shortest unique substring
shortest unique substring
「最短唯一子字串」是只有出現一次的子字串當中,其長度最短者。可能有許多個。
minimal unique substring與maximal repeated substring
「極小唯一子字串」是局部極值,「最短唯一子字串」是全域極值,最短的「極小唯一子字串」就是「最短唯一子字串」。「極大重複子字串」與「最長重複子字串」也是類似的。
unique是出現一次,repeat是出現兩次以上,兩者之間有著強烈的互補關係。
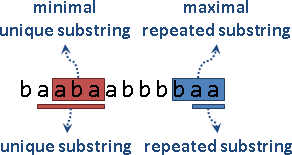
minimal unique substring是只有出現一次、盡量縮短的子字串。它包含的子字串(自身除外),全部都是重複子字串;包含它的子字串,全部都是唯一子字串。
maximal repeated substring是出現兩次以上、盡量延長的子字串。它包含的子字串,全部都是重複子字串;包含它的子字串(自身除外),全部都是唯一子字串。

按照定義,任取兩個minimal unique substring,絕不會互相包含。maximal repeated substring也一樣。
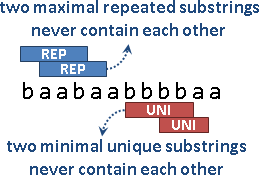
每當出現一個minimal unique substring,位置是[i, j],便存在兩個maximal repeated substring:一個結尾是j-1、開頭小於i;另一個開頭是i+1、結尾大於j。
每當出現一個maximal repeated substring,位置是[i, j],便存在兩個minimal unique substring:一個開頭是i-1、結尾小於等於j;另一個結尾是j+1、開頭大於等於i。
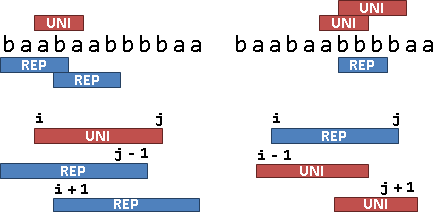
由此可知,minimal unique substring和maximal repeated substring是交錯出現的,兩者數量頂多差一。當原字串是De Bruijn sequence,兩者數量達到極限。
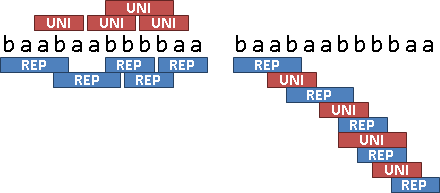
注意到,當原字串包含連續的unique character,那麼交錯出現、數量差一的結論就不成立了。此時刻意定義maximal repeated substring可以是空字串,以迫使結論成立。
給定所有的已排序的maximal repeated substring,
求出所有的minimal unique substring。
必須預先排序好。時間複雜度O(N),N是maximal repeated substring暨minimal unique substring的數量。
給定所有的minimal unique substring,
求出所有的maximal repeated substring。
必須預先排序好。時間複雜度O(N),N是maximal repeated substring暨minimal unique substring的數量。
求出所有的maximal repeated substring
時間複雜度O(N)。
求出所有的minimal unique substring
時間複雜度O(N)。