linear approximation🚧
symmetric matrix
「對稱矩陣」。yᵀAx = xᵀAy。
這是仿照dot(y, Ax) = dot(x, Ay)的概念,幾何意義是兩個向量x與y,無論取哪一個實施線性變換,點積仍相同。
positive definite matrix / positive semidefinite matrix
「正定矩陣」。xᵀAx > 0,不討論x = 0。
「半正定矩陣」。xᵀAx ≥ 0,不討論x = 0。
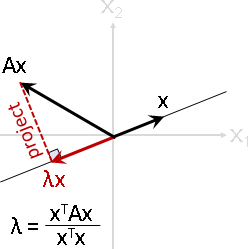
這是仿照dot(x, Ax) > 0的概念,幾何意義是Ax投影到x上面,投影量總是大於0,無論哪種x。換句話說,向量經過線性變換,轉彎幅度少於±90˚,未達半個面。
眼尖的讀者應該注意到了,dot(x, Ax)再除以x的長度平方,就是虛擬特徵值。正定矩陣的虛擬特徵值恆正,於是特徵值恆正。
二次型除以x長度平方,換句話說,向量經過線性變換再投影回去,即是「虛擬特徵值Rayleigh quotient」。
symmetric positive definite matrix
「對稱正定矩陣」。既對稱,又正定。同時具備兩者性質。
原本定義可以改寫成xᵀAx = xᵀMᵀMx = (Mx)ᵀMx = ‖Mx‖² > 0。代數意義是線性變換之後的長度的平方、恆正。
二次型開根號,換句話說,向量經過線性變換的長度,形成「歐氏長度函數Euclidean length function」。
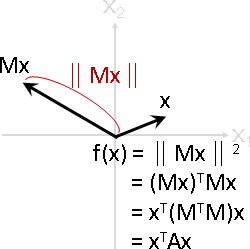
A-orthogonal
「矩陣正交」。yᵀAx = 0。xᵀAy = 0。兩式等價。
Ax與y互相垂直;x經過A變換之後,與y互相垂直。
知名範例:切線速度與加速度互相垂直;一次微分與二次微分互相垂直。
定義y與Ax的內積空間,A必須是對稱正定矩陣。內積空間開根號可以定義距離。
length / distance
l(x) = ‖x‖ = √xᵀx | d(x,y) = ‖x - y‖ = √(x-y)ᵀ(x-y)
lᴍ(x) = ‖Mx‖ | dᴍ(x,y) = ‖Mx - My‖ = ‖M(x - y)‖
= √(Mx)ᵀ(Mx) | = √(M(x-y))ᵀ(M(x-y))
= √xᵀMᵀMx | = √(x-y)ᵀMᵀM(x-y)
= √xᵀAx | = √(x-y)ᵀA(x-y)
長度:元素平方和開根號。自己與自己的點積、再開根號。
線性變換之後的長度:恰是二次型開根號,是對稱半正定矩陣。
距離:相減之後的長度。
線性變換之後的距離:宛如二次型開根號,是對稱半正定矩陣。