single source shortest paths: Dijkstra's algorithm (label setting algorithm)
用途
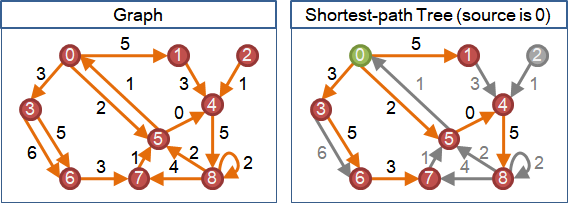
一張有向圖,選定一個起點,找出起點到圖上各點的最短路徑。即是找出其中一棵最短路徑樹。
限制是:圖上每一條邊的權重皆非負數。
想法
當最短路徑只有正邊和零邊,截去末端之後,仍是最短路徑,而且長度一定更短(也可能相同)。當有負邊,長度不會更短或相同,反而更長。
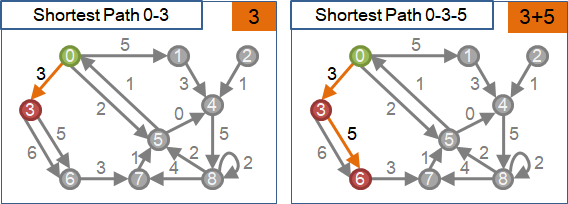
圖上有負邊,就必須使用label correcting algorithm。即使數值標記錯誤了,仍可修正。
圖上有負邊,則無法使用label setting algorithm。當下不在樹上、離根最近的點,以後不見得是最短路徑。
label correcting algorithm受負邊影響,不知道relaxation的正確順序,只好不斷修正每個點的最短路徑長度,直到正確為止。
label setting algorithm只有正邊、零邊,知道relaxation的正確順序,逐步設定每個點的最短路徑長度。
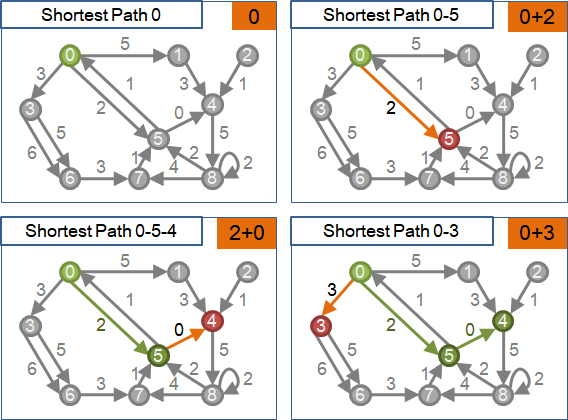
想法
當圖上每一條邊的權重皆非負數時,可以發現:每一條最短路徑,都是邊數更少、權重更小(也可能相同)的最短路徑的延伸。
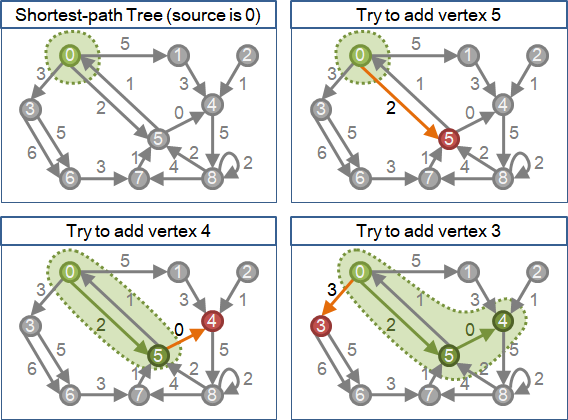
於是乎,建立最短路徑樹,可以從邊數最少、權重最小的最短路徑開始建立,然後逐步延伸拓展。換句話說,就是從距離起點最近的點和邊開始找起,然後逐步延伸拓展。先找到的點和邊,保證會是最短路徑樹上的點和邊。
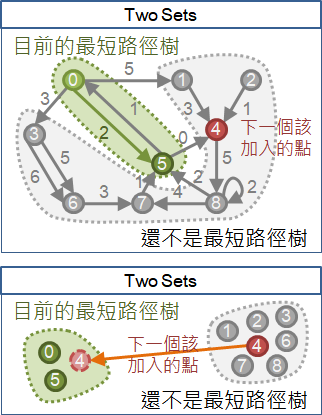
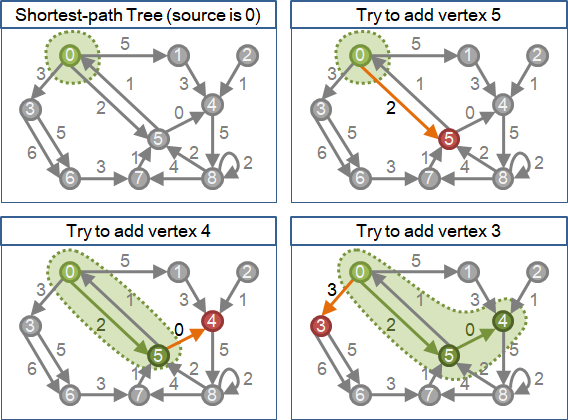
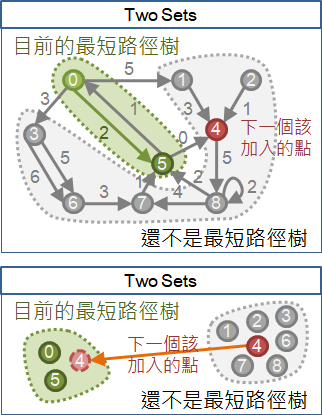
也可以想成是,從目前形成的最短路徑樹之外,屢次找一個離起點最近的點,(連帶著邊)加入到最短路徑樹之中,直到圖上所有點都被加入為止。
整個演算法的過程,可看作是兩個集合此消彼長。不在樹上、離根最近的點,移之。
運用已知的最短路徑,求出其他的最短路徑。循序漸進、保證最佳,這是greedy method的概念。
整個演算法的過程,亦可看作是一種特殊的graph traversal,遍歷順序是優先拜訪離樹根最近的點和邊。
演算法
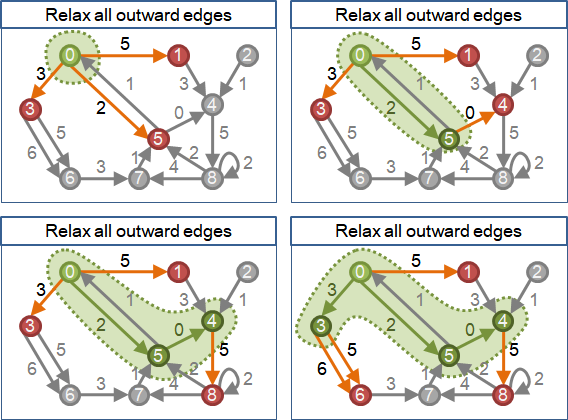
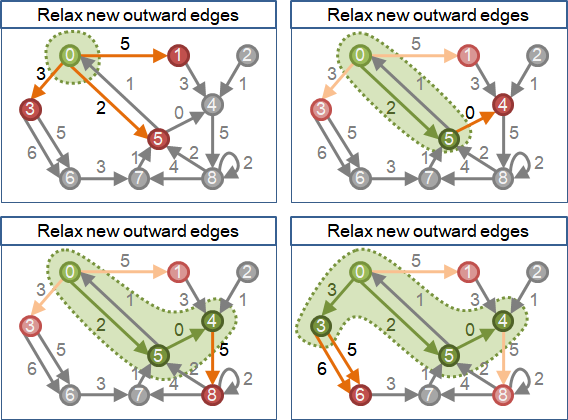
一、將起點加入到最短路徑樹。此時最短路徑樹只有起點。 二、重複下面這件事V-1次,將剩餘所有點加入到最短路徑樹。 甲、尋找一個目前不在最短路徑樹上而且離起點最近的點b。 乙、將b點加入到最短路徑樹。
建立表格記錄最短路徑長度,便容易求得不在樹上、離根最近的點。時間複雜度O(V³)。
令w[a][b]是a點到b點的距離(即是邊的權重)。 令d[a]是起點到a點的最短路徑長度,起點設為零,其他點都是空的。 一、將起點加入到最短路徑樹。此時最短路徑樹只有起點。 二、重複下面這件事V-1次,將剩餘所有點加入到最短路徑樹。 甲、尋找一個目前不在最短路徑樹上而且離起點最近的點: 以窮舉方式, 找一個已在最短路徑樹上的點a,以及一個不在最短路徑樹上的點b, 讓d[a]+w[a][b]最小。 乙、將b點的最短路徑長度存入到d[b]之中。 丙、將b點(連同邊ab)加入到最短路徑樹。
實作
備註
label setting algorithm一共三個階段:圖論元件(點、邊、權重、陣列或串列)、貪心策略(最短路徑末端截去一段還是最短路徑,而且長度更短或相同)、紀錄最短路徑長度(陣列或堆積)。
Dijkstra的1956年論文只有發明貪心策略。那個時代的學者沒有探討圖資料結構、極值資料結構。也沒有探討時間複雜度。古時候沒有這些玩意。
使用不同的資料結構,得到不同的時間複雜度。以下假定圖資料結構是adjacency lists。以下列出各種不同的極值資料結構。
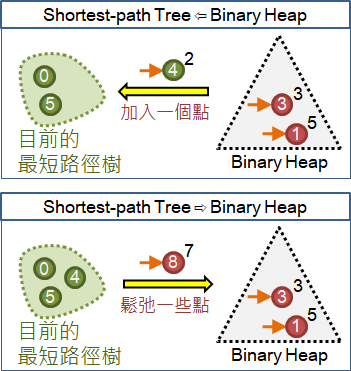
without priority queue 每回合掃描最短路徑樹的所有聯外邊,找出離根最近的點。 O(VE) (vertex-indexed) array 這裡的array是集合資料結構:索引儲存。 抵達各點的最短路徑,儲存於各個元素。索引值是點編號。 每回合掃描陣列,找出離根最近的點。 O(V²) binary heap 每回合以push實作relaxation。 每回合以pop找出離根最近的點。 O(V + ElogV) Fibonacci heap 每回合以decrease key實作relaxation。 每回合以extract min找出離根最近的點。 Fredman–Tarjan algorithm O(E + VlogV) (weight-indexed) array 抵達各點的最短路徑,儲存於各個元素。索引值是最短路徑長度。 每回合繼續掃描陣列,找出離根最近的點。 Dial's algorithm O(V+E+L),L是最長路徑長度。 van Emde Boas tree 同上。 O(V + EloglogL)
第一種array演算法廣為流傳。Dijkstra的1976年書籍提出虛擬碼。知名教科書(例如AHU和CLRS)將此演算法稱作Dijkstra's algorithm,並且分析時間複雜度。