OOA SE ..\Source_Data\SE\data
C:\CATAR\src>perl -s automc.pl -OBC SE ..\Source_Data\SE\SE.db
C:\CATAR\src>perl -s automc.pl -OCW SE ..\Source_Data\SE\SE.db
Note:
you must run overview analysis before you can run breakdown analysis.
Limitations:
For the overview analysis, the document set can be as large as tens of
thousands of records.
For the breakdown analysis, the number of documents is limited to under 4000
for bibliographic coupling and under 3000 for co-word analysis due to
the memory limit (tested on a 2GB RAM computer).
The above breakdown analysis commands are for article clustering.
To do journal clustering, use the option
-OBC=JBC,
instead of only -OBC,
and -OCW=JCW,
instead of only -OCW.
For journal clustering, the number of documents can be tens of thousands of documents.
The results (in the Result folder) obtained from the above analyses require
your interpretation to make them useful. As how to make use of them
depends on your domain knowledge, insights, imagination, and maybe luck!
To help understand the abbreviated field names presented in all the results,
the following lists their meanings and examples:
AF: the authors' full names, such as Tseng, Yuen-Hsien (instead of Tseng, YH)
Note: authors' full names are available since 2007 (or 2006?) by WoK.
Before this year, the content of AF is empty or is identical to that of AU.
TI: publication title, e.g., METALEARNING AND CONCEPTUAL CHANGE;
SO: journal title, e.g., INTERNATIONAL JOURNAL OF SCIENCE EDUCATION;
J9: abbreviation of journal title, e.g., INT J SCI EDUC;
AB: publication's abstract;
C1: authors' countries (extracted from the authors' addresses in the original C1 field);
IU: authors' institutes/universities (extracted from the authors' addresses in the original C1 field);
DP: authors' departments (extracted from the authors' addresses in the original C1 field);
Note: Do not use this field for analysis if your data contains multiple universities,
because different universities may have the same department names.
TC: times cited, e.g., 60 means the publication has been cited by other sixty publications indexed by WoS up until the publication was downloaded;
PY: year of publication, e.g., 1989;
UT: primary key (record ID) of the publication used in WoS, e.g., WOS:A1989CY40300009;
SC: source categories given by WoS, e.g., Education & Educational Research
ID: identifiers given by WoK to describe the topics of the article, not the record ID;
DE: keywords given by the authors; In contrast, ID contains broader concepts, while SC contains even broader fields.
Note:
When interpreting the number of articles published by certain authors,
be careful about the possible problem of different authors sharing the same names
(AU or AF).
Some fields may have no content. For example, DE and ID may be empty
possibly due to: 1) the journal does not require keywords given by authors; 2) WoK did not
record DE or did not label ID. Before your analysis, you should check
CATAR's report for the number of empty records for each field (from the
above Sam's example, the report is in the _Sam_stat worksheet in
Result\Sam\_Sam_by_field.xls).
Try to avoid using the result from the field containing too many empty records.
Q: How to determine the threshold during the multi-stage clustering? A: The similarity measures, either based on bibliographic coupling or co-occurrence
words, are just an approximation to the "real similarity" of two documents.
For example, document A and B sharing the same 50% of their references
(or the same 50% words they used in their titles and abstracts)
do not necessary mean they are 50% in common in their topics.
It is only fair to say that A and B have higher probability to be in the same topic,
compared to the case of A and C, if A and C share only the same 10% of
their references (or the same 10% words ).
So insistence on computing an optimal similarity threshold for clustering is
not necessary.
This uncertainty in the similarity measure makes such an optimal threshold
somewhat unsure. (It may be a research question to know to what degree
a domain fit the methodology of bibliographic coupling and/or co-word analysis.)
Therefore, it is recommended that you explore as many thresholds as you can
and see which one leads to an interpretable result.
Q: In some cases, there are empty data in some fields, such as DE (author keywords),
ID (identifiers), or even AB (abstract). What can we do? A: These cases are quite common.
It may be due to the cases that the journal publisher did not provide such information
or the database provider (e.g., WoK, Thomson Reuters) did not add such information to
these fields.
Try to analyze and interpret the data with alternative ways. Avoid those results
from insufficient data.
Q: The papers included in the final stage of clustering are in small
number compared to the initial papers for analysis. For example, there may be
up to 50% percent of papers not included in the final clustering. Is this abnormal?
A: No. It is a common phenomenon that many items may be
regarded as outliers in clustering analysis. As can be imagined, although many
papers deal with major topics, there are many more dealing with
independent and probably less-noticed issues, which is a phenomenon similar
to the
long tail effect reflected in the online book sales statistics.
Since the independent issues are in large number, they were excluded
from the clustering. Like the other clustering analyses
(such as those based on singular value decomposition),
the multi-stage clustering used in CATAR tends to retain only some major topics
for clarity, especially when a non-zero threshold is applied to each
successive clustering stage.
Yuen-Hsien Tseng, Chi-Jen Lin, and Yu-I Lin,
"
Text Mining Techniques for Patent Analysis",
Information Processing and Management, Vol. 43, No. 5, 2007, pp. 1216-1247.
(SCI, SSCI, EI)
Yuen-Hsien Tseng, "Automatic Thesaurus Generation for Chinese
Documents", Journal of the American Society for Information Science
and Technology, Vol. 53, No. 13, Nov. 2002, pp. 1130-1138.
(SSCI and SCI)
Applications of CATAR were published in various domains:
Yi-Yang Lee, Yuen-Hsien Tseng, Wen-Chi Hung, and Michael Huang,
"The Application of Knowledge Mining to the Discovery of Trends
in Future Agricultural Technological Development"
Proceedings of the 10th International Conference on Science and
Technology Indicators, Sep. 17-20, 2008, Vienna, Austria, page 481-483.
From the above projects (most are small, experimental ones) and papers,
you can imagine that the CATAR presented here denotes only some
of the analysis tasks I have done so far. Many more experimental
analyses were not mentioned (due to the specificity of the requirements
and applications). This suggests that the analysis approaches
provided by current version of CATAR are the most mature ones.
If you have any idea of seeing unstructured data being analyzed in a
certain way which maybe novel and useful,
I would be happy to modify CATAR and include that way of analysis
in future versions, especially when this modification leads to a research
opportunity
. The only limit is my time and energy.