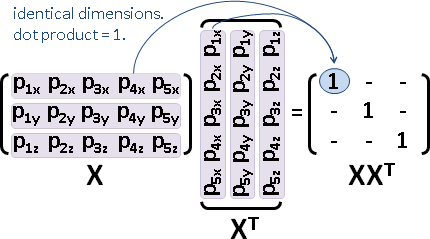
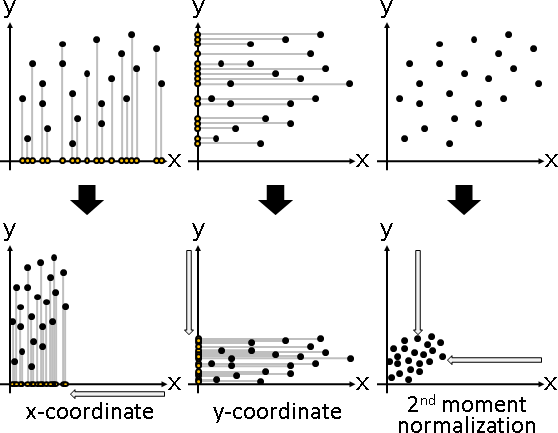
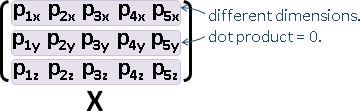
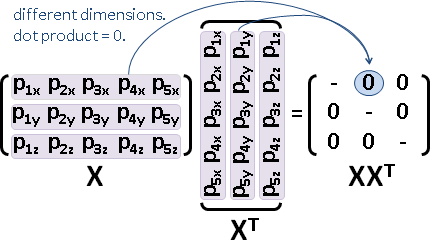
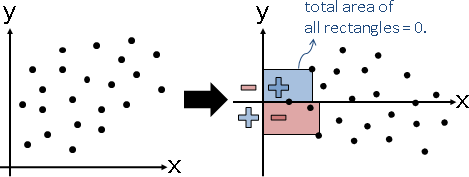
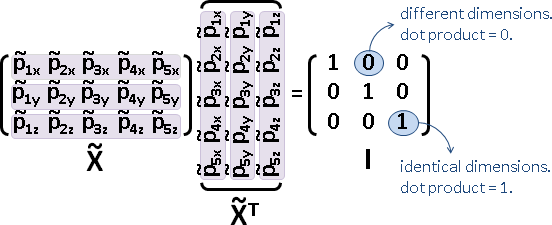
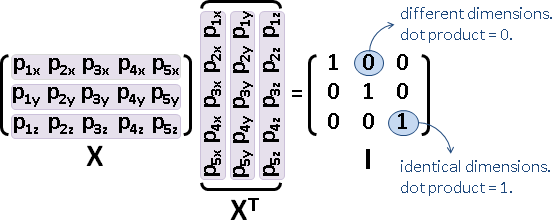
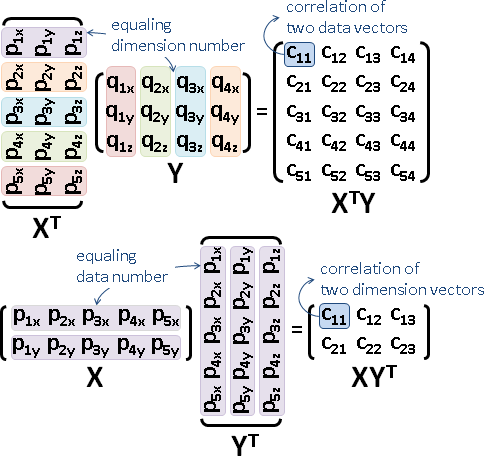
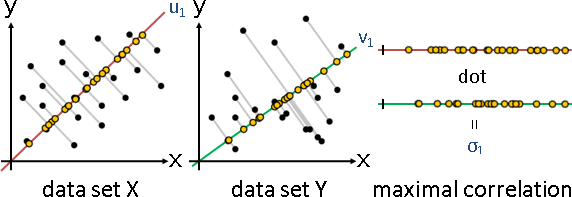
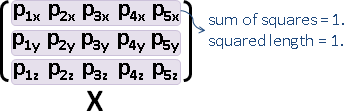centering
centering
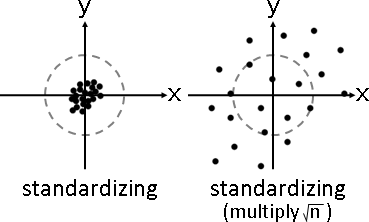
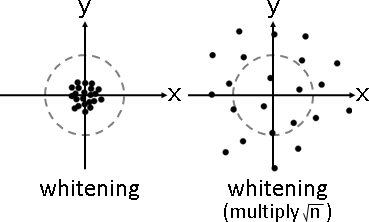
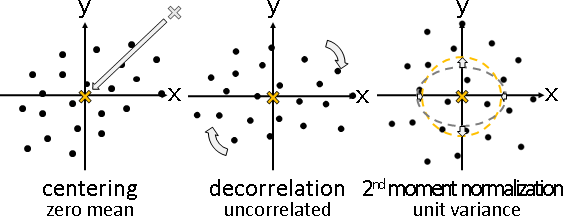
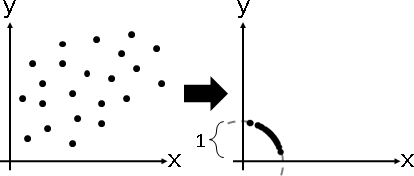
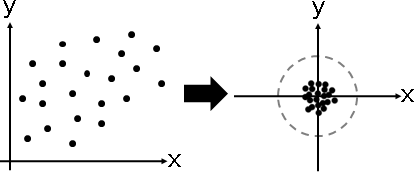
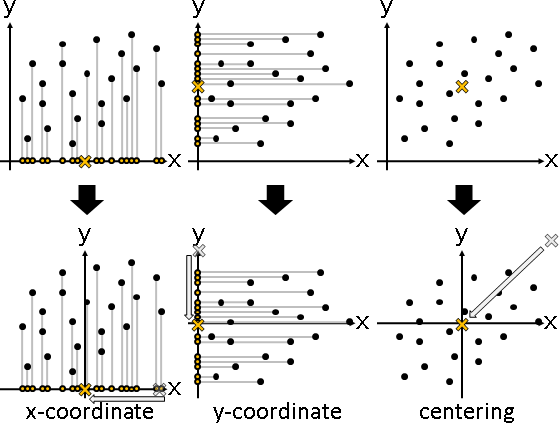
「中心化」。各個維度的總和調成0。數據減去平均數。
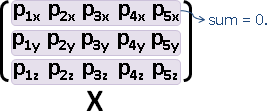
幾何意義:數據中心平移至原點。
all-one matrix
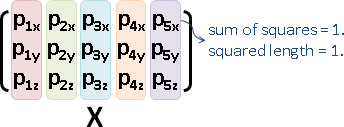
「全一矩陣」。元素全是1。沒有反矩陣。
⎡ 1 1 1 ⎤
𝟏 = ⎢ 1 1 1 ⎥
⎣ 1 1 1 ⎦
用途:總和、平均數、離差(中心化的結果)。
X = {(1,2,3), (4,5,6), (5,0,4), (3,3,3), (7,5,9)}
data: one:
⎡ 1 1 1 1 1 ⎤
⎡ 1 4 5 3 7 ⎤ ⎢ 1 1 1 1 1 ⎥
X = ⎢ 2 5 0 3 5 ⎥ 𝟏 = ⎢ 1 1 1 1 1 ⎥
⎣ 3 6 4 3 9 ⎦ ⎢ 1 1 1 1 1 ⎥
⎣ 1 1 1 1 1 ⎦
sum:
⎡ 20 20 20 20 20 ⎤
Xsum = ⎢ 15 15 15 15 15 ⎥ = X𝟏
⎣ 25 25 25 25 25 ⎦
mean:
⎡ 4 4 4 4 4 ⎤
X̄ = ⎢ 3 3 3 3 3 ⎥ = (X𝟏)/n = X(𝟏/n)
⎣ 5 5 5 5 5 ⎦
deviation:
⎡ 1-4 4-4 5-4 3-4 7-4 ⎤
X̃ = ⎢ 2-3 5-3 0-3 3-3 5-3 ⎥ = X - X(𝟏/n) = X(I - 𝟏/n) = XC
⎣ 3-5 6-5 4-5 3-5 9-5 ⎦
centering matrix
「中心化矩陣」。中心化寫成矩陣形式。沒有反矩陣。
⎡ 1 0 0 ⎤ ⎡ 1 1 1 ⎤ ⎡ ⅔ -⅓ -⅓ ⎤
C = I - 𝟏/n = ⎢ 0 1 0 ⎥ - ⅓ ⎢ 1 1 1 ⎥ = ⎢ -⅓ ⅔ -⅓ ⎥
⎣ 0 0 1 ⎦ ⎣ 1 1 1 ⎦ ⎣ -⅓ -⅓ ⅔ ⎦
中心化矩陣乘在數據矩陣的右邊。
X = {(1,2,3), (4,5,6), (5,0,4), (3,3,3), (7,5,9)}
data: centering:
⎡ ⅔ -⅓ -⅓ -⅓ -⅓ ⎤
⎡ 1 4 5 3 7 ⎤ ⎢ -⅓ ⅔ -⅓ -⅓ -⅓ ⎥
X = ⎢ 2 5 0 3 5 ⎥ C = ⎢ -⅓ -⅓ ⅔ -⅓ -⅓ ⎥
⎣ 3 6 4 3 9 ⎦ ⎢ -⅓ -⅓ -⅓ ⅔ -⅓ ⎥
⎣ -⅓ -⅓ -⅓ -⅓ ⅔ ⎦
deviation:
⎡ ⅔ -⅓ -⅓ -⅓ -⅓ ⎤
⎡ 1 4 5 3 7 ⎤ ⎢ -⅓ ⅔ -⅓ -⅓ -⅓ ⎥
X̃ = ⎢ 2 5 0 3 5 ⎥ ⎢ -⅓ -⅓ ⅔ -⅓ -⅓ ⎥ = XC
⎣ 3 6 4 3 9 ⎦ ⎢ -⅓ -⅓ -⅓ ⅔ -⅓ ⎥
⎣ -⅓ -⅓ -⅓ -⅓ ⅔ ⎦
中心化矩陣可以左乘或右乘,效果不同。
[ 1 4 5 3 7 ]
+
⎡ 1 ⎤ ⎡ 4 ⎤ ⎡ 5 ⎤ ⎡ 3 ⎤ ⎡ 7 ⎤ [ 2 5 0 3 5 ]
⎢ 2 ⎥ + ⎢ 5 ⎥ + ⎢ 0 ⎥ + ⎢ 3 ⎥ + ⎢ 5 ⎥ +
⎣ 3 ⎦ ⎣ 6 ⎦ ⎣ 4 ⎦ ⎣ 3 ⎦ ⎣ 9 ⎦ [ 3 6 4 3 9 ]
X𝟏n×1 𝟏1×dX
(每個橫條分開調整)直條們總和 X𝟏n×n (每個橫條分開調整)直條們平均 X(𝟏n×n/n) (每個橫條分開調整)各直條減去平均 X - X(𝟏/n) = X(I - 𝟏/n) = XC (每個直條分開調整)橫條們總和 𝟏d×dX (每個直條分開調整)橫條們平均 (𝟏d×d/d)X (每個直條分開調整)各橫條減去平均 X - (𝟏/d)X = (I - 𝟏/d)X = CX
中心化寫成矩陣運算,繁文縟節。人類深不見底的惡意。