string searching: Morris–Pratt algorithm
© 2010 tkcn. All rights reserved.
想法
1.
T: aabzabzabcz
P: abzabc
2.
窮舉法,從左往右逐步挪動P。
aabzabzabcz aabzabzabcz aabzabzabcz
|||||| |||||| |||||| ......
abzabc abzabc abzabc
(X) (X) (X)
2.
仔細看窮舉法,是從左往右一一比對字元,一旦發現字元不同,就馬上往右挪動P。
V V V V
aabzabzabcz aabzabzabcz aabzabzabcz aabzabzabcz
| |X | ||
abzabc abzabc abzabc abzabc
V V V V
aabzabzabcz aabzabzabcz aabzabzabcz aabzabzabcz
||| |||| ||||| |||||X
abzabc abzabc abzabc abzabc
V V V V
aabzabzabcz aabzabzabcz aabzabzabcz aabzabzabcz
X X | || ......
abzabc abzabc abzabc abzabc
3.
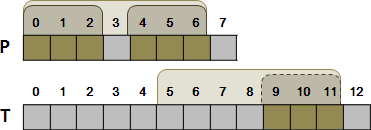
往右挪動P之前,當下比對成功的字串片段,abzab,其實可以好好利用!
V
aabzabzabcz -abzab-----
|||||X |||||
abzabc abzab-
4.
觀察窮舉法的步驟順序,繼續往右挪動P,挪動一個位置、挪動兩個位置、……。
-abzab----- -abzab----- -abzab-----
|||| ||| ||
abzab- abzab- abzab-
-abzab----- -abzab-----
|
abzab- abzab-
5.
換個觀點觀察上述行為。
挪動一個位置:看看abzab的後四個字元,是不是前四個字元。
挪動兩個位置:看看abzab的後三個字元,是不是前三個字元。
⋮ ⋮ ⋮
6.
如果我們預先知道abzab的「次長的相同前綴後綴」是ab,
就可以一口氣大幅挪動P,略過許多步驟:
V V
aabzabzabcz aabzabzabcz
|||||X ---> ||
abzabc abzabc
7.
從「V」處繼續向右一一比對字元。
每當比對失敗、遇到相異字元,
就故技重施,從當前比對成功的字串片段,取其「次長的相同前綴後綴」,大幅挪動P。
prefix-suffix【尚無正式名稱】
前綴等於後綴,稱作「相同前綴後綴」。一個字串通常有許多個「相同前綴後綴」。
prefix-suffix
abc --------------> {Ø, abc}
abcaa --------------> {Ø, a, abcaa}
abcabc --------------> {Ø, abc, abcabc}
ababa --------------> {Ø, a, aba, ababa}
aaaaa --------------> {Ø, a, aa, aaa, aaaa, aaaaa}
abaabaa --------------> {Ø, a, abaa, abaabaa}
abzab --------------> {Ø, ab, abzab}
border(longest proper prefix-suffix)
一個字串的「最長的相同前綴後綴」就是原字串,「最短的相同前綴後綴」就是空字串,「次長的相同前綴後綴」就是第二長的相同前綴後綴。「次長的相同前綴後綴」簡稱「邊框」。
border
abc -------> Ø
abcaa -------> a
abcabc -------> abc
ababa -------> aba
aaaaa -------> aaaa
abaabaa -------> abaa
abzab -------> ab
border table(prefix function)(failure function)
窮舉法的過程當中,當前比對成功的字串片段,是P的前綴。
因為我們無法預測是P的哪幾個前綴,所以我們可以預先計算P的每個前綴的邊框,預先建立「邊框表格」,以備不時之需!
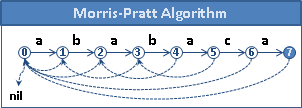
012345 P: abzabc prefix | border | border table | implementation -------|--------|----------------|---------------- Ø | Ø | f(Ø) = Ø | a | Ø | f(a) = Ø | border[0] = -1 ab | Ø | f(ab) = Ø | border[1] = -1 abz | Ø | f(abz) = Ø | border[2] = -1 abza | a | f(abza) = a | border[3] = 0 abzab | ab | f(abzab) = ab | border[4] = 1 abzabc | Ø | f(abzabc) = Ø | border[5] = -1
border table的演算法是dynamic programming。利用已知邊框,求得當前邊框。分割問題的方式是p[0...i]拿掉尾端字元p[i]。
【註:取名border table,由於函數輸出是border。取名prefix function,由於函數輸入是prefix。取名failure function,由於比對失敗就會使用它。】
演算法
一、預先計算P的每種前綴的「次長的相同前綴後綴」。 二、從左往右,依序比對字元。 口、當比對成功、遇到相同字元: 繼續比對下個字元。 口、當比對失敗、遇到相異字元: 從比對成功的字串片段,取其「次長的相同前綴後綴」,大幅挪動P。 口、當全部比對成功、搜尋到P: 就從比對成功的P,取其「次長的相同前綴後綴」,大幅挪動P。
時間複雜度
一、border table:字元兩兩比對次數最多2P次。
當比對成功,邊框長度增長;當比對失敗,邊框長度減短。總共增長P次、最多減短P次。邊框長度最多變動2P次。邊框長度變動次數即是字元兩兩比對次數。
二、字串搜尋:字元兩兩比對次數最多2T次。
原理同上。「邊框長度」改成「比對成功的字串片段長度」。
總時間複雜度O(T+P)。
UVa 455 10298 11475
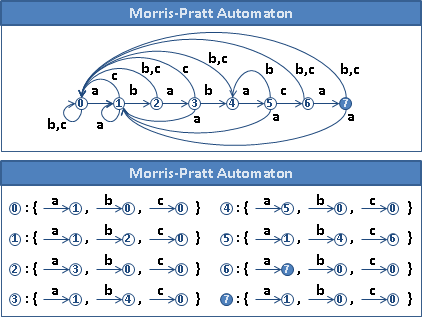
Morris–Pratt automaton
此演算法可以化作自動機,轉化的時間複雜度是O(PA),A為字元種類數目。
針對每個狀態,找出經由border table能到達的狀態們;建立轉移邊,連到那些狀態們的下一個狀態。
化作自動機之後,字串搜尋變得非常簡單,容易製作成電路。
ICPC 4842